자료를 조사해 보니 최근 수많은 다양한 종류의 SLAM 기법이 있고 그 성능도 높지만 아직 해결해야 할 문제들이 여전히 상존하는것 같다. 여기서 먼저 소개하려는 EKF(Extended Kalman Filter)는 SLAM 분야 연구에서 매우 중요한 위치를 차지한다. 수학적 기법이며, 비선형 움직임에 대한 예측을 시도한 기법이기 때문이다. 혹시나 하여 첨언하지만, 앞서 소개한 Kalman filter를 사용한 localization과는 다른 이야기다. Localization은 기본적으로 map정보를 알고 있다고 가정하고 움직이는 물체의 위치를 예측하는 기술이지만, EKF SLAM은 Kalman filter를 사용하는 점은 같지만 움직이는 물체 위치와 map정보를 모두 얻어내는 기술이다. 그러므로 계산해야 할 정보가 landmarks의 수에 2배(x and y)를 곱한 만큼 state space dimension이 늘어난다. Map정보를 알고 있다고 가정해서 얻을 수 있는 움직이는 물체의 위치정보를 map정보가 없는 상태에서 추정하는 하는 일이나, 위치를 모르는 물체가 다양한 종류의 센서를 통해 주변 environment의 형태를 추정하는 것은 기본 정보가 없이 기본정보를 바탕으로 결과를 얻어내는 것과 다를바 없으므로, 이를 두고 “chicken and egg”관계로 묘사하는것 같다. 그러나, 실용수학이나 numerical method에서는 이와 유사한 상황의 문제에 대한 solution 기법을 많이 볼 수 있다. 이런 경우 주로 recursive iteration 기법을 사용하여 해결하며, 이 기법에서 중요한 문제는 풀이 과정 자체보다는 수렴의 문제이다. Dynamic Programming에 관한 글의 value iteration기법에서도 이와 비슷한 개념을 소개한 바 있다.
Recursive iteration 방법이 수학적으로 수렴을 하느냐에 대해 별도의 증명을 하는 논문을 이해해야 한다는 의미는 아니며, 일단 우리는 recursive iteration이 수렴하는 해를 구할 수 있다고 가정하자.(반드시 수렴한다는 의미는 아니다. 수많은 외란(disturbance), measurement noise, 비선형 dynamics로 인해 의미없는 결과를 낼 경우가 있을 것이다.) 과학이나 공학을 하는 사람에게는 수렴에 대한 증명은 흥미로운 주제가 아닐 수 있으나, 사실 그 결과는 매우 중요한 문제이다. 수학적 능력의 소유자가 수렴 조건을 수학적으로 증명해 주면, 실용적인 측면에서는 그 수렴조건을 constraint로 사용하여 실제적인 문제 해결에 사용할 수 있기 때문이다. 이글의 주제에서 벗어나지 않기 위해 수렴을 보다 쉬운 개념으로 생각해 볼 필요가 있다. 기본적으로 motion update만으로는 추정에 추정을 더하므로 시간이 지남에 따라 에러는 계속 커질 수 밖에 없다. 즉, 발산하게 되며 예측된 위치에 대한 분산값이 점차 커지게 된다. 이 에러를 줄이는 수단이 measurements를 이용하여 measurement update를 수행하는 방안이다. 이 단계를 거치면 위치에 대한 분산값이 다시 크게 줄어들어 예측된 위치에 대한 신뢰도가 다시 높아지게 된다. 이러한 recursive update과정에서 수학적으로 분산값이 다시 줄어들지 않는다면 수렴이 불가능하게 될것이다. 위치정보를 Gaussian distribution으로 표현하고 분산을 고려한다고 하면 확률론적 해석을 할 필요가 있다는 것을 추론할 수 있다. 그러므로 이 분야를 보면 아래와 같은 확률론적 개념소개가 많다.
Probabilistic SLAM
SLAM의 확률론적 해석은 확률분포 


이것을 계산해 내기 위해서는 기본적으로 state transition model(mobile robot kinematics)과 observation model이 필요하게 된다. Observation model은 아래와 같이 로봇 및 landmarks의 위치가 주어진다면 observation 

반면에, motion model은 이전 state정보와 control input 

SLAM기법은 이 두가지 모델을 사용하여 아래와 같이 prediction(time-update)단계와 correction(measurement update)단계를 거치는 recursive solution을 구하는 과정이다. 특히 time update에서는 total probability 개념이 사용되었고 두 probability의 convolution이고, measurement update단계에서 사용한 개념은 Bayes theorem근거하고 있으며 두 Gaussian distribution의 곱(multiplication)을 표현한것을 알 수 있다. 두 Gaussian distribution의 곱은 원래 분산값들 보다 분산값이 적어지며, 이것은 앞서 밝혔듯이 예측된 값의 신뢰도가 다시 상승한다는 것을 의미한다. Time update에서 integral로 표기한 부분은 discrete event의 경우 summation과 개념은 같다. 어떤 자료는 summation을 사용한다.


이 확률론적 개념을 map정보을 알아내는 문제(map building problem)로 해석한다면, 다음과 같이 표현할 수 있을 것이다.

한편, localization은 아래와 같이 표현할 수 있다.

EKF SLAM
Motion prediction의 확률적 표현인 




반면, observation model의 확률적 표현인 




위의 두 식은 아래에 정리할 EKF SLAM에서 움직임 정보와 measurement 정보를 제공하는 기본 식들이 된다고 할 수 있으며 정의해 줘야 한다. 사실, EKF SLAM을 유도(derivation)하는것이 반드시 필요한것은 아니라고 생각하지만, EKF에 기반한 SLAM기법이므로 EKF 자체에 대한 기본적인 내용은 우선 알아야 할 필요가 있다고 생각한다. 자료조사중에 발견한 EKF 자료중에 유도과정을 포함해서 정리가 잘된 자료로서 아래 링크에서 찾아 볼 수 있는 G.A Terehanu와 Welch & Bishop의 tutorial을 review하기를 권장한다.
Extended Kalman Filter Tutorial
이러한 EKF 기법에서 state space분만 아니라 map까지 함께 적용한다고 가정하면, 한단계 더 복잡해질것이다.(EKF의 vector나 matrix에 그치지 않고 vector/matrix를 element로 가지는 matrix로 표현된다.) 그러나 EKF의 확장이므로 유도나 개념의 이해에 대한 커다란 장벽은 제거되었다고 볼 수 있다. 이제 EKF SLAM의 수학적 표현을 소개한다. (먼저, 여기서 사용되는 표기법으로 





이 식들은 기본적으로 EKF의 state space에서 map space를 포함하는 dimension확장이라고 할 수 있으므로, Kaman gain과 Jacobian의 표기가 다른것을 제외하고는 앞서 소개한 자료에서 유도된 EKF와 매우 유사하다는 것을 알 수 있다. Kalman gain은 새로운 measurement의 신뢰도를 의미한다고 생각할 수 있다. 즉 식에서 알 수 있듯이 이 gain값이 크면 새로운 measurement에 의존해서 state와 landmarks의 위치를 추정하는 경향을 보이며, 반대로 이 값이 작으면 time update model의 예측치에 더 의존하는 경향을 보인다. 즉 두가지 정보(일반화 시켜 말하자면, 하나는 이론적 추론이며 다른 하나는 실험적 측정)의 신뢰도에 대한 가중치라고 볼 수 있다.
EKF SLAM test-run
수학적으로 잘 정의된 EKF SLAM도 실제 적용하기 위해서는 기술적 문제가 있다. 먼저 무엇을 landmarks로 할것인지 결정하는 문제이다. 그 다음에는 로봇이 센서에 의해서 감지한 landmarks가 이전에 감지한 landmarks중 어떤 landmarks인가를 구분해야 동일한 landmarks와 new landmarks을 구분하여 처리할 수 있을 것이다. 이 문제를 data association이라고 하며, 이 문제가 간단한 문제는 아닌것 같다. 사실 SLAM의 부가적인 문제이지만 그 문제 자체를 해결하는것이 쉽지 않을 것이다. 인간에게는 시각정보를 이용해서 매우 쉬운 문제이지만, 센서로 모든 landmarks를 구분해 내는 일은 쉽지 않을 것임을 알 수 있다. 일단은 이 문제를 고려하지 않고 landmarks의 위치는 알지 못해도 식별은 가능하다고 가정하고 SLAM을 시도해 본다.
EKF SLAM문제를 coding하여 풀어내는 것은 robot의 pose state space의 정의와 kinematics를 물리적인 식을 통해 표현하는 것부터 시작한다. 이 식의 Jacobian을 구해야 하며, initial state와 initial covariance vector를 가정하여 초기화 시킨다. 실제 matrix를 이용해 연산을 수행해야 하므로 각 항목의 정확한 계산도 중요하지만 landmarks의 좌표가 포함된 매우 큰 matrix를 다루는 것이므로 matrix의 elements를 그룹별로 나눠서 고려하는 것이 유리하다. 예를 들어, time update에 대해서는 실제 landmarks의 좌표들끼리의 상관관계는 전혀 고려할 필요가 없는 단계이므로 robot의 pose state와 관련된 부분만 update하도록 한다. 이와 같은 과정은 고려가 필요한 부분만 matrix로 만들고 전체 dimension을 가진 high dimension space로 확장하는 과정이라고 할 수 있다.
Measurement update는 landmarks의 위치를 추정하는 일 부터 시작한다. 센서로 부터 측정된 자료는 위에서 예측한 로봇의 위치를 이용하여 각 landmarks의 위치를 추정해 볼 수 있다. 이것을 이용하면 다시 measurement의 값을 환산해 볼수 있다. 여기서 observation model이 수학적으로 유도되며 이것을 이용하여 예측된 measurement값을 expected observation이라고 한다. 이 observation model의 Jacobian을 구하고, measurement update를 위한 많은 매트릭스 연산을 수행하면 landmarks의 정보를 포함한 최종 updated state vector를 얻을 수 있다. 여기까지 설명한 과정이 EKF SLAM을 실행하는 과정이며, 다소 복잡하고 하나 하나의 절차가 간단하다고 할 수 없으나, 그 과정이 매우 논리적이므로 충분한 시간을 가지고 검토해볼 가치가 있다고 생각한다.
아래 그림은 EKF SLAM기술을 컴퓨터 상에서 모사한 것이다. 푸른색이 로봇의 주행경로이며, 붉은색이 SLAM에 의해 예측된 로봇의 위치이고, 붉은색 ‘x’는 landmarks를 의미한다.

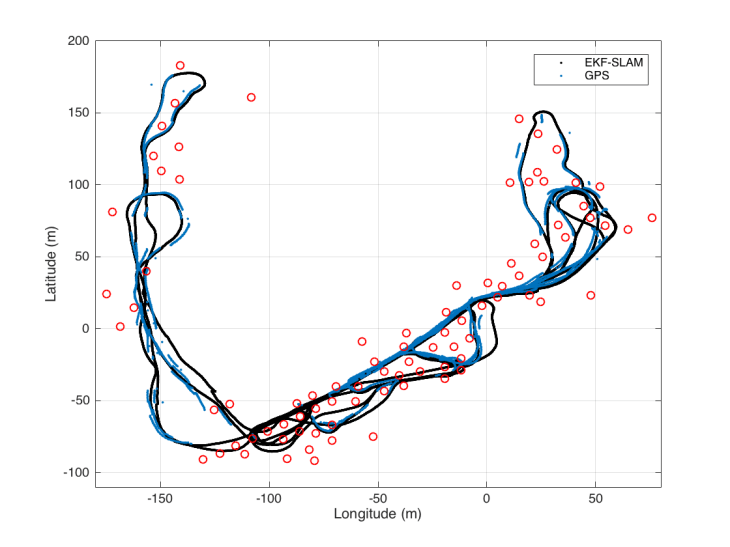
EKF SLAM at Victoria park
Victoria park에서의 Ladar를 이용한 데이터는 SLAM분야의 testbed로 많이 사용된다. Googling하면 관련 이미지가 많이 나오는데, GPS를 장착한 차량이 Ladar sensor를 통해 감지한 pole 형태의 landmarks의 데이터를 측정한 자료이다. MRPT website에 접속하면 관련 자료를 찾을 수 있다. 이 자료를 이용하여 EKF SLAM을 수행한 자료가 있어서 실행해 보았다. 아래 그림이 그 결과이며, 푸른색 주행 경로는 차량에 장착된 GPS를 통해 자신의 위치를 나타낸 것이며, 검은색 주행경로는 EKF SLAM에 의해 예측된 차량의 위치경로이다. 붉은색 원은 pole형태의 landmarks의 위치를 예측한 것이며, 이 landmarks는 주로 나무를 감지한 것이라고 한다.