
인공지능이 이미지를 분석하고 판단하는 일에 매우 뛰어난 성능을 보이며, chatbot에서 짐작할 수 있듯이 자연어 처리분야에서도 뛰어난 능력을 보여주고 있다. 이미지 관련된 능력은 CNN(Convolutional Neural Networks)의 영역이고, 자연어 처리능력부분은 RNN(Recurrent Neural Networks)이 뛰어난 성능을 보여주고 있다. 두 신경망 구조는 인공지능의 비약적 발전에 큰 기여를 한만큼 이 두 구조의 장점을 모두 활용할 수 있는 분야가 이미지나 비디오의 인식 및 서술 (recognition and description)분야이다. 이와 관련하여 가능성이 높은 neural network model을 제시한 논문이 있어서 이를 소개하고자 한다. 이 논문에 특별히 관심을 가지고 포스팅하는 이유는 CNN + LSTM structure가 가지는 잠재력 때문이며, 특히 visual time-series modeling에 매우 뛰어난 성능을 보일 가능성이 있기 때문이다.
Long-term Recurrent Convolutional Networks for Visual Recognition and Description
Introduction
컴퓨터 비전분야에서 연속적인 이미지를 다뤄야 하는 비디오에서 한문장으로 이것을 설명하는 기능을 갖추려면 길이가 변하는 입력과 출력에 대해 단순히 이미지 인식을 위한 ConvNet이상의 기능이 필요하며, 연속적으로 나타나는 이미지를 순차적으로 처리해야 한다. 이러한 역할을 수행하는 네트워크를 Long-Term Recurrent Convolutional Networks(LRCNs)라고 명명하고, convolutional layer와 long-range temporal recursion를 조합한 형태를 가지고 있다. 아래 그림이 이 architecture의 개념을 보여주고 있다.

비디오 프로세싱을 위한 CNNs 연구는 순차적으로 들어오는 데이터에 대해 3D spatiotemporal filter (3차원 시공간 필터)를 학습한다는 개념으로 표현할 수 있다. 이와 같은 개념을 사용하면, RNNs은 시간차원(temporal dimension)의 latent variable의 recurrence라고 볼 수 있으며, “deep in time“으로 개념을 표현할 수 있다. (어휘실력이 미천하여 아쉽게도 적절한 우리말 단어를 선정하기 어렵다. 이 개념을 정확히 이해하려면 CNNs와 RNNs에 대한 기본적 지식이 필요하다.)



RNNs의 시간에 따른 context 정보의 손실을 “vanishing gradient”라고 표현하고, 이를 극복하기 위해 LSTM을 개발하였다고 설명한 바 있다. 위의 그림이 기본적 RNN과 LSTM의 개념을 표현한 그림이다. 이와 관련하여 이 논문의 저자는 아래 그림과 같은 3가지 구조를 예를 들어 설명하였다.
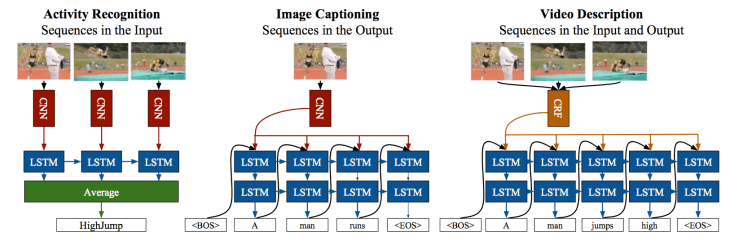
좌측의 architecture는 visual convolutional model을 LSTM networks에 직접 연결하는 구조를 가지고 있으며, 이 video recognition model/architecture는 시간에 따른 상태변화를 감지/인식할 수 있도록 학습시킬 수 있다. 비록 이 구조의 입력이 action이나 activity를 보이는 visual data가 아니더라도 기존의 CNN에 비해 유의미할정도의 성능향상을 관찰할 수 있다.(그림을 보면 일종의 voting system 개념이 포함되어 있다고 생각할 수 있으므로, 충분히 성능 향상을 예상할 수 있다.) 중간에 있는 구조를 보면, 이미지를 문장으로 end-to-end mapping을 하는 형태를 띠고 있다. 이 구조은 LSTM networks기반 encoder-decoder 모델의 구조와 유사하며, visual ConvNets가 deep state vector encoder의 역할을 하고, LSTM networks가 vector decoder역할을 하여 문장(natural language string)을 생성시킨다. 마지막으로는 각 비디오 이미지를 기존의 computer vision method(CRF)로 처리한 후 결과물로 얻은 label을 바탕으로 LSTM에서 decoding을 하는 구조를 오른쪽에서 볼 수 있다.
Long-Term Recurrent Convolutional Network(LRCN) model
위 그림은 LRCN의 개념을 그림으로 표현하고 있으나 여기서는 보다 모델구조를 분명히 설명하기 위해 수학적 표현을 사용하고자 한다. LRCN은 먼저 visual input 




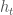


여기서 함수 

위에 그림으로 소개한 3가지의 vision problems (activity recognition, image description, and video description)은 아래와 같은 sequential learning task의 예시라고 할 수 있다.
- Sequential input, static output (class 1, activity recognition) :
.
- Static input, sequential output (class 2, image captioning) :
- Sequential input, sequential output (class 3, video description) :


Class 1 구조에서는 소위 late-fusion approach에 따라 per-time step predictions 





위 모델의 visual 및 sequential parameters인 


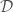

위의 식에서 주목할 점은 parameter의 “end-to-end” 학습이 가능하여, visual feature extractor 의 parameter 


Activity Recognition
Length T sequence를 가진 모든 frame은 하나의 convolutional network에 입력된다. 그러므로 ConvNet weights는 sequence의 전체시간 동안 적용된다고 할 수 있다. LRCN은 매 time step마다 video activity class를 예측하도록 학습하며, 각각의 label prbability를 평균내는 방식으로 video clip전체에 대해 하나의 label을 생성하게 된다.
Image Captioning
Static-image captioning task에서는 하나의 이미지를 input으로 받기 때문에 하나의 ConvNet만 필요하다. 각 time step마다 이미지의 feature와 이전의 단어가 input으로 다음 sequence model인 LSTM으로 전달되고 이 LSTM은 시간에 따라 변하는 output sequence의 dynamics를 학습하게 된다. Training시에는 time step 



ConvNets로 통칭되는 convolutional networks는 종류가 매우 다양하므로 제안한 사람이나 조직의 이름을 붙여 구별하는 것이 관례이다. AlexNet, VGGNet이 대표적이며, 이 논문에서는 AlexNet의 변종인 CaffeNet를 사용하였다고 한다.
Video Description
Video description dataset의 부족으로 전통적인 방식의 activity and video processing 방법을 사용하여 LSTM의 input을 생성하였고, 그 방법은 Conditional Random Fields (CRF) activity recognition 방법이다. 이 방법으로 video 전체 clip에 대한 모든 activity, tool, object, location를 인식하고 이를 입력으로 사용한다. 그러므로, 매 time step마다 video 전체를 참조한다고 할 수 있다. 논문의 저자는 3가지의 architecture를 고려하였는데 아래 그림을 통해 그 개념을 유추해 볼 수 있다.

- LSTM Encoder-Decoder : LSTM을 decoder뿐만 아니라 encoder로도 사용하며, one-hot vector를 생성하는 CRF-max 방법을 사용한다.
- LSTM Decoder (CRF-max) : LSTM은 decoder로 사용하며, 앞 방법과 마찬가지고 CRF-max 방법을 사용한다.
- LSTM Decoder (CRF-prob) : LSTM은 decoder로 사용하며, 앞 방법과 다르게 one-hot vector가 아니라 probability가 그대로 LSTM의 입력으로 사용된다.
결과물 예시 및 결론
저자의 논문에서는 image captioning의 결과물을 제시하였다. 이중의 일부를 아래에 나타내었다. 이미지의 주요 activity, object등을 인식하고 매우 정확하게 사진을 문장으로 묘사하고 있음을 알 수 있다.

LRCN의 의미는 공간 및 시간측면에서 deep network 구조를 가지며, sequential input 및 output을 다룰수 있다는 점이다. 즉 이미지의 sequential dynamics를 학습한다는 것이다. 그러므로 연속적으로 입력되는 이미지를 처리하여 원하는 결과를 얻기 위한 기본적 모델의 원형을 제안하고 있다는 생각이다.

“Recurrent Convolutional Networks”에 대한 답글 1개