
Atari, OpenAI의 Gym, Mujoco는 그동안 RL연구에서 훌륭한 test bed가 되어 주었다. 그러나 이런 간단한 게임환경을 대상으로 single agent의 성능만을 개선시키려는 알고리즘들은 다른 게임환경에서 한계를 보여주곤 했다. 이러한 면이 항상 아쉬운 모습이었고, multi-agent가 현실과 유사한 복잡한 환경에서 강화학습의 성공이 더 증명되어야 할 필요성이 있었다. 그러므로, 최근에는 변화가 많은 환경에서 agent들의 성능을 개선시키는 노력이 있었고, 더 나아가 RTS게임환경에서 인공지능의 한계를 시험하는 단계에 이르렀다. OpenAI가 Dota2에서 인공지능이 RTS게임과 같은 복잡한 환경에서 프로게이머를 능가할수 있다는 가능성을 보여주었고, 얼마 지나지 않아, DeepMind는 스타크래프트 II에서 AlphaStar라는 인공지능으로 프로 게이머와 공개적인 대결을 하는 행사를 개최하는 수준에 이르렀다.
스타크래프트는 RL의 관점에서 매우 어려운 목표로 알려져 있으며, RL이 학습하는 과정과 사용가능한 알고리즘을 구현해본 사람은 이 목표가 실제로 매우 어려운 목표임을 직감할 수 있다. 일단 multi-agent problem이며, partially observable state이고, 많은 unit들을 선택하고 제어해야 하는 매우 큰 action space를 가지고 있다. 무엇보다도 가장 문제가 되는 부분은 credit assignment 문제이다(sparse reward structure, delayed reward structure). AlphaGo 소개글에서 밝힌바와 같이 바둑도 action space가 크고, credit assignment문제가 있지만, environment의 모든 정보를 얻을 수 있고, multi-agent problem도 아니라는 면에서 스타크래프트 정복보다는 상대적으로 쉬운 문제였다.
DeepMind사가 스타크래프트를 정복하기 위한 프로젝트를 시작한 후 SC2LE라는 python interface를 공개하고 기존의 RL알고리즘을 사용하여 시도해본 결과를 공개한적있다. 이 논문에서 밝힌바와 같이 게임을 정복하는 일이 어렵기 때문에 미니게임 맵을 이용하여 간단한 task를 대상으로 알고리즘을 테스트하였다. 테스트한 결과를 보면 CNN과 RNN기반의 기존 알고리즘으로는(비록 신경망 구조는 훌륭하다 하더라도) 이 게임을 정복하기 어렵다는 것을 알 수 있다. 먼저 스타크래프트를 RL로 공략해보려고 접근하면, 수많은 크고 작은 문제들이 자연스럽게 머리에 떠오른다. 처음 알파고이후 목표가 스타크래프트라는 것을 들었을때 떠오른 생각을 몇가지를 적어보면 이렇다.
- 게임 unit별로 독립적인 policy (또는 brain)를 가져야 하는가?
- Observation/State는 어떻게 정의해야 하며, 시각정보와 play에 참가하고 있는 unit이 가지고 있는 개별적 정보는 어떻게 처리해야 할까?
- 게임의 action space는 단순하지 않고 매우 복잡하다. 순차적 action이 필요한 부분도 있고, unit별로 수행하는 action이 다른데다가 상황에 따라서 할수 있는 action이 달라지는 상황에서 action policy는 어떻게 만들어야 하나?
- 게임 agent들도 계속에서 사라지고 생성되는 상황과 같이 environment가 계속 변화하는 dynamic environment에서 학습이 가능할 것인가?
- 전략게임은 현재의 판단과 결정이 유기적으로 게임 전체의 전략과 연계 필요성으로 인해 temporal information의 전달이 반드시 필요할것이므로, RNN을 포함시켜야 하는가? 그런데, environment가 계속 변하는 상황에서 RNN이 도움이 될것인가? 아니면 잘못된 정보를 전달할 가능성이 있지 않는가?
- 학습을 위한 Reward/Return을 어떻게 formulation해야 하며, 승패와 같은delayed return을 어떻게 해결해야 하는가?
- 이런 어려운 상황에서 DQN이나 Actor-Critic과 같은 기존의 대표적인 RL 알고리즘으로 간단한 게임(Map Simple64)이라도 학습시킬 가능성이 있는가?
이처럼 복잡하고 어려운 문제는 우선 간단한 시도부터 시작해서 점차 개선시키는 방법으로 문제를 해결하는 것이 좋을 것이다. Deepmind사의 첫 시도는 SC2 battle이 아닌 단순한 목표를 가진 map에서(예를 들면, SCV가 미네랄을 모으는 환경), 비교적 직관적인 알고리즘을 이용하여 이 RL 학습을 시도해 보는 것이었다. 우선, 게임 unit별로 policy를 가지는 방법이 아니라 master controller가 모든 것을 조정하도록 전체를 하나의 policy로 제어하도록 하였다( macro-management라고 한다). Observation은 Atari 게임에서 사용한것과 같이 visual(pixel) based information을 사용하고, 원론적으로 무수히 많은 action space를 줄이는 방안도 고려하였다. 신경망에 CNN 및 RNN구조도 포함시키고, 학습을 용이하게 하기 위해서 승패가 아닌 작은 보상(internal reward)를 부여하고, 기존의 유명한 알고리즘(DQN이나 Actor-Critic)을 적용해서 테스트해본다. (DQN이 적용가능한 이유는 스타크래프트 게임이 action space가 크기는 하지만, discrete action space를 갖고 있기 때문이다)
이 글은 DeepMind사가 개최한 프로게이머와 스타크래프트 대결 행사 소식과 그 결과(10:1승)를 보고 관심이 생겨 관련 자료와 논문을 보고 적고 있지만, 이와 비슷한 시도를 해본 사람도 발견할 수 있다. 그렇지만 그 결과는 만족스럽지 않았다. 아쉽게도 내가 알기로 현재까지 OpenAI나 DeepMind는 각자의 RTS게임 정복 알고리즘을 공개하지 않았다. 스타크래프트 환경에서 DeepMind AlphaStar가 압승을 거두었지만, 접근 가능한 정보가 프로게이머보다 AI가 더 많고, 결정적인 순간에 인간의 물리적 능력보다 더 빠르고 정확히 action (APM, Actions per Minute)을 수행할 수 있다는 점에서 AI 알고리즘만으로 승리한것이 아니라는 비판도 있는것이 사실이다.
RL을 수행하기 위해서 가장 먼저 필요한 것은 Agent의 action 종류를 정의하고, Environment로부터의 학습에 필요한 정보를 규정하며, 마지막으로 reward structure를 구성하는 것이다. 즉 observation space, action space, reward structure를 정의하여야 한다. 이러한 작업이 없으면, Agent brain을 학습시킬 수 없다. 이러한 작업을 DeepMind(w/ Blizzard)가 대신해서 공개하였다. SC2 인공지능 개발용 python API를 공개하고, 스타크래프트 게임과 interface가 가능하도록 적어도 2개의 space (observation, action)를 정의하고 python을 사용하여 정보를 주고 받을 수 있게 하였다(PySC2). 여기에 더해, 게임환경을 단순화 시키고 승패만을 보는 reward보다 학습에 유용한 Blizzard reward를 주는 작은 게임환경도 함께 제공해서 기초적인 학습을 시도해 보는 공간을 제공하였다. 특이한 점은 게이머들의 실제 플레이를 저장한 replay 팩을 언급하였다는 점이다. 이것은 스타크래프트가 바둑게임과 같이 아무런 reference가 없는 상태에서 수 많은 roll-out만으로 학습가능하기는 어려우므로, imitation learning등의 supervised learning이 필요하다는 판단때문일 것이다.

Observation space
PySC2 github자료를 다운받아 돌려보면 아래 그림과 같은 화면이 나온다. 이것은 스타크래프트를 할때 우리가 보는 화면(RGB pixel)과는 다른 모습인데, 학습을 위해 필요한 다양한 정보(feature layers)를 보여준다. 실제 이 feature layer들을 “screen”과 “minimap”으로부터 필요한 정보를 종류별로 layer형태로 feature layer를 만들어서 RL의 input인 observation의 하나로 사용하며, 게임의 원화면은 사용하지 않는다. 이외에도 다양한 위 그림에서 일례를 보인바와 같이 non-spatial 정보들이 observation의 하나로서 사용된다. 하지만, 인간의 플레이는 RGB pixel screen정보만을 의지하기 때문에 feature layer들을 사용하는 것과는 다르다. 결국 feature layer를 사용하지 않고 RGB pixel만의 spatial information을 사용하는 것이 인간과 비슷한 조건에서 게임을 하는 것이므로 앞서 언급했던 대결의 공정성에 관해 2가지의 지적사항중 하나를 해결하는 것일 것이다. 그러나, RGP pixel만으로 정보를 추출하려면 CNN구조가 신경망에 포함되어 있어야 할것이며 학습이 더 어려울수 있다.

Action space
Action space를 만드는 일도 간단한 일은 아니라는 생각이 든다. 사실 코드로는 무슨 action이든 한꺼번에 처리할 수 있다. PySC2에 공개된 scripted_agent.py의 code를 보면 어떤 형태로 action space가 이루어지고 실행시키는지 알 수 있다. 그러나 공정한 게임을 위해서는 되도록 사람이 하는 플레이에 유사한 형태로 만들어야 한다. 사람이 하는 플레이와 유사한 action space를 가진다는 점을 설명하기 위해 논문에서 사용한 그림이 있다. 이 이미지를 보면 인간이 플레이를 하는것과 유사한 action을 단계적으로 하도록 Agent의 action space를 구성하였다. 하지만 완전히 1:1로 같은것은 아니다. action.FUNCTION() 형태로 action이 주어지기 때문에 함수 형태이고 복수의 물리적 action을 하나의 action함수로 만들어 놓은것이 없지는 않지만 최대한 인간의 플레이와 비슷한 action space를 가지도록 하였다. pysc2에는 총 541개의 action function이 정의되어 있다. 이것만으로도 우리가 일반적으로 다루는 RL환경의 action space와는 비교가 안될 정도로 많다. 게다가, 이중에는 별도의 argument가 필요한 action도 많으므로(13개의 action argument type이 있다, 예를 들어 type[0]는 screen coordinate, type[1]은 minimap coordinate, type[3]는 queed action을 의미한다.), 이 모든것을 감안하면 policy를 설계하는데 특별한 노력이 필요하다는 것을 짐작할 수 있다.

미니게임
앞서 설명한 바와 같이 한번에 이 복잡한 게임을 학습시키기에는 무리가 있다. 그러므로 미니게임 형태로 간단한 task와 reward로 만들어진 mini-game map이 제공되었는데, action space가 작으므로 간단한 테스트로 사용하기에는 안성맞춤이나, 실제 스타크래프트와는 너무 다르므로 현실감이 떨어지는 것은 사실이다. 어떻게 보면, OpenAI나 Unity의 RL용 간단한 environment 정도라고 생각해도 좋다. 보다 흥미로운 mini-game 맵이 많았으면 좋겠지만, 현실감이 있으려면 스타크래프트의 맵중 비교적 간단한 Simple64에서 실제 autobot과 대결 가능하도록 AI가 설계/학습되어야 할것이나, 이 정도가 되려면 사실 필요한 RL기술들이 높은 수준으로 구현이 되어야 가능할 것이다. 비 공개된 DeepMind의 AI를 제외하고 내가 찾은 바로는 이정도의 능력을 보이는 AI 논문을 하나 발견하였다.
강화학습: Baseline Agents
DeepMind사에서 논문에 언급한 기본 RL알고리즘은 A3C이다. Advantage를 사용한 Actor-Critic 알고리즘이므로 policy gradient 방법의 대표적 방법이라고 할 수 있다. 논문에는 policy의 gradient를 표현한 식을 볼 수 있는데, 3개항의 합으로 표현하고 있다. 첫번째는 PG 방법의 일반적 gradient이고 마지막항은 exploration을 강조하는 entropy를 사용한 regularization항이다.
중요한것은 policy gradient로 AI 모델을 꾸미겠다는 시도이고, 이 policy는 모든 action space에 대해 구해져야 한다. 단, action중에 어떤 상태에서 불가능한 action은 masking하여 실제 가능한 action에 대해서만 policy distribution을 구한다. 문제는 action space의 크기이다. 예를 들어 플레이어나 AI가 한 unit을 선택하고 map상의 어느 지점으로 이동시키는 action을 한다고 할때 map상의 position space가 너무 크기 때문에 unit 선택과 position을 모두 고려한 하나의 action으로 표현하려면 엄청난 수의 action space를 요구할 것이다. 이와 같은 일련의 action을 분할하여 표현하겠다는 것이 논문의 의도이며, auto-regressive라고 표현하였다. 일종의 chain rule인 셈이다.

하나의 action에 대한 policy는 그것을 이루는 sub-action들(L)의 확률곱으로 표현한다. 이것을 나름대로 다시 표현하면 sub-action, 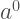

Network Architecture
앞에서는 스타크래프트라는 challenging 목표를 두고 개념적으로 어떻게 접근할것인가에 대한 내용이었다. 여기서는 본격적으로 실제 RL 알고리즘과 신경망 구축방안에 대해 고려하기로 한다.
먼저, observation으로 부터 신경망의 input을 만드는 pre-processing작업이다. 앞서 설명한 feature layers들은 one-hot encoding과 같이 해당 부분만 값을 가지는 형태로 변형하고 non-spatial feature는 logarithmic transformation을 통해 rescaling하였다. Spatial input의 경우는 channel수가 feature layer수와 같은CNN용 input dimension이 만들어 질것이다.
Network의 구조는 policy 함수의 표현 방법과도 연관성이 있는 구조로 만들었다. 즉, action function id를 생성하는 policy와 argument가 생성되는 policy가 함께 성성되는 구조이다. 아래가 대표적인 두가지 신경망구조를 표현한 것이다. 기본적으로 매우 간단 명료하고 현명한 구조라는 생각이 든다. Atari-net구조의 앞부분은 각 feature들로부터 입력을 받아 pre-proceesing 및 feedforward신경망을 거쳐 flatten한 후 이를 모두 합치는 과정이다. 이 결과로 얻은 state representation을 이용해서 advantage를 구하기 위한 value값을 구하고 action function 및 필요한 argument들의 policy를 구하는 구조이다. 그런데, non-spatial action과 non-spatial action policy의 구조가 다르므로 개별적으로 구한다는 것이 주목할 점이다. FullyConv구조는 Atari-net과 비슷한듯 다른 구조를 가지고 있다. 가장 큰 차이는 state representation방법이며, flatten시키지 않고 concatenation했다는 점이 눈에 띈다. 또다른 점은 state representation으로 부터 최종 output을 구하는 방법이다. Spatial action policy의 경우에는 중간 단계로 x 및 y를 구하는 과정이 생략되었고, single output에 대해서는 flatten layer로부터 구하도록 만들었다. 사실 architecture는 이외에도 다양한 조합이 가능할 것이다. 그러나, 신경망에 포함되는 수많은 패러미터는 구조에 대해 큰 차이를 모두 흡수하는 경향이 있으므로 단순한 다른 방식의 조합은 성능에 별다른 차이를 보일것으로 생각되지 않는다.

위 2가지 구조외에 앞서 적은바와 같이 sequential information의 필요성을 고려한 CNN-LSTM구조를 시도하였다고 하는데, 위 그림(b)에서 concatenation 결과로 얻은 State representation을 입력으로 하는 LSTM이 추가되었다고 논문에서는 설명하고 있다.
Results
논문에는 AbyssalReef 맵과 mini-game 맵에서의 performance를 보여주고 있다. 먼저 AbyssalReef map과 같은 full game에서 승/패/무로 표현하는 reward structure에서는 앞의 3가지 구조 모두 단한번도 이기지 못했다고 밝혔다. 그나마, fullyConv구조가 상대적 관점에서 나은것처럼 보이나 어차피 이기기는 불가능한것처럼 보인다. 그 만큼 스타크래프트를 정복하기가 어렵다는 반증이기도 하다. 차선책으로 mini-game 맵들을 사용하여 신경망 구조들을 평가했는데, mini-game에서는 학습하는 모습을 보여주었고 ConvLSTM 우수해 보이기는 하나 유의미한 차이는 아닌것으로 보인다.
Replay and supervised learning
아무래도 아무런 가이드가 없이 스타크래프트를 정복하는 것이 현재로서 무리라면, replay를 이용한 supervised learning을 시도해볼 가치가 있다. 이 논문에서는 supervised learning으로 2가지를 시도하였는데, 하나는 승패를 맞추는 것이고 다른 하나는 action을 예측하는 것이다. 논문에 결과가 나와 있지만 Conv 구조가 AtariNet보다는 나은 성능을 보여 주었다.
테스트
이런 주제에 대해서 나는 습관적으로 직접 결과를 확인하고 싶은 마음이 든다. PySC2 github을 보면 autobot의 hardcoding script를 볼수 있어, 테란종족을 사용하여 hardcode가 잘 동작하는지 확인하였다. 본격적으로 AI player를 만들기 위해 내가 개인적으로 시도해본 방법을 나열하면 이렇다. 한가지 방법에 이틀에서 일주일 정도의 시간이 필요했다.
Action space reduction pysc2의 action space는 개인적으로 테스트해보기엔 너무 dimension이 크다. Action space를 인위적으로 줄이고, actor-critic알고리즘으로 학습이 가능한지 시도해 보았다. 결과는 실패. 주어진 max. step수 내에서 승패가 나지 않는 비기는 경기는 있어도 이기는 결과는 없었다
Hard-coding + Q-learning Action space를 줄이고, Q-learning에 의해 인공지능이 action만 선택하고, 선택된 action에 대해서 hard-coding하여 살펴보았다. 결과는 약 30%의 승률이며, 게임환경은 terran종족으로 스타크래프트 atuobot의 difficulty 수준은 very_easy이다. 수준이 올라가면 이기지 못한다.
Reward shaping Action space를 줄이고, actor-critic을 사용하되, 승패만을 reward로 가지는 sparse reward 구조는 학습이 어려우므로, reward shaping를 시도하였다. 승리를 위해 필요한 action의 결과물에 대해 reward를 부여하였다. 2000번의 게임에서 승리한적이 있지만, 거의 대부분은 패배. 결과적으로 한두번의 승리는 큰 의미가 없는 것으로 판단된다.
Reward shaping + RNN 전략게임은 sequence가 매우 중요한 게임이다. 그러므로 RNN을 도입하여 보았다. 의도는 hardcoding의 역할을 RNN이 대신해 주길 기대했다. 결과는 실패. 학습기간 2000번의 에피소드의 평균 reward는 -0.9845.
Hierarchical RL RTS게임과 같이 복잡한 문제를 해결할 가능성이 있다고 판단되는 것은 “cascade architecture”라는 생각이다. Top level은 일종의 “master policy/brain”이고 bottom level은 일종의 “Slave policy/brain” 역할을 한다. Top level controller를 meta-controller라고 부르며, bottom level controller에게 goal을 부여하는 역할을 한다. 이 구조는 현재 실행중이며, 좀 나아 보이긴하나 희망적이진 않다.
OpenAI나 DeepMind사는 RTS게임을 정복한 알고리즘을 아직 공개하지 않았다.(내가 아는한 그렇지만, 나중에라도 공개되면 좋겠다.) Simple64 맵에서 초보적 수준의 autobot과의 대결에서 이기려고 해도 사실 알고리즘은 완성도는 Deepmind의 그것과 비교해서 크게 떨어지지 않아야 가능한 일일것이다. 이것이 end-to-end learning 알고리즘이라면 대단한 computing power를 가지지 않고서는 학습이 쉽지 않을 것이고 2천번 수준의 게임으로 학습이 가능한것인지 모르겠다. 시도해본 방법들이 개인 PC에서 학습시키기에는 역부족 일 수도 있다. 아직 테스트해 볼 여지가 없지 않으나 state space와 action space를 줄인다 하더라도 multi-agent환경에서 구조적으로 dimension의 저주를 극복하고, sampling efficiency가 좋은 알고리즘, 즉 RL분야에서 현재 추구하는 방향의 성과에 따라 개인 PC에서 학습이 가능한지가 결정될것으로 보인다.
