
작년말 Deepmind사는 이세돌구단을 4:1로 이긴 AlphaGo Lee 버전보다도 더욱더 강력한 버전의 인공지능 바둑 알고리즘을 발표하였다. 이 버전은 인간을 능가함은 물론이고 그동안의 다른 AlphaGo 버전보다도 훨씬 더 강력한 버전이었으며, 이 알고리즘은 자신의 활동영역을 바둑에 그치지 않았다. 이 알고리즘을 Alpha Zero라고 하는데, 바둑(Go) 뿐만 아니라 다른 게임에도 알고리즘 수정없이 모두 적용 가능하기 때문에 알고리즘 이름에 Go를 빼고 부르는 추세이다.
이 알고리즘을 주목해야 하는 이유는 최강의 실력때문이 아니다. 그것은 알고리즘 자체가 매우 훌륭하며, 기존의 알고리즘과 같이 프로 바둑기사의 바둑기보를 이용하여 Supervised Learning을 하는 단계가 필요 없이 self-play 만으로도 훨씬 빠르게 학습하고 훨씬 강력하기 때문이며, 다른 게임에도 알고리즘 수정 없이 그대로 적용 가능하기 때문이다.
Alpha Zero 특징
Alpha Zero의 알고리즘의 가장 큰 차이점이라고 한다면, supervised learning단계가 필요 없다는 점이다. 즉 미리 학습할 기보를 준비하지 않아도 학습이 가능하다. 물론 초기에 이길 수 있는 많은 방법을 학습시켜주지 않기 때문에 초반에는 바둑 실력이 매우 낮고 이에따라 승률이 저조할 수 밖에 없다. 초기 Deepmind사가 강화 학습 알고리즘을 사용하여 Alpha Go를 개발할 때도 이런것을 염두해 두고 프로기사의 기보를 이용하여 supervised learning을 통해 policy network를 학습시키는 방법을 사용하였다. 즉, random self-play부터 시작하는 학습방식으로는 초기에 학습속도가 너무 느려 비효율적이라고 생각할 수 있다(DQN이 이런 특성을 보이는 경향이 있다. 학습 초반에는 매우 학습속도가 느려 S자 모양의 학습곡선을 그리는 경향이 있다). 이러한 판단을 의심하게 만드는 학습곡선을 Alpha Zero paper에서 볼 수있다. 아래 그림에서 Alpha Zero의 학습기간에 따른 바둑실력(ELO rating, Wiki보면 프로9단이 2,940이고 아마추어 1단이 2,100이다)의 증가 추이를 볼 수 있다(출처: Deepmind 블로그) Supervised learning단계를 거치지 않았으므로 초반에는 보잘것 없는 실력이라고 할 수 있으나 ELO rating 증가 속도가 놀랄만 하다. 개인적/상식적(?) 판단에서는 초반 random play로 이렇게 빠른 학습을 할 수 있을 것이라고는 생각하지 못한게 사실이지만, 3일만에 이세돌을 이긴 버전(AlphaGo Lee)을 능가했고, 21일만에 기존 최강인 AlphaGo Master 버전도 능가했으며, 40일 정도에는 ELO rating 5,000을 상회하였다. (사실 이 결과로 볼 때, 학습속도가 매우 빠르기는 하지만 인공지능 연산 전문 프로세싱 유닛 또한 빠르게 발전하였으므로, 계산부하가 낮다고는 할 수 없다. RL은 여전히 인간의 두뇌에 비해 비효율적인 면이 많이 있다.) 프로 9단이 3,000정도이며, AlphaGo master 버전이 4,500정도이니 바둑의 신이라 불릴만 하다. 이 의미는 인간은 더이상 컴퓨터를 상대로 바둑을 이길수 없다는 의미로 해석될 수 있다. 독창적 아이디어로 다시 한번 이길 수 있다면 좋겠지만 그럴 확률은 없는것 같다. 바둑은 모든 State 정보가 공개된 MDP 문제이기 때문에 이미 최강인 컴퓨터는 승부에 변수가 생길 확률이 점차 줄어든다. 이미 훨씬전에 일찌감치 추월해 갔지만 여전히 이 경주에서는 컴퓨터가 점점 더 유리하다.

다른 특징중의 하나는 Q value나 Policy 정보를 학습하는 신경망을 각각 별도로 두지 않고 하나의 network를 이용하여 state의 value와 action의 policy 값을 모두 구한다는 점이다. 이것은 학습의 효율성에서 매우 중요하다. 엄청나게 많은 수의 패러미터를 가진 신경망 두개를 동시에 학습시키는 것은 단순히 2배의 학습시간만 필요하다는 의미가 아니기 때문이다. 두개의 신경망 계산 결과는 서로에게 영향을 미치므로 두 신경망이 어느정도 학습되기 전에는 서로에게 노이즈를 제공하여 학습에 방해가 될 소지가 있을 것이다. 그러므로 초기 AlphaGo처럼 사전에 프로기사 바둑기보를 이용하여 policy network를 학습시키는 과정이 더욱 필요할지 모른다. 반면 Alpha Zero는 하나의 신경망만 학습시키므로 이러한 두 신경망의 상호 간섭에 대한 염려를 어느정도 덜수 있다고 생각된다.
또 다른 특징은 MCTS의 node expansion을 한 후 그 가치를 평가하는 방법에 관한 것이다. 기존 MCTS에서는 새로운 node를 평가하는 방법은 게임에서 승부가 날때까지 가보는 것이다. 최종 승패 결과값을 이용하여 그 node를 오기까지의 과정에 있는 node(state)의 value값을 update하였다. 즉 새로운 node가 발견되면 게임을 끝까지 수행하여(roll out한다고 표현한다) 승패 결과 값을 이용하여 node의 value를 update하므로 매우 많은 simulation을 수행해서 policy를 계속 update 시켜야 한다. 그러므로 경우의 수가 많은 게임에서는 roll out이 필요없는 node를 찾아 내서 더이상 전개시키지 않는 방식으로 효율화를 시키려고 한다. 이것을 pruning(가지치기)라고 한다. 두 상대가 번갈아 수를 두는 게임에서 minimax 개념을 이용하여 가지치기를 하는것이 일례라고 할 수 있다. Alpha Zero에서는 일단 새로운 node를 발견한다고 하더라도 roll out을 곧바로 수행하지 않는다. 그렇지만 그 새로운 node에 대한 평가를 하지 않고 지속적으로 다른 가지를 쳐서 tree search를 수행하기 위해서는 방금 전에 방문한 node를 어떤 식으로든 평가해야 한다. 이것을 신경망을 통해서 수행한다. 즉 기존에 준비된 신경망이 새로운 node를 평가하게 한다.
Alpha Zero 알고리즘
알고리즘의 중심에는 MCTS (Monte Carlo Tree Search)와 Policy Iteration이 있다. 이 두 분야는 이미 본 블로그에 언급이 되어 있는 주제이므로 개념적 차원에서 다시 기술할 필요는 없을것으로 보이나, 세부적인 측면에서는 별도의 언급이 필요하다고 생각한다.
학습을 시키려면 데이터가 필요하므로 먼저 self play를 통해 학습 시킬 데이터를 수집한다. 데이터는 학습시키고자 하는것이 무엇이냐에 따라 무슨 데이터를 수집할것인가가 결정된다. Alpha Zero는 하나의 신경망을 통해 state/action value와 policy를 모두 구해내므로 학습에 필요한 data는 MCTS self play를 통해 (state-policy-value)를 그룹으로 하는 데이터를 모으는 일로부터 시작한다. Self play는 크게 한판의 게임인 episode, episode를 여러번 반복하는 회수인 iteration수까지 정해서 학습시키는데, 하나의 episode에는 (state-policy-value) sample을 여러개 얻을 수 있으므로 학습시키는 train sample의 수는 아래와 같이 가늠할 수 있다.

예를 들어, 10개의 iteration, iteration당 100개의 episode, 한 episode당 평균 50개의 node로 부터 sample을 얻을 수 있다면 50,000개의 sample을 얻을 수 있다. 그런데, self play를 하는 동안 MCTS self play를 하는 세부적 방법론에 있어서 Alpha Zero는 다른 MCTS algorithm과 다른 면이 있다. 사실 sampling을 하는 동안 수준 낮은 play만 계속하는 동안 얻어낸 sample은 인공지능이 학습하기에는 부적절한 sample이다. Self play를 하는동안 학습중인 신경망으로 부터 얻어 낼 수 있는 action probability완 value 값을 최대로 활용하여 다음 action을 선택하는 방식으로 최대한 좋은 play를 많이함으로써 학습에 필요한 좋은 sample들을 모으는 것이다. 하나의 state에서 다음 action을 선택하는척도를 계산하는데 action-value와 함께 사용하는 Upper Confidence Bound식을 살펴보면 action value function , Q(s,a), 뿐만 아니라 신경망으로부터의 얻을 수 있는 probability와 value를 모두 사용하고 있다.

선택된 action으로 node expansion 및 신경망 예측 value를 이용하여 action- value를 update하는 과정을 반복하면서 계속해서 (state-policy-unkown value)를 sampling하고 이 과정중 게임이 끝나 최종 value(승/패)값을 얻으면, unknown value를 최종 value로 update한다. 이 과정을 논문에서는 아래와 같은 그림으로 표현하고 있다.

이 sample을 이용해서 복수의 epoch 회수로 신경망 학습을 시키는 과정을 지속하면 우리가 원하는 policy를 계산해 내는 신경망을 학습 시킬 수 있다.MCTS에 의한 self play하는 동안 (state-policy-unknown value)로 sample을 계속 저장하고 최종 승패값(z)이 결정되면 이 값으로 저장된 sample의 unknown value값을 update한다. 이렇게 최종준비된 sample을 이용하여 policy와 value를 하나의 신경망을 통해 예측된 값과 매치시키도록 학습시키는 과정이다. 학습의 과정을 잘 요약한 그림이 논문에 있다.(아래)
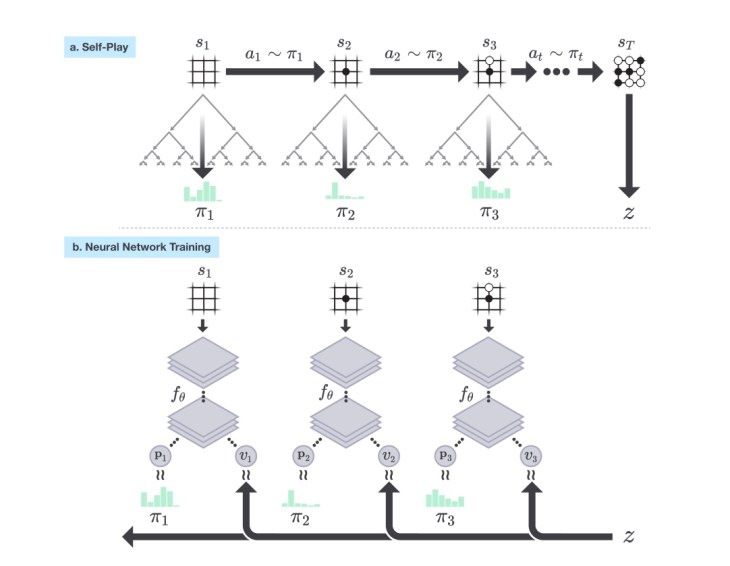 이렇게 학습된 신경망이 지속적으로 유의미한 개선을 하고 있는지 점검하는 단계가 있어야 policy improvement를 통한 policy iteration을 계속할 수 있는데, 점검하는 방법은 기존의 신경망을 사용하는 player와 새로 학습한 신경망을 사용하는 player를 대결시켜 의미있는 승률로 이기게 되면, 기존의 신경망을 대체한다. 이러한 과정을 지속하면 종국에는 매우 강력한 실력을 보이는 신경망이 탄생하게 된다. 이처럼 policy iteration과정을 거쳐서 ELO rating이 상승하는 과정을 보여주는 그림이 위에 소개한 그림이다.
이렇게 학습된 신경망이 지속적으로 유의미한 개선을 하고 있는지 점검하는 단계가 있어야 policy improvement를 통한 policy iteration을 계속할 수 있는데, 점검하는 방법은 기존의 신경망을 사용하는 player와 새로 학습한 신경망을 사용하는 player를 대결시켜 의미있는 승률로 이기게 되면, 기존의 신경망을 대체한다. 이러한 과정을 지속하면 종국에는 매우 강력한 실력을 보이는 신경망이 탄생하게 된다. 이처럼 policy iteration과정을 거쳐서 ELO rating이 상승하는 과정을 보여주는 그림이 위에 소개한 그림이다.
아래 그림은 Deepmind사의 블로그에서 얻은 것으로, 학습이 진행됨에 따라 바둑 두는 모양새가 발전하는 것을 보여준다(바둑을 잘 두는 사람은 잘 알아 보겠지만…..3시간 학습결과로 보여주는 바둑 포석의 모양새는 바둑을 처음 배우는 아마추어와 비슷한것이 더 흥미롭게 보인다. 더 효율적인 공간에 돌을 놓는것이 아니라 상대방의 돌을 따먹거나 자신의 영역을 빨리 만들려고 하는 것처럼 보이지 않는가?)

AlphaGo Zero 신경망 구조
AlphaGo Zero의 state는 바둑판의 흑돌과 백돌의 배치이다. 이 배치를 state 형태로 표현하는 방법은 여러가지가 있을 수 있다. 일례로, 바둑판의 state정보는 19 x 19의 줄에 어느 돌이 놓여 있는지 아니면 빈 공간인지를 표시하는 상태변수(예를 들어, 1/0/-1)가 입력된 2 dimensional data로 표현하는 방법이 있을 수 있다. 그러나, 논문을 살펴보면 AlphaGo Zero에 사용된 바둑판 state 정보는 흑돌과 백돌의 각각의 관점에서 1/0으로 상태를 표현하는 1 set을 7번의 착수를 두는 동안의 정보를 묶는 방식으로 state를 표기하였다고 밝혔다. 아무래도 바둑대국의 sequence 정보를 포함하고 싶은 의도일 것이다. 의 신경망을 학습시키는 과정은 다른 학습과 크게 다를바는 없다. 신경망의 구조도 image classification에 사용하는 몇십층의 layer를 사용하는 것도 아니다. 이래도 image classification이나 object detection에 사용되는 입력정보에 비하면 매우 크기가 작은 데이터이다. 2D형태의 정보(바둑판 교참점들의 상태들)이고 교차점의 인접한 돌들이 어떤 형태로든 게임의 승부에 영향을 미친다면, 이런 정보형태에 가장 잘 어울리는 신경망 architecture는 2차원 convolution일것이다. 논문에서는 입력처리에 하나의 convolutional block과 19 또는 39개의 residual block으로 이루어져 있다고 밝혔다. ResNet에 사용되는 residual block은 이미지 처리에 매우 효율적이라고 알려져 있다. 단, pooling을 사용하면 안될것이다. Filter size는 256이 사용되었지만, convolution kernel size는 이미지 처리에 사용하는 kernel size를 그대로 사용해도 될까라는 의문이 든다. Stride는 1을 사용하는 것이 좋을 것이다. 논문에서는 이미지 처리에 주로 사용하는 hyper parameter를 대부분 차용하였다고 밝혔다.
Toy(오목게임) 테스트 결과
아무래도 19줄짜리 바둑은 그대로 적용하기에는 내 컴퓨터에게 무리일게 분명하다. 상대적으로 오목과 같은 게임이 평가하기에는 적당하다고 판단해서, 15 x 15 바둑판(오목의 국제적 규격)에 오목 rule이 적용된 game에 Alpha Zero 알고리즘(Github에서 비슷하게 재현된 source를 쉽게 찾아 볼 수 있다)을 이용해 학습시켜 보았다. 결과는 불행히도 개인 컴퓨터(사용된 컴퓨터는 게임컴퓨터 사양 정도의 데스크탑 컴퓨터이다) 수준으로는 학습에 필요한 계산부하를(Branching Factor와 Depth를 고려하면)를 감당하기에 계산 시간이 너무 오래 걸린다. 참고로 Alpha Zero 학습시킬때 64개의 GPU와 19개의 CPU parameter server를 사용하고, 한번의 episode에 1,600번의 MCTS simulation을 수행하고, 한 iteration당 25,000번의 episode를 수행하였다고 한다.
대안으로 11줄짜리 바둑판에 오목(5 in a row)을 두는 게임을 학습시키는 것을 시도하였다. 이번 테스트에서 몇가지 고려한 사항을 아래에 간단히 요약하였으나, 실제 실행 및 검토하는데는 적지 않은 노력이 필요하다.
- 다양한 hyperparameter 값을 사용한 학습 과정 비교. 초기 학습과정을 살펴보면 어느정도 기본적인 스킬 학습(단수를 막는 정도)에서 큰 진전이 없는 경우가 있었다. 이것은 MCTS simulation의 수가 어느 정도 커야 해결된다. Branching factor가 큰 시합에서는 MCTS simulation의 수가 크지 않으면 local optimum에 빠져들어서 비교적 초보적인 수만 반복하려는 경향이 있다.
- Train sample의 수는 클수록 좋다. 너무 sample의 수가 적으면, 신경망이 특정 패턴만 학습하는 경향이 있다. 그러나 낮은 실력일때 얻은 train sample 은 학습이 진행되면서 지속적으로 선입선출식으로 새로운 학습데이터로 대체해야 한다. 특히 반드시 action probability에 noise를 두어 다양한 패턴의 게임을 하도록 유도해야 한다. 다양한 수를 exploration하기 위해 AlphaGo Zero 논문에서는 self-play시 Dirichlet noise를 action prob.에 추가하였다. 이와 같이 이 noise를 추가하면 보다 다양한 경우의 돌의 전개를 경험해 볼 수 있다.
- 신경망의 구조도 Bayesian 관점에서는 일종의 hyperparameter이지만, 중요하므로 별도로 언급할 필요가 있다. Alpha Zero에서는 ResNet을 사용하였다고 하였지만, CNN의 다양한 형태도 시도할 필요가 있다. 이번 실험에서는 2가지 구조를 시도해 보았지만, 충분한 수의 weights를 가진다면 유의미한 차이는 없었으나, 다양한 시도를 해본것이 아니므로 속단할 수는 없다.
- MCTS simulation은 시간이 오래 걸리는 작업이다. 이 작업은 내 컴퓨터에서는 시간이 너무 오래 걸리므로 학습속도를 단축시켜보려고 multithreading 또는 multiprocessing을 시도해보고 싶은 곳이었다. Python에서는 GIL로 인한 제약으로 multithreading보다는 multiprocessing이 효과적이라고 하며, 여러 시도를 하였지만 실패하였고, 이 부분은 앞으로의 과제로 남아있다.
학습시키는 과정에서 중간 중간 학습된 신경망을 사용하여 오목을 어느 정도 수준으로 두는지 확인하였다. RL은 인간이 학습하는 패턴과는 좀 다른 모습을 보였다. 우리가 이기기 위해 가장 초보적인 수단인 돌을 3개 연속으로 놓는 가장 기본적인 수에 대한 대응도 제대로 하지 못한다. 반대로, 이보다 더 복잡한 패턴으로 이기기도 한다.(물론 나를 이긴것이 아니고, 학습된 신경망끼리의 시합이다.) RL의 학습과정이 인간과 같을 수는 없지만 아무래도 인간이 더 효율적인것은 사실이다. RL은 게임의 basic concept를 학습하는 과정이 없는 학습이므로 아무래도 비효율적이다. 일단 오목을 두는 착점이 인간이 두는 지점과는 좀 다른 양상이다. 아무래도 초반 학습에 사용한 sample의 영향과 AlphaGo 초기 버전과 같이 인간의 대국을 이용하여 먼저 학습하지 않고, 순전히 self play로부터 출발하니 많이 다른 양상을 보이는 것으로 판단하고 있다. 아래에 인공지능끼리 두는 게임의 한 예를 구경해 볼수 있다. 아무런 금지수(3-3과 같은) rule이 없는 대국이며, 오목에 대한 어떠한 가이드도 코드에 반영하지 않았다. 게임의 수준은 그다지 높은것은 아니라고 생각되며, 더 학습을 시키게 되면 수준이 높아 질지, 아니면 현재의 상태가 local optimum상태여서 더 이상 수준이 높아지지 못할지 판단하기 어렵다.
Alpha Zero를 보며 드는 생각
인공지능이라면, 전문가들 사이에서도 두가지 관점이 공존하는게 사실이다. 인공지능은 구조적으로 인간의 두뇌를 흉내낸 신경망을 이용하여 weights라는 수많은 숫자를 통해 “기억”하는 것이라고 보는 관점으로 인공지능은 확장된 함수형태 기억장치일뿐이라는 관점이다. 또다른 관점은 우리가 “이해”할수 있는 능력과 “추론” 또는 “창조” 할 수 있는 능력의 핵심에는 두뇌가 있으며, 인공지능이 그 두뇌와 같은 능력을 충분히 가질수 있다는 관점이다(최근 Deepmind사가 nature지에 발표한 grid cell에 관한 논문은 이러한 관점의 시도중 하나로 생각하고 있다). 인간은 수백만년동안 유전자에 기록된 능력과 경험이나 학습으로부터 필요한 지혜를 얻는 측면에서 효율이 매우 높은 두뇌를 모두 활용할줄 아는 매우 탁월한 생물이지만, 이해 및 추론 능력이 떨어진다 손 치더라도 현재의 인공지능처럼 데이터 물량공세나 빠른 계산속도를 이용하는 능력에 당하기는 어렵다는 것이 나의 생각이다(이제 Alpha Zero는 데이터도 필요 없다). 이와 더불어, AlphaGo의 바둑이나 이번 테스트하는 과정에서 드는 생각은, 우리가 학습한 지식은 불완전하고 bias를 포함하고 있으며, 완전히 처음부터 수많은 시도를 통해 배우는 인공지능이 더 폭넓고 완성도가 높은 지식을 축적할수 있다는 생각이다. 그러나, 이번 현재수준의 인공지능은 효율면에서는 매우 뒤떨어 지며, 인간과 같은 폭넓은 지적 능력을 갖추기에는 매우 많은 시간이 필요할것이다.
