
이제 실제로 value function을 예측하고 optimal policy를 찾아내는 learning method를 시작해 보자. DP에서는 기본적으로 environment dynamics을 안다고 가정하였으나, 여기서는 이것을 가정하지 않는다. 대신에 MC method는 environment와의 모의(simulated) 또는 실제(actual) interaction을 통해 얻은 states, action, rewards가 포함된 sample이라고 불리우는 경험(experience)을 이용한다. 실제 경험을 통한 학습은 environment dynamics를 전혀 모르지만 optimal behavior를 찾아 낼 수 있다는 점에서 매우 인상적인 일이며, 모의 경험을 통한 학습도 모델이 필요하기는 하지만 DP에는 필요한 transition probability distribution을 몰라도 학습이 가능하다는 면에서 강력하다고 할 수 있다. 물론 sample은 transition probability distribution에 의거하여 얻겠지만, 분포 자체를 알아야 할 필요는 없다.
Monte Carlo method는 sample return의 평균치를 기반으로 RL 문제를 풀어나간다는 점을 주목해야 한다. MC는 episodic tasks에 대해 적용하는 것을 가정한다는 의미이다. 즉, MC는 step-by-step 보다는 episode-by-episode단위의 학습이다.
원래 “Monte Carlo”라는 용어는 무작위(random) sample을 기반으로 하는 계산에 광범위하게 적용되는 개념이다. 그러나, RL에서는 partial return에 대조하여 complete return에 대한 평균을 이용하는 방법을 지칭하기 위해 사용한다. 이것은 나중에 설명한 주요한 RL methods들의 상대적 개념으로 인식해야 한다.
MC에서는 sample에 의한 experience만 얻을 수 있는 정보라는 것을 염두해 두어야 한다. Dynamic Programming처럼 MDP에 대한 지식을 기반으로 value function을 구하는 것이 아니라, sample experience를 이용하여 value function을 구하고 이와 연계된 policy를 구축함과 동시에, 앞서 설명한 GPI (General Policy Iteration)의 개념을 사용하여 문제를 풀어낸다. 즉, 앞서 dynamic programming에서 solution algorithm을 sample experience를 사용하여 적용하는 것이다.
Monte Carlo Prediction
DP를 알아볼때 사용한 approach를 MC에 적용해 보자. 먼저, 주어진 policy에 대한 state-value function을 MC method를 이용하여 구해보는 것이다. State value는 그 state로 부터 시작해서 얻을 수 있는 누적 할인 보상 (cumulative future discounted return)에 대한 기대값을 의미한다는 것을 상기할 필요가 있다. 경험으로 부터 이 value function을 구해내는 가장 분명한 방법은 state visit이 일어난 후 관측된 return의 평균치를 구하는 것이다. 더 많은 return을 관찰할 수록 그 평균치는 기대치에 수렴할것이며, 이 개념이 Monte Carlo method가 사용하는 토대이다.
Episode 수행중 state s를 경험하는 것을 s를 visit한다고 한다. 우리글로 번역하는 과정에서 알아 두어야 할 전문용어를 무리하게 전부 한글로 번역하게 되면 의미전달에 오해가 생길 수 있고, 하루가 멀다하고 새로 쏱아져 나오는 연구 논문을 볼때 생소한 단어로 오해 할수 있다. 그러므로 될 수 있으면 keyword는 원래의 단어를 그대로 사용하는 편을 선호한다. 의미 전달을 위해 자체적으로 재해석하여 글을 적고 있지만 원문을 그대로 읽으면 가장 좋을 것이다.
물론, state s는 한 episode내에서도 여러번 접할 수 있으므로, 첫번째 접하는 것을 first visit to s라고 한다. First-visit MC method는 state s를 처음 접한 후 얻은 return값의 평균을 사용하여 

앞서 설명한 backup diagram을 MC에 대해서도 표현하게 되면, state node로 부터 시작해서 한 episode가 끝나는 terminal state까지 이어지는 모든 과정(trajectory)을 연결하는 모양이 될것이다.

이 backup diagram을 DP의 backup diagram과 비교하여 그 차이를 이해해야 한다. 이것과는 별개로 눈에 두드러지지 않지만 DP와는 다른 MC의 특징이 있다. 그것은 MC는 다른 state의 예상값에 의존하여 state-value를 예측하지 않는다는 점이다. 다른 state의 state-value에 의존하여 현 state를 예측하는 방법을 bootstrap한다고 한다. 마지막으로 MC가 DP에 비해 가지는 장점은 state-value를 예측하기 위한 계산부하가 state의 수에 직접적인 관계가 없다는 점이다. DP는 모든 state에 대해 estimate가 있어야 정확한 state-value를 구할 수 있다는 점을 상기할 필요가 있다.
Monte Carlo Estimation of Action Values
Model을 알수 없다면 state value보다는 action value를 구하는 것이 더 유용하다. 모델이 있는 경우에는 state value만으로도 policy를 결정할 수 있지만, 모델이 없는 경우에는 state value만으로는 불충분하다. 그러므로, 우리의 MC method의 첫번째 목표는 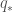
Monte Carlo Control
MC estimation을 사용해서 optimal policy를 찾아내는 방법을 이용하면 MC를 control에 사용할 수 있다. 전체적인 개념은 DP에서 언급된 GPI(General Policy Iteration)을 이용하는 것이며 이것을diagram으로 나타내면 아래와 같다.
여기서 control이라는 용어는 process control에서와 같이 제어라는 의미로 사용한 단어가 아니다. RL에서는 optimal policy를 찾는것을 control이라고 한다. 앞서 dynamic programing의 dynamic이 시간에 따른 변화를 의미하는것이 아닌것과 같이 RL에서 사용하는 용어는 기존 technology나 engineering에 익숙한 사람에게는 혼란을 야기할 수 있다. 용어의 정확한의미는 이해의 기초가 되기 때문이다.

Policy improvement는 현재의 value function에 기반하여 greedy한 policy를 따르는 방법으로 이루어 진다. 즉 새로운 policy 


여기에는 두가지 무리한 가정을 내재하고 있다. 첫번째는 episode가 exploring starts에 따르는 것이고, 두번째는 무한번의 episode를 한다고 가정한 것이다. Exploring starts를 따르는 Monte Carlo method 알고리즘을 아래 나타내었다.

Monte Carlo Control without Exploring Starts
그렇다면, 앞서 사용한 가정인 exploring starts를 회피하는 방법은 무었일까? 이것(모든 action이 아무제한 없이 선택받을)을 보증할 만한 유일한 방법은 agent로 하여금 계속적으로 선택하도록 강요하는 것이다. 이것을 위한 두가지 방법이 있는데 on-policy methods와 off-policy methods이다. On-policy method는 결정에 사용된 policy를 평가하고 개선하는 반면, off-policy method는 결정에 필요한 data를 만드는데 사용된 policy와는 다른 policy를 평가하고 개선한다. 앞서 언급한 MC ES algorithm은 on-policy method의 일종이다.
On-policy control methods에서는 policy가 유연(soft)하다고 한다. 이것의 의미는 모든 






MC ES method를 사용하는 대신에

Off-policy Prediction via Importance Sampling
모든 control methods를 배우는 과정은 하나의 딜레마를 피할 수 없다. Optimal behavior를 따라 action value를 구하지만, 모든 action을 탐색(explore)해 보려면 non-optimal한 선택을 할 수 밖에 없는 것이다. 어떻게 하면 탐색하는 policy를 취하면서 optimal policy를 배울 수 있을까? 앞서 사용한 on-policy 방법은 실상은 optimal policy를 찾느다기 보다는 탐색을 계속하는 near-optimal policy를 찾는 방식으로 일종의 타협을 하는 방법이다. 보다 명약관화한 방법은 두 종류의 policy를 사용하는 방법으로, 하나는 optimal policy가 되는 방법을 학습하고, 다른 하나는 탐색을 추구하면서 behavior를 결정하도록 만드는 방법이다. 학습하는 policy를 target policy라고 하고, behavior를 결정하는 policy를 behavior policy라고 한다. 이 경우에 우리는 학습이 target policy와는 별도로(“off”) 얻는 데이터로 부터 이루어지므로 이과정을 off-policy learning이라고 한다. On-policy 및 off-policy 방법은 둘다 사용되지만 off-policy method가 일반적으로 variance가 크고 수렴이 느리다. 반면에, off-policy 방법이 보다 강력하고 일반적이라고 할 수 있다.
Off-policy method를 알아보기 위해 우선은 prediction problem을 먼저 고려해 보자. 여기서는, target policy와 behavior policy가 정해져 있으며, 



Policy 

거의 모든 off-policy method는 value의 추정치를 예측하기 위해 importance sampling이라는 테크닉을 사용한다. Off-policy에 importance sampling기법을 적용하기 위해 연속적인 sequence의 action 및 state의 trajectory가 나오는 확률 개념을 도입하여 importance-sampling ratio라는 개념을 도입하는데 아래와 같다.

여기서 주목할 점은 비록 MDP에서는 transition probability항이 필요하지만, 서로 상쇄되어 결국 policy만 알아도 importance-sampling ratio를 구할 수 있다는 점이다.
이제 off-policy Monte Carlo methods를 적용해 보기전에 하나의 개념만 더 설명하기로 한다. 바로 위에서 정의한 importance-sampling ratio를 활용하는 방법인데, 이것은 사실 우리가 policy 

위의 방법은 단순 평균치를 내는 방법을 사용한 것이므로 ordinary importance sampling이라고 한다.

반면 위의 식은 weighted average를 사용하므로 weighted importance sampling이라고 한다.
Monte Carlo prediction method는 episode단위로 incremental implementation이 가능하다. incremental implementation이란, 그동안의 모든 결과값을 모두 저장하지 않고도 cumulative data를 얻어내는 방식을 의미한다. 일반적인 방식은 아래와 같다.
![]()
MC method에서 average return값은 위와 같은 식을 이용하여 계속해서 update해 나갈 수 있다. Off-policy method에서 weighted importance sampling방법을 이용하여 incremental implementation을 통한 value function을 update하기 위해서는 아래와 같은 수식을 염두해 둘 필요가 있다. 여기서, 


![]()
Off-Policy Monte Carlo Control
아래에 앞서 설명한 GPI, weighted importance sampling을 활용한 off-policy incremental implementation MC control algorithm을 나타내었다. Target policy는 greedy policy이며, behavior policy는 어느것이든 될수 있지만, 앞서 설명한 policy 

이 알고리즘이 내포하고 있는 문제점은 episode의 뒷부분부터 학습이 가능하며, 그것도 action이 target policy와 같이 greedy해야만 의미가 있다는 점이다. 그러므로, nongreedy action이 자주 일어난다면 학습속도는 느려질것이고, 특히 긴 episode의 선두부분에 있는 state는 더더욱 느린 학습속도를 보일것이다. 이 단점의 해결책은 temporal-difference learning을 사용하는 방법이며, 이 방법은 별도로 포스팅할 예정이다.
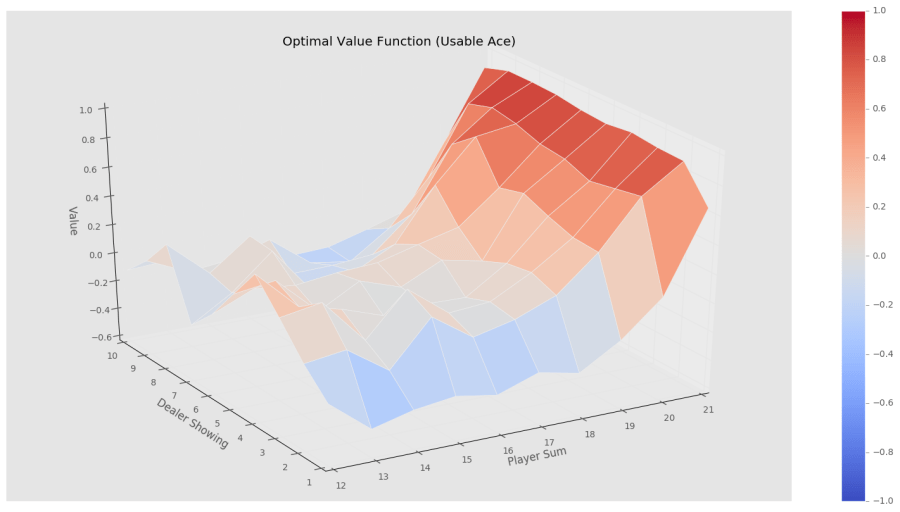
Off-Policy MC control for Blackjack game
위의 알고리즘을 blackjack game에 적용하여 얻어낸 value function의 graph를 아래 예시하였다. Dealer가 보여준 card와 player가 가진 두장의 card의 합계를 state로 규정하고 action space로는 다른 카드를 받을것(hits)인가 그만 받을것(sticks)인가로 규정하여 best policy를 구축하였을 때 얻을 수 있는 value function 분포와 optimal policy를 나타낸것이다. Policy graph에서 값이 1인 경우는 hits를 의미하고 0인 경우는 sticks를 의미한다. Ace는 11로도 counting할수 있으며, 이것을 usable ace라고 한다. 이것은 게임의 큰 변수이므로 이경우를 구분한것을 참조하기 바란다.


Note) 본 포스팅은 Sutton과 Barto가 공저한 Reinforcement Learning : An Introduction을 기초로 작성된것이다.
