그 동안 ConvNets는 주로 2D image 또는 video를 입력으로 사용하여 많은 분야에 활용되었다. 그러나 deep learning과 computation power의 잠재력을 융합한다면 차원을 확장하여 사용할 수 있도록 해준다. 여기서 소개할 논문은 2D convolution대신 3D convolutional networks (3D ConvNets)을 사용하여 시공간(spatiotemporal) feature를 인식하는 방법에 관한 것이다. (여기서 3차원 데이터를 입력으로 사용한다는 것이 3차원 공간 data를 사용한다는 것을 의미하지 않는다. 물론 계산상으로 차이는 없지만, 물리적 의미는 다르다.)
Learning Spatiotemporal Features with 3D Convolutional Networks
Introduction
Video community의 막대한 양의 데이터의 검색, 분류, 추천등을 수행하기 위해서는 사용되는 video descriptor는 다음과 같은 4가지 특성을 가져야 한다고 말한다; (i) generic, (ii) compact, (iii) efficient, (iv) simple. 이 논문의 저자가 개발한 3D ConvNets는 이러한 특징을 모두 가지고 있다. 이방법을 Convolutional 3D (C3D)로 불리운다.
Learning Features with 3D ConvNets
3D convolution and pooling
2D ConvNet와 비교하면, 3D ConvNets는 3D convolution과 3D pooling operations으로 인해 temporal information을 모델링할 수 있다. 즉, 2D ConvNet이 공간적으로만 수행하는 operations을 3D ConvNets에서는 시공간에 대해서 수행할 수 있다. 아래 그림에서 그 차이점을 확인할수 있다. 아래 그림은 하나의 convolution에 대한 개념을 상대 비교한 것이다. 2D convolution은 여러 이미지에 적용되더라도 channel로 인식하기 때문에 하나의 이미지만을 생성시키지만, 3D convolution은 input signal의 temporal information을 보존하고 생성 결과물이 volume형태가 된다.

수학적으로 2D convolution과 3D convolution을 비교하면 더 분명해 진다. 수학적 비교는 아래에 링크된 paper에 잘 설명되어 있다.
3D Convolutional Neural Networks for Human Action Recognition
2D convolution :

3D convolution :

여기서 





저자는 2D ConvNets의 테스트를 통해 3 × 3 kernel size를 가진 deeper architecture가 가장 좋은 결과를 얻었으며, 이 kernel size를 그대로 3D convolution에 사용하였다. Video clip의 size는 



이 논문에서 사용한 network의 구체적 사양에 대해 기술하고자 한다. Input dimensiont은 3 × 16 × 128 × 171이며, 5그룹의 convolutional layers와 5개의 pooling layers, 그리고 2개의 fully-connected layers 및 softmax loss layer로 구성되어 있다. Convolution layer의 filter수는 각각 64, 128, 256, 512, 512개이다. 모든 convolution kernel의 size는 kernel temporal depth, 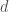

이 논문의 주요 관심사가 temporal information이므로 실험은 kernel temporal depth를 주요 변수로 사용하으며, 두 가지 방식을 채용하였다: 1) homogeneous temporal depth : 모든 convolution layers는 같은 kernel temporal depth를 가진다. 2) varying temporal depth : kernel temporal depth는 layer에 따라 변화한다. 저자는 실험결과 3 depth의 경우가 가장 좋은 결과를 보였다고 밝혔다.
Spatiotemporal feature learning
C3D는 video 분석을 위한 feature extractor로서의 역할을 수행할 수 있다. C3D feature을 추출하기 위해서, video는 16 frame clip으로 분할되고 이중 8개 frame은 다음 clip과 중첩시킨다. 이 clip은 C3D network로 전달되고 FC activation을 거쳐 4096-dimension video descriptor가 생성되고 최종적으로 L2 normalization을 거치게 된다. 이러한 과정을 C3D video descriptor라고 한다. 저자의 설명으로는 C3D의 convolution layer는 초기 몇개의 frame을 통해 전체적인 모습을 잡아내고, 이후 frame에서는 두드러진 action을 추적한다고 한다.
C3D Performance
C3D를 이용하여 video clips으로 부터 시도할 수 있는 3가지 분야에서의 성능 평가 결과를 간단히 제시하고자 한다.
Action recognition
UFC101 dataset에 대해 action recognition task 수행결과를 비교 평가한 테이블을 아래 제시하였다. 저자는 C3D뿐만 아니라 SVM(Support Vector Machine)등을 함께 사용하여 action recognition분야에서 상대적으로 높은 정확도를 보였다. (아래 좌측 테이블 참조)
Action Similarity Labeling
ASLAN dataset을 이용하였으며, 전에 한번도 본적이 없는(C3D training) video에 대해 정확도를 측정하였다. 다른 방법들에 비해 월등한 성능을 보인다. (아래 우측 그래프 참조)


Scene and Object Recognition
Dynamic scene recognition을 위해 YUPENN과 Maryland benchmarks에 대해 C3D를 적용하였다. Imagenet과 비교하여 약간의 성능 향상을 보여주고 있다. (Dataset column의 숫자는 본 논문의 reference로 각 method에 대해서는 원문을 참조하기 바란다)

Conclusion
3D ConvNets을 이용하여 video로부터 spatiotemporal feature를 학습하는것이 가능하며, video 분석을 위한 여러 2D ConvNets에 비해 좋은 성능을 보여주고 있다. 이와 같은 성능의 우수성과는 별도로 덧붙여 언급하자면, video clip을 dataset으로 사용한다는 것은 적지 않은 computation power가 요구되므로 C3D의 compact하면서 simple한 구조는 computation 부하를 줄이다는 관점에서 상당한 장점을 내포하고 있다고 판단된다.
Test run
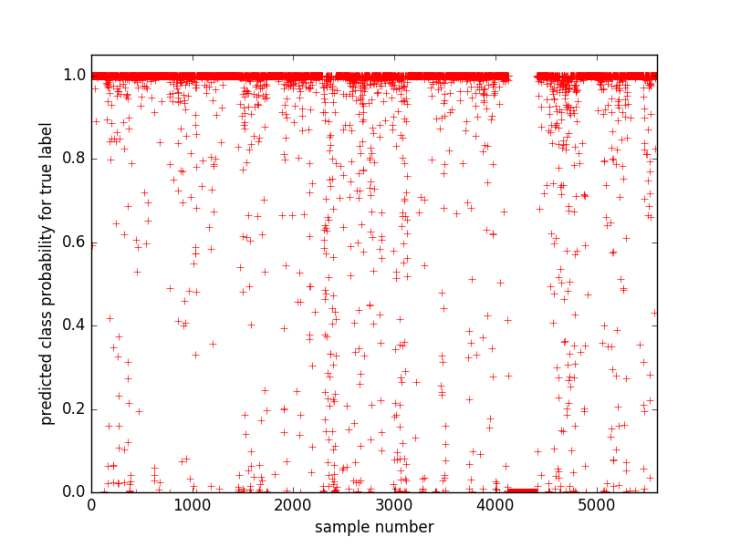
3D convolution의 source code를 구해서 테스트런을 해보았다. 대상은 video dataset UCF101이며,시간상 모든 video clips에 대해 수행하지는 않고 알파벳순으로 “Apply Eye Makeup”에서 부터 “Horse Riding”까지의 video clips에 대해서만 수행하였다. UCF101은 101개의 action class가 있으며, 각 action class에 여러개의 video 자료가 있다. 수행한 test run은 action recognition의 정확도를 평가하기 위한 것이므로 label classification이라고 할수 있다. 즉 “true positive”의 값이 높으면 좋은 성능을 보이는 것이다. 테스트런 결과 얻은 true positive rate는 아래와 같다.
True Positive Rate : 83.5 %
모든 sample에 대해 true label에 대한 예측 확률은 1.0이 가장 이상적이나, label classification의 문제에서 중요한것은 예측 확률의 절대값 보다는 predicted label과 true label이 같아지는 것이 중요하다. True positive는 가장 높은 확률값을 가져서 선택된 action class(predicted label)가 true label과 같다는 것을 의미한다. 아래 그림은 true label에 대해 모델이 예측한 확률값을 나타낸것이다. 대부분의 sample에 대해서 1.0에 가까운 확률값을 보이고 있으나, 확률값이 0.5 이상인 경우 true label과 같은 label을 예측할 것이고 그 이하인 경우 잘못 예측할 가능성이 커진다. 주목할 점은 특정 action에 대해 예측 확률이 매우 떨어지는 것을 볼 수 있다. 이 action은 “hammer throw” 와 “hammering” 으로 서로 상대방 action을 예측하였다. Action 자체가 서로 비슷해서 발생한 것으로 판단된다.