
Dynamic programing (DP)은 Markov decision process (MDP)인 environment에 대한 완전한 모델 (model)이 주어졌을때 optimal policy를 구해내는 모든 알고리즘을 지칭한다. 기존의 DP algorithm은 완전한 model이 필요하다는 점과, 많은 computing cost가 요구된다는 점에서 활용성이 떨어지지만, reinforcement learning을 이해하는 기초가 된다는 점에서 여전히 이론적으로 중요한 의미를 가진다. DP나 RL의 핵심은 옳바른 policy를 찾기위한 제반의 노력들이 value function을 이용한다는 점이다. 즉, 우리가 아래와 같이 Bellman optimality equation을 만족하는 optimal value function인 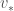
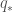


Policy Evaluation
먼저 policy 

만약 environment dynamics를 안다면 맨 아래의 식을 이용하면, 
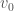

위의 식에서 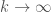
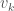


Policy Improvement
우리가 value function을 계산하는 이유는 사용한 policy를 평가하여 보다 나은 policy를 찾아내기 위함이다. 주어진 policy 

위 질문에 대한 판단 기준은 이 값을 


앞서 언급한 개념을 보다 확장해 보자. 모든 state와 모든 action에 대해 적용한다고 하면 아래와 같은 greedy policy 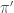

Greedy policy는 자주 언급되는 용어이며, 한단계 앞을 보고 평가한 value function이 가장 큰 action을 선택하는 것을 말한다. 원래의 policy에서 greedy action을 취하는 방법으로 원래 policy를 발전시키는 policy를 찾아내는 것을 policy improvement라고 한다.
Policy Iteration
Value function 


위와 같이 optimal policy를 찾는 과정을 policy iteration이라고 하며, algorithm은 아래와 같다.

Value Iteration
Policy iteration algorithm을 보면 두번째 단계에서 policy evaluation을 위한 iteration이 내부에 존재한다는 것을 알 수 있다. 과연 이단계에서 수렴이 될때 까지 기다리는것이 효율적인지 생각해 보아야 한다. 사실은 그렇지 않다. 위의 방법은 심리적으로 수렴될것이라는 안정감을 주지만, policy를 개선하는데, 반드시 policy evaluation단계의 수렴이 필요하지 않기 때문이다. 사실, policy evaluation단계의 수렴절차를 거치지 않고도 policy iteration의 수렴을 보장할 수 있다. 이 방법의 특별한 case라고 한다면, 모든 state에대해 한번만 value function을 backup sweeping하는 것일 것이다. 이 알고리즘을 value iteration이라고 한다. 그러면, 어떻게 value iteration을 수렴시켜야 할까? policy evaluation 처럼 value iteration도 수렴하기 위해 무한번의 iteration이 필요하나, 현실적으로 update된 값의 변화가 매우 미세하면 종료시키는 방법을 사용한다. 아래는 value iteration의 algorithm이다.

알고리즘을 살펴보면 value iteration방법은 한번씩(one sweep) policy evaluation과 policy improvement를 내재적으로 수행하고 있다고 생각하면 된다.
Asynchronous Dynamic Programming
Dynamic Programing의 단점이라면 MDP 모든 state set에 대해 update sweeping이 필요하다는 점이다. 바둑과 같이 무수한 state가 존재한다면 계산 부하를 감당하기 어려울 것이다. Asynchronous DP algorithm은 state set에 대해 앞서 보인 체계적인 sweeping을 감안하여 설계하지 않는다. 어느 방법이나 순서가 되든지 활용가능한 state를 이용하여 update를 수행하는 방법을 사용한다. 비체계적인 방법으로 update를 수행하므로 어떤 state가 한번 update되는 동안 다른 state는 여러번 update되기도 할것이다. 그러나 결국 올바른 수렴을 하기 위해서는 asynchronous algorithm도 state set의 모든 state에 대해 update를 수행해야 하며, 어떤 state도 계산에 제외되어서는 안된다. 그래도 asynchronous algorithm은 update를 수행하는 state를 선택하는데 있어 보다 융통성이 있다. 물론, 이 방법이 계산부하를 줄일 수 있다는 것을 의미하지는 않으며, 단지 policy 개선을 위해 무의미한 오랜시간동안의 update를 해야하는 제한에서 벗어나게 해준다는 의미이다. 그러므로, 이러한 융통성을 기반으로 보다 수렴이 빠른 backup방안을 강구해 볼 수 있다. 예를 들면 중요도가 작은 state에 대해서는 backup을 빈번히 수행하지 않는 방법도 있으며, optimal behavior와 연관이 없는 state에 대해서는 update에서 완전히 배제하는 방법등을 생각해 볼 수 있다.
Asynchronous algorithm이 주는 또하나의 장점은 policy optimization을 위한 계산과 environment와의 interaction을 순차적으로 수행할 필요가 없다는 개념을 생각하게 해준다. 주어진 MDP에 대해 DP algorithm의 실행과 동시에 agent는 environment를 대상으로 MDP를 경험하는 과정을 밟을 수 있다. 경험된 MDP는 DP algorithm상 계산에 사용되고, DP algorithm상 선택된 action은 environment에 전달되는 과정을 동시에 수행할 수 있는 것이다.
Generalized Policy Iteration
Policy iteration은 두개의 interacting process로 이루어져 있으며, policy evaluation을 통해 현재 사용한 policy에 대한 value function을 구하고, 구해진 value function을 바탕으로 policy를 greedy하게 수정하는 interaction을 수행하게 된다. Policy iteration에서는 이 두가지의 interaction이 상호 수렴상태에서 순환되나, 반드시 그럴 필요가 없다는 점을 이미 언급했다. 반면 value iteration은 극단적으로 policy improvement를 위해 한번만 policy evaluation을 수행한다. Asynchronous에서는 융통성이 더 부여되어 이 두 작없이 상호 엮여서 수행된다.
위와 같은 구체적 방법론을 고려하기 보다는 일반적인 방법론으로서, policy evaluation과 policy improvement의 상호 작용을 수행하는 과정을 일컬어 generalized policy iteration (GPI)라는 용어를 사용한다. 대부분의 RL 학습 방법이 이 범주에 있다. Policy evaluation과 policy iteration을 순차적으로 반복하게되면 상호 수렴하는 과정을 거치는데, 어느 한쪽이라도 수렴이 되지 못하면 다른 한쪽도 수렴되지 못한다. 상호 수렴된 상태는 앞서 말한 Bellman optimality equation을 만족하는 상태가 될것이다. 이러한 과정을 그림으로 표현하면 다음과 같을 것이다.


Efficiency of Dynamic Programming
MDPs를 푸는 여러 방법중에서 DP는 꽤 효율적인 방법으로 알려져 있다. 최악의 경우라도 DP가 해를 찾는데 들이는 시간은 states와 actions space의 polynominal 함수와 비례한다. 이것은 산술적으로 가능한 policy의 수가 
DP가 차원의 저주 (curse of dimensionality) 문제로 응용에 제한이 있다고 생각할 수 있지만, 이것은 DP만의 문제가 아니다. 오히려 direct search나 linear programming법보다 state수가 많은 문제에 더 적합하다. 또한 이 경우 asynchronous DP를 이용하는 방안도 고려할 수 있다.
Note) 본 포스팅은 Sutton과 Barto가 공저한 Reinforcement Learning : An Introduction을 기초로 작성된것이다.

“Dynamic Programming”에 대한 답글 3개