이번 포스팅에서는 NIPS 2016에서 Best Paper Award를 받은 paper에서 발표한 VIN(value-iteration network)를 소개하고자 한다. 그동안 이 블로그에서 RL algorithm을 많이 소개했는데, 이 paper 또한 RL과 직접적인 관계가 있으므로 관심있게 내용을 살펴 보았으며, 이번 포스팅에서 논문을 중심으로 하되 설명을 곁들여 소개하고자 한다.
VIN 설계에 들어가기 전에 먼저 이와 관련한 기본적 개념부터 살펴보아야 한다. 먼저 value iteration의 개념은 과거에 포스팅한 Dynamic Programming에 기술되어 있으니 참고하기 바란다. DQN과 같이, observation/state으로 부터 action-value function을 통해 policy를 곧바로 알아낼 수 있는 것은 본질적으로 reactive하다고 한다. CNN을 사용하여 reactive policy를 구축한다는 개념자체는 VIN에서도 그대로 유지하고 있다.
Explicit reactive policy를 구축하되 한가지 더 고려해야 할 점이 있다. DQN이 다양한 Atari game에 본질적 수정없이 모두 적용가능하다고 해서, grid-world navigation task에서 학습된 상황(environment)과 다른 장애물과 target이 배치된 새로운 grid-world에서는 그다지 만족스럽지 못한 결과를 보인다. CNN 기반 network가 목표지향형 행동특성(goal-directed nature of behavior)을 이해하지 못하기 때문이다. 이것이 의미하는 바는, reactive policy가 새로운 task 수행에 필요한 planning하고는 다르다는 점을 의미한다고 할 수 있다.
그러므로, VIN 개발자의 의도는 분명해진다. Panning을 학습할 수 있는 explicit NN-based reactive policy를 만드는 것이다. 이것을 value-iteration network이라 하고 미분가능한 ‘planning program’을 NN에 임베디드(embedded) 하였다. Planning 자체를 학습함으로써 solving mechanism을 일반화 하려는 것이다.
Background (Reinforcement Learning and Imitation Learning)
MDP에서 state space가 매우 큰 경우, continuous space인 경우, 또는 MDP transition이나 reward를 모르는 경우등에는 planning algorithm 사용이 어렵다. 이런 경우에는 expert의 action을 흉내내면서 배우는 IL(Imitation Learning)이나 reinforcement learning을 통해 policy를 학습해야 한다. RL과 IL은 서로 algorithm측면에서는 다르지만 학습의 결과물인 policy를 표현하는 방법측면에서는 서로 비슷하다고 할 수 있다. 다른 한편으론, 대부분의 알고리즘은 policy를 독립적 형태로(explicit) 표현하기 보다는, gradient descent방법에 의한 weights update를 위해 미분가능하다는 점을 더 중요하게 여긴다.
State  의 observation을
의 observation을  라고 하고, policy를
라고 하고, policy를  라고 한다면, IL에서는 expert에 의해서 state observation과 이때 최적의 action을 쌍으로하는 N개의 dataset
라고 한다면, IL에서는 expert에 의해서 state observation과 이때 최적의 action을 쌍으로하는 N개의 dataset  을 생성하게 된다. 이렇게 되면 policy를 학습한다는 것은 supervised learning이 수행된다는 것을 의미한다. 반면에, RL에서는 optimal action을 사전에 알 수가 없으므로 그동안 언급된 많은 RL 알고리즘을 사용하여 action을 수행함에 따라 environment가 주는 reward와 state transition을 이용하여 최적 policy를 알아내는 방법을 사용한다.
을 생성하게 된다. 이렇게 되면 policy를 학습한다는 것은 supervised learning이 수행된다는 것을 의미한다. 반면에, RL에서는 optimal action을 사전에 알 수가 없으므로 그동안 언급된 많은 RL 알고리즘을 사용하여 action을 수행함에 따라 environment가 주는 reward와 state transition을 이용하여 최적 policy를 알아내는 방법을 사용한다.
Value Iteration Network Model
VIN의 핵심 아이디어는 policy를 표현하기 위해 별도의 explicit planning module을 포함(embedded)시켰다는 것이다. 저자가 밝힌 이 아이디어의 모티브는 많은 tasks에서(예를 들어, path planning) 그 도메인의 모델에 planning을 포함하는 것이 자연스러운 해결책이라는 점이다.
Policy  를 설계하고자 하는 MDP를
를 설계하고자 하는 MDP를  이라고 하자. 이 의 최적 policy에 대한 유용한 정보를 포함하고 있는 미지의 MDP
이라고 하자. 이 의 최적 policy에 대한 유용한 정보를 포함하고 있는 미지의 MDP  의 optimal plan이 있다고 가정해 보자. 아이디어는 을 배우고 풀수 있는 능력(ability to learn and solve) 을 가진 policy를 만든 후, 에 대한 해(solution)를 policy 의 한 요소(element)로 첨가하는것이다.
의 optimal plan이 있다고 가정해 보자. 아이디어는 을 배우고 풀수 있는 능력(ability to learn and solve) 을 가진 policy를 만든 후, 에 대한 해(solution)를 policy 의 한 요소(element)로 첨가하는것이다.
MDP 에서 state, action, reward, transition을 각각  이라고 표기한다. MDP 과의 연결고리를 만들기 위해,
이라고 표기한다. MDP 과의 연결고리를 만들기 위해,  과
과  는 에서의 observation에 의존한다고 가정하고(
는 에서의 observation에 의존한다고 가정하고( ,
,  ), 나중에 policy learning과정의 하나로 function
), 나중에 policy learning과정의 하나로 function  과
과  를 배우는 것이다.
를 배우는 것이다.
이해를 돕기위해 예를 들어보자. Grid-world domain에서 는 true grid-world 과 같은 state 및 action space를 가진다고 가정할 수 있다. Reward function 은 domain의 이미지의 목표에서는 높은 reward를, 장애물 근처에서는 negative reward를 가지도록 매핑할 수 있다. 반면에,  는 observation에 의존하지 않는 grid-world에서 사용할 수 있는 deterministic movements를 새겨(encode) 넣을수 있다. 비록 이러한 rewards나 transitions이 실제와 다르지만, 에서의 optimal plan은 에서와 마찬가지로 장애물을 피하면서 목표에 도달하는 trajectory를 여전히 따르게 될것이다.
는 observation에 의존하지 않는 grid-world에서 사용할 수 있는 deterministic movements를 새겨(encode) 넣을수 있다. 비록 이러한 rewards나 transitions이 실제와 다르지만, 에서의 optimal plan은 에서와 마찬가지로 장애물을 피하면서 목표에 도달하는 trajectory를 여전히 따르게 될것이다.
일단 MDP 가 정해지면, 어떠한 standard planning algorithm도 value function  를 구하는데 이용될 수 있다. 일단, planning 결과를 담고 있는를 신경망 policy 에 어떻게 이용할 수 있을지 생각해 보자. 저자의 approach는 두가지 발견에 근거하고 있다. 첫째는 vector가에서의 optimal plan에 관한 모든 정보을 지니고 있다는 것이다. 그러므로, vector 를 policy 에 additional feature로 추가하는것만으로도 에서의 optimal plan 정보을 추출하는데 충분하다는 점이다.
를 구하는데 이용될 수 있다. 일단, planning 결과를 담고 있는를 신경망 policy 에 어떻게 이용할 수 있을지 생각해 보자. 저자의 approach는 두가지 발견에 근거하고 있다. 첫째는 vector가에서의 optimal plan에 관한 모든 정보을 지니고 있다는 것이다. 그러므로, vector 를 policy 에 additional feature로 추가하는것만으로도 에서의 optimal plan 정보을 추출하는데 충분하다는 점이다.
그러나, 의 다른 특성은 state  에서 optimal decision
에서 optimal decision  는 의 subset에만 의존한다는 점이다(왜냐하면,
는 의 subset에만 의존한다는 점이다(왜냐하면,  ). 그러므로, MDP가 grid-world예와 같이 local connectivity structure를 가진다면,
). 그러므로, MDP가 grid-world예와 같이 local connectivity structure를 가진다면,  조건의 state는
조건의 state는  의 작은 subset으로 생각할 수 있다. Label prediction(action)을 위해 input feature(value function)의 subset만 관여한다는 관점을, 신경망에서는 attention이라는 용어를 사용한다. Attention은 학습중에 유효 네트워크 패러미터수를 줄이는 방법으로 학습성능을 증대시키는 것으로 알려져 있다. 그러므로 VIN의 두번째 특징은 attention modulated value
의 작은 subset으로 생각할 수 있다. Label prediction(action)을 위해 input feature(value function)의 subset만 관여한다는 관점을, 신경망에서는 attention이라는 용어를 사용한다. Attention은 학습중에 유효 네트워크 패러미터수를 줄이는 방법으로 학습성능을 증대시키는 것으로 알려져 있다. 그러므로 VIN의 두번째 특징은 attention modulated value  의 vector를 출력하는 attention module이다. 마지막으로, vector
의 vector를 출력하는 attention module이다. 마지막으로, vector  가 additional feature로서 reactive policy
가 additional feature로서 reactive policy  에 추가된다. 전체 네트워크 구조를 아래 그림(왼쪽)으로 나타내었다.
에 추가된다. 전체 네트워크 구조를 아래 그림(왼쪽)으로 나타내었다.
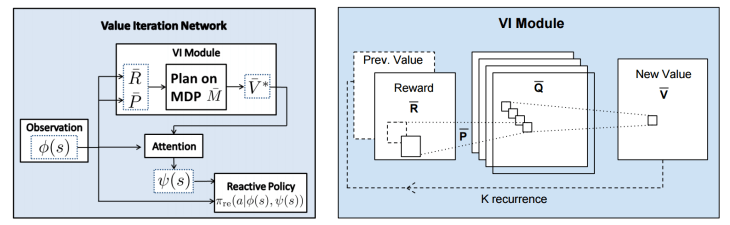
 가 policy의 모든 parameter를 나타낸다고 하자. 즉,
가 policy의 모든 parameter를 나타낸다고 하자. 즉,  의 parameter라고 가정하자. 그리고, 는 사실 의 함수라는 사실에 주목하자. 그러므로, policy는 standard policy의 형태와 같이
의 parameter라고 가정하자. 그리고, 는 사실 의 함수라는 사실에 주목하자. 그러므로, policy는 standard policy의 형태와 같이  와 같은 형태로 쓸수 있다. 이러한 함수를 통해 back-propagation을 할수있게되면, 일반적인 RL이나 IL 알고리즘을 사용하여 policy 학습이 가능하게 된다. 이 논문에서는 approximate VI algorithm을 CNN의 특수한 형태로 봄으로써, planning module을 신경망과 같이 back-propagation을 사용하여 전체 policy를 처음부터 끝까지(end-to-end) 학습시킬 수 있게 만들었다.
와 같은 형태로 쓸수 있다. 이러한 함수를 통해 back-propagation을 할수있게되면, 일반적인 RL이나 IL 알고리즘을 사용하여 policy 학습이 가능하게 된다. 이 논문에서는 approximate VI algorithm을 CNN의 특수한 형태로 봄으로써, planning module을 신경망과 같이 back-propagation을 사용하여 전체 policy를 처음부터 끝까지(end-to-end) 학습시킬 수 있게 만들었다.
VI Module
VI module은 미분가능한 planning계산을 가능하게 해주는 신경망이다. VI에서의 각 iteration은 이전의 value function  과 reward function
과 reward function  을 convolution layer와 max-pooling layer를 통해 전달하는 것으로 볼 수 있다는 점이 저자의 관점이다. 비유로서 설명하자면, convolution layer의 각 channel은 특정 action의 Q-function에 대응한다고 생각할 수 있고, convolution kernel weight는 discounted transition probability에 대응한다고 생각할 수 있다. 그러므로 convolution layer를 되풀이하듯 K번 적용함으로써, VI를 K번 iteration한것이랑 같은 효과를 보는 것이다. 이 개념이 위 그림의 오른쪽에 표현되어 있다. (개인적인 생각에 한마디로 표현하자면 brilliant!)
을 convolution layer와 max-pooling layer를 통해 전달하는 것으로 볼 수 있다는 점이 저자의 관점이다. 비유로서 설명하자면, convolution layer의 각 channel은 특정 action의 Q-function에 대응한다고 생각할 수 있고, convolution kernel weight는 discounted transition probability에 대응한다고 생각할 수 있다. 그러므로 convolution layer를 되풀이하듯 K번 적용함으로써, VI를 K번 iteration한것이랑 같은 효과를 보는 것이다. 이 개념이 위 그림의 오른쪽에 표현되어 있다. (개인적인 생각에 한마디로 표현하자면 brilliant!)
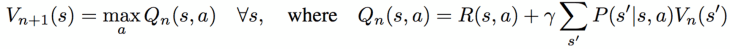
VI module의 입력은 dimension  을 가진 ‘reward image‘ 이며, CNN formulation을 따라서 state space 는 2-dimensional grid에 매핑된다. 그러나, 이러한 approach는 일반적인 discrete space에도 적용 가능하다. Reward는 convolutional layer
을 가진 ‘reward image‘ 이며, CNN formulation을 따라서 state space 는 2-dimensional grid에 매핑된다. 그러나, 이러한 approach는 일반적인 discrete space에도 적용 가능하다. Reward는 convolutional layer  로 입력되는데, 이 convolutional layer는 action
로 입력되는데, 이 convolutional layer는 action  channel과 linear activation function (
channel과 linear activation function ( )로 구성되어 있다. 이 layer에서의 각 channel은 특정 action
)로 구성되어 있다. 이 layer에서의 각 channel은 특정 action  의
의  에 해당한다. 이 layer는 다음으로 action channel을 따라 max-pooling을 거침으로써, 다음번 iteration value function layer
에 해당한다. 이 layer는 다음으로 action channel을 따라 max-pooling을 거침으로써, 다음번 iteration value function layer  (
( )를 생산하게 된다. Next-iteration value function 는 다음으로 reward 와 stacking되어 convolutional layer와 max-pooling layer에 K번 되풀이 전달되는 형식으로 value iteration을 K번 수행하게 되는 것이다.
)를 생산하게 된다. Next-iteration value function 는 다음으로 reward 와 stacking되어 convolutional layer와 max-pooling layer에 K번 되풀이 전달되는 형식으로 value iteration을 K번 수행하게 되는 것이다.
Value Iteration Networks
VIN은 planning-based policy에 기반하고 있으며, VI module을 planning algorithm으로 사용한다. VIN을 실현하기 위해서는 planning module을 위한 state()와 action space()를 정의하고, reward function과 transition function, 그리고 attention function을 정의해야 한다. 이것을 VIN design이라고 말한다. Task에 따라서 이 디자인이 간단명료할수도, 생각을 좀 더 해야 할필요도 있을 것이다. 그러나 중요한 점은 reward, transition, attention이 parametric function을 사용하여 정의될 수 있고, policy와 함께 학습될 수 있다는 점이다.
Experiment in grid-world domain
저자는 알고리즘 테스트 목적으로 사용한 첫번째 task는 무작위로 장애물을 배치한 grid-world이다. Observation은 agent의 위치, 목표의 위치, 그리고 맵이미지이다. 아래는 16 x 16 크기의 grid-world의 예시이다. 이러한 몇개의 domain에서 학습한 optimal policy로부터 VIN policy가 이전에 보지못한 새로운 task를 해결하기 위해 필요한 planning연산을 학습하는것을 목표로 한다.

저자는 이 도메인에서 VIN을 설계를 다음과 같이 했다고 밝혔다. 먼저 planning MDP 는 grid-world이다. Reward function 은 CNN으로서 이미지 입력을 reward map으로 맵핑하는 역할을 한다. 그러므로, 은 기본적으로 장애물, 비장애물, 목표지점을 구분할 수 있어야 하며, 각각에 적당한 reward를 부여할 수 있어야 한다. Transition 는 VI block에 3 x 3 convolution kernel로 구성되어 있다. Recurrence number K는 정보가 goal state에서 다른 state로 전달될수 있도록 grid-world size에 비례하여 선택된다. Attention module을 위해서는 VI block에 있는 현재 state의 Q value를 그대로 사용하였다(즉,  ). 마지막 reactive policy는 를 action에 대한 확률로 맵핑하는 fully-connected layer를 사용하였다. 자세한 내용은 페이퍼에서 확인할 수 있다.
). 마지막 reactive policy는 를 action에 대한 확률로 맵핑하는 fully-connected layer를 사용하였다. 자세한 내용은 페이퍼에서 확인할 수 있다.
이 도메인과 관련하여 저자가 사용한 trick하나를 소개하고자 한다. Policy가 어떤 특정 맵을 기억하여 최적화되는것을 막기위해 각 에피소드마다 무작위로 맵을 선택하였다고 한다. 그러나, 어떤 맵은 너무 어려워서 목표에 도달하기 어려울 수 있다. 그러므로, 학습초기에는 쉬운 맵으로부터 시작하여 점차 어려운 맵을 학습해 나가도록 하는게 좋다. 이 아이디어를 curriculum training이라고 한다.
5000 random grid-world를 대상으로 얻어낸 결과를 아래 나타내었다. 결론은 VIN이 다른 두개의 reference model보다 더 좋은 성능을 보인다.

각 algorithm의 구조를 간략히 정리하면 다음과 같다.
(VIN)
- Observation
 : image map with 2 channel (one for image itself, the other for reward(1 for goal, 0 for others)
: image map with 2 channel (one for image itself, the other for reward(1 for goal, 0 for others)
- Reward : 이미지와 같은 dimension, reward mapping CNN with input [(150 3×3 filter), (1 3×3 filter) output ]
- Transition : [(10 3x3 filter)]
- Attention :
 1대1 mapping
1대1 mapping 
- Reactive policy : fully connected softmax output layer

(CNN)
- TRPO(Trust Region Policy Optimization)기법으로 학습된 vanilla ConvNet policy : [(50 3x3 filters), 2x2 max pool,(50 3x3 filters), (100 3x3 filters), 2x2 max pool,(100 3x3 filters), (100 3x3 filters), FC(100), FC(8), Softmax].
(FCN)
- Fully convolutional network (FCN), 3 layers
Test run
Grid-world domain의 테스트를 저자가 github에 올려 놓은 3개의 map에 대해 진행하였다. 아래 그림은 테스트런 결과로 얻은 grid-world domain 8 x 8 에 대한 tensorflow error trend를 예로 나타낸것이다. 3개의 domain모두 30 epoch만 실행하였다. 계속 진행하면 error는 더 줄어들것으로 예상된다. 각 domain별 success rate는 다음과 같다.
Domain success rate : 8/16/28 = 98.4%/89.7%/87.5%


