
이제 RL이 해결하고자 하는 대상인 environment로 관심을 돌릴 때이다. Agent는 environment에서 오는 시그날인 state에 따라 판단하여 결정을 내린다. 여기서, state라고 함은 agent가 받아들이는 모든 정보(information)을 의미한다. 이 state information은 가공되지 않은 information일 수 도 있고, 기본 정보를 이용항 가공된 정보일 수도 있다. 단지 agent가 판단(decision-making)에 이용할 수 있는 정보형태이면 된다. State 정보가 agent의 판단에 이용된다고 해서, 판단에 필요한 모든 정보를 다 받아야 한다는 의미는 아니다. 보다 정확한 판단을 위해 필요한 정보(hidden state information)가 있더라도 주어진 정보를 최대한 이용하여 판단을 하는 것이며, environment가 가지는 모든 정보를 받아야 하는것은 더더군다나 아니다. 단지 우리가 관심을 두는 것은 주어진 정보를 이용하여 어떻게 바람직한 판단을 이끌어 내는 알고리즘을 구축하느냐이다.
판단정보를 가지고 있는 state signal에 관해 시간의 관점에서 바라보자. 이 시그널은 바람직하건데 과거의 정보를 포함하고 있는 것이 좋다. 이처럼 과거의 상태나 정보가 함축되어 포함된 state를 Markov property를 가진다고 한다. 예를 들어, 장기판의 현재 상태는 과거 player들이 행한 모든 게임의 결과물이 표현된 것이다. 이런 특성을 가지기 위해서는현재 state signal은 반드시 history나 path에 무관해야 한다. 즉, 과거 history에 따라 현재의 stat signal이 다른 의미를 가진다면 Markov property를 가진다고 할 수 없다. 이를 수식으로 표현하면 다음과 같다.

Markov property는 reinforcement learning에서 매우 중요한 개념인데, 이는 decision이나 value가 현재의 state만의 함수라는 것을 가정으로 하기 때문이다. 그러나, 완전히 Markov property를 가지지 않은 non-Markov property state signal일지라도 대부분은 이 이론을 적용하여 알고리즘을 구축하고 성공적으로 응용할 수 있는 경우가 많다. 우선은 Markov property를 보이는 state에 대한 완전한 이해로 부터 시작해야 보다 복잡한 non-Markov case에 대한 확장 응용이 가능해 질것이다.
Markov Decision Processes
Markov property를 만족하는 reinforcement learning task를 Markov decision process, MDP,라고 한다. 이중에서 state와 action space가 유한공간인 경우를 finite Markov decision process라고 하며 우리가 다루는 reinforcement learning은 대부분 이 경우이다. 이것을 수학적 표현을 dynamics of environment라고 하며 위의 식과 같이, 주어진 상태 s와 action a가 주어지면 다음상태 s’과 reward r을 나타날 확률로 environment를 표현할 수 있다. 이 확률분포(다시 말해, environment dynamics)를 알 수 있으며, environment에 관련하여 알고 싶은 모든것을 계산할 수 있다고 볼 수 있다. 예를 들어, 어느 state-action pair에 대한 reward나 state-transition probability는 다음과 같이 나타낼 수 있다.
![r(s,a) \doteq \mathbb{E}[R_{t+1} | S_t = s, A_t = a] = \displaystyle\sum_{r\in\mathcal{R}}r\displaystyle\sum_{s'\in\mathcal{S}}p(s',r|s,a)](https://s0.wp.com/latex.php?latex=r%28s%2Ca%29+%5Cdoteq+%5Cmathbb%7BE%7D%5BR_%7Bt%2B1%7D+%7C+S_t+%3D+s%2C+A_t+%3D+a%5D+%3D+%5Cdisplaystyle%5Csum_%7Br%5Cin%5Cmathcal%7BR%7D%7Dr%5Cdisplaystyle%5Csum_%7Bs%27%5Cin%5Cmathcal%7BS%7D%7Dp%28s%27%2Cr%7Cs%2Ca%29&bg=ffffff&fg=444444&s=0&c=20201002)

위의 수학적 표현으로 environment dynamics가 정의되었지만, 아무래도 개념을 보다 구체화하기 위해서는 실례를 들어 설명하는 것이 좋다. Sutton & Barto의 책에서는 recycling robot을 예로 들어 설명하였는데, recycling robot의 state는 robot이 battery energy level이고 state set은 


Agent가 취하는 행동에 따른 상태변화와 그것의 확률 및 reward를 한꺼번에 표현해 도식적으로 표현한 그림을 transition graph라고 하며, 이 그래프를 이용하면 finite MDP를 요약하여 표기할 수 있다. Recycling robot의 경우 아래 그림과 같이 표현될 수 있다.

위의 transition graph에서 관심있게 보아야 할것이 있다. Large open circle로 표현된 것을 state nodes라고 small solid circle로 표현된 것을 action nodes라고 한다. 아래는 recycling robot의 transition probability와 reward를 표로 나타낸 것이다. 앞서 말한 수학적 정의와 함께 보면 간단히 개념이 이해될 수 있다.

Value Functions
RL의 최종목적은 쉽게 정의할 수 있지만, 그전에 agent의 state나 취하는 action에 대해 평가를 하는 작업이 필요하다. 이것을 value function이라고 하고 “how good”을 의미한다. 이 “how good”이라는 개념은 미래의 reward, 더 정확하게는 예상되는 return을 의미한다. 물론, 이 future reward는 agent가 어떤 행동(action)을 취하느냐에 따라 달라지게 되어 있다. 그러므로, value function은 필연적으로 특정 policy와 관련지어 생각해야 한다.
사실, agent가 하는 행동에 대한 평가는 지금 당장 내릴 수 없는 경우가 많다. 장기나 바둑을 둘때 지금 둔 착석의 최종 평가는 게임의 승리 여부이다. 그러므로 value function을 정의하는 것이 매우 중요하며, 경우에 따라서는 Monte Carlo Tree Search와 같은 알고리즘이 더 적당 할 수 있다.
Policy 

![v_\pi (s) \doteq \mathbb{E}_\pi [G_t | S_t = s] = \mathbb{E}_\pi \begin{bmatrix} \displaystyle\sum_{k=0}^{\infty}\gamma^k R_{t+k+1} | S_t = s \end{bmatrix}](https://s0.wp.com/latex.php?latex=v_%5Cpi+%28s%29+%5Cdoteq+%5Cmathbb%7BE%7D_%5Cpi+%5BG_t+%7C+S_t+%3D+s%5D+%3D+%5Cmathbb%7BE%7D_%5Cpi+%5Cbegin%7Bbmatrix%7D+%C2%A0%5Cdisplaystyle%5Csum_%7Bk%3D0%7D%5E%7B%5Cinfty%7D%5Cgamma%5Ek+R_%7Bt%2Bk%2B1%7D+%7C+S_t+%3D+s+%5Cend%7Bbmatrix%7D&bg=ffffff&fg=444444&s=0&c=20201002)
여기서, ![\mathbb{E}_\pi [ \cdot ]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%5Cpi+%5B+%5Ccdot%C2%A0%5D+&bg=ffffff&fg=444444&s=0&c=20201002)


마찬가지로, agent가 policy 
![q_\pi (s, a) \doteq \mathbb{E}_\pi [G_t | S_t = s, A_t = a] = \mathbb{E}_\pi \begin{bmatrix} \displaystyle\sum_{k=0}^{\infty}\gamma^k R_{t+k+1} | S_t = s , A_t = a \end{bmatrix}](https://s0.wp.com/latex.php?latex=q_%5Cpi+%28s%2C+a%29+%5Cdoteq+%5Cmathbb%7BE%7D_%5Cpi+%5BG_t+%7C+S_t+%3D+s%2C+A_t+%3D+a%5D+%3D+%5Cmathbb%7BE%7D_%5Cpi+%5Cbegin%7Bbmatrix%7D+%C2%A0%5Cdisplaystyle%5Csum_%7Bk%3D0%7D%5E%7B%5Cinfty%7D%5Cgamma%5Ek+R_%7Bt%2Bk%2B1%7D+%7C+S_t+%3D+s+%2C+A_t+%3D+a+%5Cend%7Bbmatrix%7D&bg=ffffff&fg=444444&s=0&c=20201002)
앞서 정의된 두개의 value function은 경험에 의해 값이 예측된다. 예를들어, agent가 policy
Reinforcement Learning에 사용되는 value function의 기본적 특징은 recursive relationship(순환 참조)을 만족한다는 것이다. 주어진 policy
![v_\pi (s) \doteq \mathbb{E}_\pi [G_t | S_t = s] = \mathbb{E}_\pi \begin{bmatrix} \displaystyle\sum_{k=0}^{\infty}\gamma^k R_{t+k+1} | S_t = s \end{bmatrix} \\=\mathbb{E}_\pi \begin{bmatrix} R_{t+1} + \gamma \displaystyle\sum_{k=0}^{\infty}\gamma^k R_{t+k+2} | S_t = s \end{bmatrix} \\=\displaystyle\sum_{a} \pi (a|s)\displaystyle\sum_{s'} \displaystyle\sum_{r} p(s',r|s,a) \begin{bmatrix} r + \gamma \mathbb{E}_\pi \begin{bmatrix}\displaystyle\sum_{k=0}^{\infty}\gamma^k R_{t+k+2} | S_t = s' \end{bmatrix} \end{bmatrix} \\ =\displaystyle\sum_{a} \pi (a|s)\displaystyle\sum_{s', r} p(s',r|s, a) \begin{bmatrix} r + \gamma v_{\pi} (s') \end{bmatrix}](https://s0.wp.com/latex.php?latex=+v_%5Cpi+%28s%29+%5Cdoteq+%5Cmathbb%7BE%7D_%5Cpi+%5BG_t+%7C+S_t+%3D+s%5D+%3D+%5Cmathbb%7BE%7D_%5Cpi+%5Cbegin%7Bbmatrix%7D+%C2%A0%5Cdisplaystyle%5Csum_%7Bk%3D0%7D%5E%7B%5Cinfty%7D%5Cgamma%5Ek+R_%7Bt%2Bk%2B1%7D+%7C+S_t+%3D+s+%5Cend%7Bbmatrix%7D+%5C%5C%3D%5Cmathbb%7BE%7D_%5Cpi+%5Cbegin%7Bbmatrix%7D+%C2%A0R_%7Bt%2B1%7D+%2B+%5Cgamma+%5Cdisplaystyle%5Csum_%7Bk%3D0%7D%5E%7B%5Cinfty%7D%5Cgamma%5Ek+R_%7Bt%2Bk%2B2%7D+%7C+S_t+%3D+s+%5Cend%7Bbmatrix%7D+%5C%5C%3D%5Cdisplaystyle%5Csum_%7Ba%7D+%5Cpi+%28a%7Cs%29%5Cdisplaystyle%5Csum_%7Bs%27%7D+%5Cdisplaystyle%5Csum_%7Br%7D+p%28s%27%2Cr%7Cs%2Ca%29+%5Cbegin%7Bbmatrix%7D+r+%2B+%5Cgamma+%5Cmathbb%7BE%7D_%5Cpi+%5Cbegin%7Bbmatrix%7D%5Cdisplaystyle%5Csum_%7Bk%3D0%7D%5E%7B%5Cinfty%7D%5Cgamma%5Ek+R_%7Bt%2Bk%2B2%7D+%7C+S_t+%3D+s%27+%5Cend%7Bbmatrix%7D+%5Cend%7Bbmatrix%7D+%5C%5C+%3D%5Cdisplaystyle%5Csum_%7Ba%7D+%5Cpi+%28a%7Cs%29%5Cdisplaystyle%5Csum_%7Bs%27%2C+r%7D+p%28s%27%2Cr%7Cs%2C+a%29+%5Cbegin%7Bbmatrix%7D+r+%2B+%5Cgamma+v_%7B%5Cpi%7D+%28s%27%29+%5Cend%7Bbmatrix%7D&bg=ffffff&fg=444444&s=0&c=20201002)
여기서 특히 마지막 식을 눈여겨 볼 필요가 있다. 모든 a, s’, r에 대하여 확률값을 weight로 사용하여 bracket내부의 return값을 가중평균내는 것과 같은 의미이다. 이 식을 

여기서, (a)는 state-value function인 
Optimal Value Functions
우리가 value function을 정의하였으므로, 이 값을 최적상태(최대화)로 만들어 주는 policy가 존재할 가능성이 있다. Reinforcement learning task를 해결한다는 것은, 결국 이런 best policy를 찾아내는 것을 의미한다. 만약 모든 



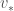

같은 맥락에서, optimal action-value function, 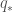

같은 optimal policy기준으로 두개의 value function을 정의하였으므로, 다음과 같이 두 value function간의 관계가 성립한다.
![q_* (s, a) = \mathbb{E}[R_{t+1} + \gamma v_* (S_{t+1}) | S_t = s, A_t =a]](https://s0.wp.com/latex.php?latex=q_%2A+%28s%2C+a%29+%3D+%5Cmathbb%7BE%7D%5BR_%7Bt%2B1%7D+%2B+%5Cgamma+v_%2A+%28S_%7Bt%2B1%7D%29+%7C+S_t+%3D+s%2C+A_t+%3Da%5D&bg=ffffff&fg=444444&s=0&c=20201002)
Optimal value function에 대해서도 Bellman equation이 성립하며, optimal policy하에 있는 value function은 가장 최적의 action을 취할 때 얻을수 있는 return값과 같을 것이다.


위의 식들은 도식적으로 backup diagram으로 표현하면 아래와 같다. 이것은 

실제로 
Optimal value function이나 policy는 정의가 되었지만, 실제로 agent가 최적의 policy를 찾아 내는 것은 그다지 쉽지 않은 일이며, 가능하더라도 매우 값비싼 computing cost가 요구될것이다. 실제 우리가 environment dynamics에 완전하고 정확한 model을 알고 있다손 치더라도 Bellman equation을 통해 optimal policy를 찾아내는 것은 쉽지 않은 일이다. 그러므로 현실적인 solution은 최적해에 대한 근사해(approximation)의 관점에서 접근하는 것이다. 그 다음은 어떤 방법이 더 효율적으로 approximation을 찾아내는가이다. 모든 경우의 수를 다 해볼 수 없다면, 자주 접하는 state에 대해 더 많은 노력을 기울이는 것이 효율적인 approach일것이다.
여기까지 reinforcement learning에 필요한 기본 개념을 모두 정리한것 같다. 다은 포스트부터는 보다 실전적 문제를 다룰 예정이다.
Note) 본 포스팅은 Sutton과 Barto가 공저한 Reinforcement Learning : An Introduction을 기초로 작성된것이다.
