
RL에서 exploration과 exploitation간의 trade-off는 자주 얘기되는 문제이다 보니exploration이 중요한 환경에서 인공지능이 local optimum에 빠져버리는 문제를 해결하기 위한 노력이 많이 있다. 이러한 문제를 해결하기 위해 action 선택에 있어 인센티브를 주는 형태로 새로운 환경으로 유도하는 방법(Curiosity-Driven Learning)을 사용하기도 한다. 보통 새로운 RL 모델이 나오면 다양한 게임환경에서 벤치마크테스트를 수행하는데, 여기서 매우 낮은 점수를 보이는 게임이 대부분 exploitation이 중요한 게임환경이다. Exploration이 중요한 환경이나 환경의 변화가 다양한 경우에 좋은 성능을 보이는 RL 모델이 일반적으로 더 좋은 모델이라고 할 수 있다.
이번 RL 모델은 objective function 자체에 “return”뿐만 아니라 exploration을 권장하도록 “entropy”를 포함시키는 방법을 사용한다. 이 RL 모델(Entropy-regularized RL)의 모티브는 policy가 return을 최대화하도록 action를 선택하되, action선택 확률(policy)이 너무 한쪽으로 치우쳐서 다른 action을 선택할 확률이 적은 경우(낮은 entropy)에 일종의 penalty가 주어지도록 하는 형태로 목적함수를 구성한다. Local optimum에 빠져 헤어나오지 못하는 환경을 방지하기 위함이다. 일반적으로 학습을 오래 시켜도 Bellman Equilibrium 상태가 아니므로 비슷한 return을 가지는 action은 우위를 가리기 어려우므로 entropy에 의해 더 다양한 action 선택을 유도할수 있을 것이다. Objective function은 아래와 같고 

![J(\theta) = \displaystyle\sum_{t=1}^T \mathbb{E}_{(s_t, a_t) \sim \rho_{\pi}} [r(s_t, a_t) + \alpha \mathcal{H}(\pi(.\vert s_t))]](https://s0.wp.com/latex.php?latex=J%28%5Ctheta%29+%3D+%5Cdisplaystyle%5Csum_%7Bt%3D1%7D%5ET+%5Cmathbb%7BE%7D_%7B%28s_t%2C+a_t%29+%5Csim+%5Crho_%7B%5Cpi%7D%7D+%5Br%28s_t%2C+a_t%29+%2B+%5Calpha+%5Cmathcal%7BH%7D%28%5Cpi%28.%5Cvert+s_t%29%29%5D+&bg=ffffff&fg=444444&s=2&c=20201002)
Soft Actor-Critic model은 RL model분류로 보면 off-policy Actor-Critic model이므로, sample efficiency를 위해 replay buffer를 사용하고, value function과 policy function이 필요하다. Entropy function은 ML에서의 entropy의 정의를 그대로 사용하되 softmax 처리된 policy에 대한 entropy를 목적함수에 포함시킨다.
SAC는 Q-learning기법을 사용하므로 action-value function을 Critic에 사용하는데, 이경우 state value function은 필요가 없다. 그러나, SAC는 state value function도 함께 사용한다. 즉, 두가지의 value function을 모두 사용하는데, Q value의 bootstrapping을 위해 action value를 사용하지 않고 state value function을 사용하는 것이 특징이다. 이 state value function은 아래 식에서 보인바와 같이 entropy가 포함되어 있는 것이 특징이다. 이 방법이 안정화에 더 유리하다고 한다.
![Q(s_t, a_t) = r(s_t, a_t) + \gamma \mathbb{E}_{s_{t+1} \sim \rho_{\pi}(s)} [V(s_{t+1})]](https://s0.wp.com/latex.php?latex=Q%28s_t%2C+a_t%29+%3D+r%28s_t%2C+a_t%29+%2B+%5Cgamma+%5Cmathbb%7BE%7D_%7Bs_%7Bt%2B1%7D+%5Csim+%5Crho_%7B%5Cpi%7D%28s%29%7D+%5BV%28s_%7Bt%2B1%7D%29%5D+&bg=ffffff&fg=444444&s=2&c=20201002)
![V(s_t) = \mathbb{E}_{a_t \sim \pi} [Q(s_t, a_t) - \log \pi(s_t, a_t)]](https://s0.wp.com/latex.php?latex=V%28s_t%29+%3D+%5Cmathbb%7BE%7D_%7Ba_t+%5Csim+%5Cpi%7D+%5BQ%28s_t%2C+a_t%29+-+%5Clog+%5Cpi%28s_t%2C+a_t%29%5D+&bg=ffffff&fg=444444&s=2&c=20201002)
정의된 soft action value와 soft value function의 학습을 위한 loss function은 다른 모델과 다르지 않다.
![J_V(\psi) = \mathbb{E}_{s_t \sim \mathcal{D}} [\frac{1}{2} \big(V_\psi(s_t) - \mathbb{E}[Q_w(s_t, a_t) - \log \pi_\theta(a_t \vert s_t)] \big)^2]](https://s0.wp.com/latex.php?latex=J_V%28%5Cpsi%29+%3D+%5Cmathbb%7BE%7D_%7Bs_t+%5Csim+%5Cmathcal%7BD%7D%7D+%5B%5Cfrac%7B1%7D%7B2%7D+%5Cbig%28V_%5Cpsi%28s_t%29+-+%5Cmathbb%7BE%7D%5BQ_w%28s_t%2C+a_t%29+-+%5Clog+%5Cpi_%5Ctheta%28a_t+%5Cvert+s_t%29%5D+%5Cbig%29%5E2%5D+&bg=ffffff&fg=444444&s=2&c=20201002)

![J_Q(w) = \mathbb{E}_{(s_t, a_t) \sim \mathcal{D}} [\frac{1}{2}\big( Q_w(s_t, a_t) - (r(s_t, a_t) + \gamma \mathbb{E}_{s_{t+1} \sim \rho_\pi(s)}[V_{\bar{\psi}}(s_{t+1})]) \big)^2]](https://s0.wp.com/latex.php?latex=J_Q%28w%29+%3D+%5Cmathbb%7BE%7D_%7B%28s_t%2C+a_t%29+%5Csim+%5Cmathcal%7BD%7D%7D+%5B%5Cfrac%7B1%7D%7B2%7D%5Cbig%28+Q_w%28s_t%2C+a_t%29+-+%28r%28s_t%2C+a_t%29+%2B+%5Cgamma+%5Cmathbb%7BE%7D_%7Bs_%7Bt%2B1%7D+%5Csim+%5Crho_%5Cpi%28s%29%7D%5BV_%7B%5Cbar%7B%5Cpsi%7D%7D%28s_%7Bt%2B1%7D%29%5D%29+%5Cbig%29%5E2%5D+&bg=ffffff&fg=444444&s=2&c=20201002)

Policy를 개선하기 위한 방법으로 SAC에서는 우리가 Policy Gradient model에서 일반적으로 사용하는 방법과는 다른 방법을 사용한다. 논문에서는 exponetial Q-function 쪽으로 policy를 update시킨다고 말하고 있다.
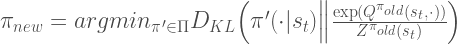
그러므로, policy parameter는 직접 KL-diverence값을 최소화하는 방법으로 학습시킬 수 있다.
![J_{\pi} (\phi) = \mathbb{E}_{s_t \sim \mathcal{D}} \left[ D_{KL} \Big( \pi(\cdot \vert s_t) \Big\| \frac {\exp(Q_\theta (s_t, \cdot))} { Z_\theta (s_t)} \Big) \right]](https://s0.wp.com/latex.php?latex=J_%7B%5Cpi%7D+%28%5Cphi%29+%3D+%5Cmathbb%7BE%7D_%7Bs_t+%5Csim+%5Cmathcal%7BD%7D%7D+%5Cleft%5B+D_%7BKL%7D+%5CBig%28+%5Cpi%28%5Ccdot+%5Cvert+s_t%29+%5CBig%5C%7C+%5Cfrac+%7B%5Cexp%28Q_%5Ctheta+%28s_t%2C+%5Ccdot%29%29%7D+%7B+Z_%5Ctheta+%28s_t%29%7D+%5CBig%29%C2%A0%5Cright%5D%C2%A0&bg=ffffff&fg=444444&s=2&c=20201002)
주목해야 하는 점이 하나있는데, 그것은 policy의 표현방법이다. 위의 식에서 보면 policy는 분포함수 형태로 들어가 있다. 이것이 policy를 위한 Loss function에 포함되어 있기 때문에 stochastic 분포함수에서 deterministic function으로 변형해야 gradient를 구할 수 있다. 이 과정을 reparameterization이라고 하는데, noise 

![J_{\pi} (\phi) = \mathbb{E}_{s_t \sim \mathcal{D}, \epsilon_t \sim \mathcal{N}} [log \pi_{\phi} (f_{\phi} (\epsilon_t ; s_t) |s_t ) - Q_{\theta} (s_t , f_{\phi} (\epsilon_t ; s_t))]](https://s0.wp.com/latex.php?latex=J_%7B%5Cpi%7D+%28%5Cphi%29+%3D+%5Cmathbb%7BE%7D_%7Bs_t+%5Csim+%5Cmathcal%7BD%7D%2C+%5Cepsilon_t+%5Csim+%5Cmathcal%7BN%7D%7D+%5Blog+%5Cpi_%7B%5Cphi%7D+%28f_%7B%5Cphi%7D+%28%5Cepsilon_t+%3B+s_t%29+%7Cs_t+%29+-+Q_%7B%5Ctheta%7D+%28s_t+%2C+f_%7B%5Cphi%7D+%28%5Cepsilon_t+%3B+s_t%29%29%5D+&bg=ffffff&fg=444444&s=2&c=20201002)

SAC에서 특이한 점이 하나 있는데, action value function, Q을 2개 사용한다는 점이다. 실제 Q값은 2종류의 Q값중 작은 값을 선택해서 사용한다. 안정성을 위한것으로 보이나 반드시 2개를 사용할 필요는 없다고 생각한다. 저자는 이 점에 대해서 특히 어려운 task의 경우 training 속도를 유의미하게 빠르게 하는 효과가 있다고 밝혔다. 일종의 clipped Q value인 셈인데, PPO에서 clipping이 안정성에 중요하다고 한것과는 다른 언급이다.

SAC 모델은 의문스러운 부분이 많은 모델이다. 먼저 entropy 가중치 계수
