
CNN관련 가장 유명한 자료가 Stanford University의 CS231n강좌이다. 이 강좌는 워낙 유명해서 인지 neural network를 공부하는 사람들이 대부분 참고하는 자료이므로 AI Korea team이 이강좌를 한글로 번역 작업을 수행하였고 그 결과를 아래 사이트에 올려 놓았다. 영어에 문제가 없는 사람은 github에 올라와 있는 사이트를 참조해도 좋다. 같은 내용을 또다시 번역할 필요는 없으므로 추가 설명이 필요한 부분에 대한 설명이나, CNN에 대한 응용적인 측면에 대해 기술 하고자 한다.
CNN/ConvNets은 기존 신경망기술의 성능을 획기적으로 높인 기술이며, 인공지능의 성공 가능성을 널리 인식하게 만든 deep neural network이다. 특히 이미지관련 분야에서 그 성능이 탁월하여 산업에 응용할 가능성이 매우 높다. 그러므로, ConvNets은 입력이 RGB image를 가정하고 만들어진 이론이라는 것을 염두해 둘 필요가 있다. 이 network는 응용적인 측면에서 확장가능성이 매우 크다고 생각해야 한다. 시각정보는 인간이 갖춘 센서중 매우 큰 비중을 차지하는 눈을 통해 받아들여서 뇌에서 처리하는 매우 중요한 정보이며, 인간이 받아들이는 정보의 비중에서 단연 높을 것이다. 이 시각정보을 입력으로 하다보니 응용 분야가 많을 수 밖에 없다.
3D volumes of neurons
CNN의 기본 구성(core building block)은 물론 convolutional layer이다. 이 con. layer는 volume형태이고 width, height, depth를 dimension을 이루는 요소로 사용한다. 여기서 depth는 neural networks에서 layer의 갯수를 의미하는 것이 아니라는 점을 알아야 한다. 이와 더불어 filter라는 개념을 이해하여야 한다. Filter는 convolution이라는 개념이 도입되도록 하는 agent라고 생각해야 한다. Filter는 이미지 정보를 가공하는 agent이고 이 가공된 정보를 activation하여 다음 layer를 구성하게된다. Filter의 depth는 입력 또는 선행 Conv. layer의 depth와 같고, filter를 이미지로 convolve하면서 dot product를 수행한후 activation하여 하나의 값을 얻어내는것이 핵심이다(아래 그림 참조). 이렇게 해서 형성된 새로운 크기의 매트릭스를 activation map이라고 한다. 이때 filter의 spatial dimension(width × height)이 input image 또는 선행 activation map의 local area만을 연결하지만, depth 측면에서는 모두 연결한다는 점이 중요한 개념이다.
Convolve the filter with the image i.e. “slide over the image spatially, computing dot products”
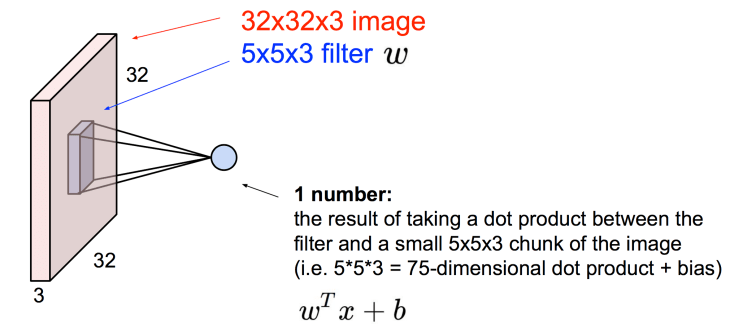
여기서, 만약 6개의 다른 filter를 사용하게 되면 6개의 다른 activation map이 만들어 지게 되며, 아래 그림과 같을 것이다.

이처럼 convolution을 통해 원래의 이미지가 다른 형태로 묘사된 새로운 이미지로 표현(re-representation)되게 된다. 이처럼 새로 표현된 이미지가 다음 layer 처리의 입력이 되는 형태이다. 이와 같은 과정을 여러번 거치게 되면 아래와 같은 형태가 될것이다.
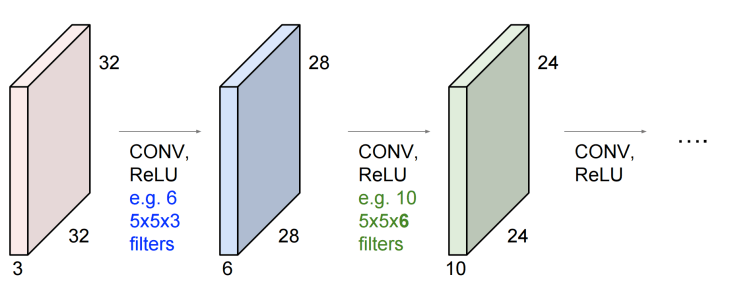
Layers used to build ConvNets
앞서 설명한 바와 같이 ConvNet의 구조는 layers의 시퀀스라고 할 수 있으며, ConvNet의 모든 layer는 미분가능한 함수를 통해 하나의 volume을 다른 volume으로 변환시키는 일을 수행하는 것이다. 이러한 ConvNet 구조를 이루는 layer는 Convolutional Layer(including ReLU), Pooling Layer, Fully-Connected Layer 이며, 이러한 layer들을 쌓아서 하나의 완전한 ConvNet architecture를 완성하는 것이다. Conv layer와 FC layer는 학습시켜야 할 parameter를 가지고 있으나, ReLU와 Pooling layer는 parameter없이 정해진 특정기능만 수행하게 된다.
이와 같은 convolution을 입력 이미지에 대해 수행할때 무슨 일이 일어나는지에 대해 유추해 볼 수 있는 그림이 아래에 표현되어 있다. Convolution을 거치면서 이미지는 입력 이미지의 특징(feature)를 찾아내게되고 이 특징들을 종합하여 최종적으로 입력된 이미지가 무엇인지 알아내는 등의 일을 수행하는 것이다.

ConvNets의 전체적인 구조는 살펴보았으니, 이제는 각각의 layer에 대한 약간의 지식이 필요하다.
Convolutional Layer
Convolution layer의 output volume을 결정하는 요소에 대한 개념이 우선 필요하며, 네가지 개념이 depth, receptive field size, stride, zero-padding 이다.
Depth(K) : 여기서 depth는 filter의 depth(D)를 의미하지 않고, filter의 수를 의미한다.
Receptive field size(F) : Filter의 spatial dimension을 의미한다.
Stride(S) : filter가 spatial dimension을 이동하는 보폭과 같은 의미이다. stride가 크면 filter가 이동하는 보폭이 켜져서 output volume의 spatial dimension이 작아지게 된다.
Zero-padding(P) : 선행 이미지/activation map의 spatial dimension의 가장자리를 zero로 채워주는 것을 의미한다. zero-padding의 size는 output volume의 spatial dimension에 영향을 미친다.
위에 언급한 hyperparameter중 depth는 임의로 정할수 있고, 나머지 3가지의 hyperparameter들의 값에 따라 output volume의 spatial size가 아래와 같은 식에 의해 결정된다.
(W−F+2P)/S+1
Input volume size (W), the receptive field size of the Conv Layer neurons (F), the stride with which they are appled (S), and the amount of zero padding used (P) on the border
이 계산은 실제로 ConvNet을 coding할때 필요하므로 알아 두는 것이 중요하다. Deep learning frameworks마다 약간씩 다른 방식으로 hyperparameter들을 설정한다. 이 parameter를 설정하는 일반적 방법은 한두개의 가정을 도입하는 것이다. 예를 들어, input과 output의 spatial dimension size를 같게 하고, stride를 1로 하게 되면, zero-padding은 P=(F-1)/2에 의해 계산된 값이 사용될것이다. 또하나 주목해야 할점은 위의 식에서 stride로 나누는 연산이 있다는 점이다. 나눈다는 것은 소숫점을 가지는 실수를 계산값으로 낼경우가 생긴다는 의미이고, 이는 결국 정수가 아닌 output spatial dimension값을 계산해 낼것이다. 그러므로 stride에는 경우에 따라 constraint가 존재한다는 것을 함축하고 있다. 이러한 conv layer에 필요한 parameterd의 수는 (F · F ·D) · K 개의 weight와 K개의 biases가 필요하게 된다. 즉, (F · F ·D + 1) · K 개의 parameter가 필요하다. 위에 언급한 네개의 hyperparameter의 일반적 setting값은 다음과 같다.
- (F=3, S=1, P=1, K = power of 2, e.g. 32, 64, 128, 512)
- (F=5, S=1, P=2, K = power of 2, e.g. 32, 64, 128, 512)
- (F=5, S=2, P=?, K = power of 2, e.g. 32, 64, 128, 512)
- (F=1, S=1, P=0, K = power of 2, e.g. 32, 64, 128, 512)
Pooling Layer
It is common to periodically insert a Pooling layer in-between successive Conv layers in a ConvNet architecture에서 주기적으로 Pooling layer를 Conv. layer사이에 넣는 경우가 많은데, 이것의 주 기능은 spatial dimension size를 줄여서 parameter size를 감소시킴으로써, 계산시간을 감소시킴과 동시에 overfitting을 제어하는 것이다. 가장 자주 사용하는 pooling은 stride 2값을 가지고 2 x 2 filter를 사용하는 방법이다. 이 경우 75%의 activation이 사라지는 효과를 가진다. 반면, depth dimension은 변화시키지 않고 그대로 사용한다. 아래는 pooling에 관해 중요한 사항이므로 언급할 필요가 있어서 원문을 그대로 복사해 넣었다.
Backpropagation. Recall from the backpropagation chapter that the backward pass for a max(x, y) operation has a simple interpretation as only routing the gradient to the input that had the highest value in the forward pass. Hence, during the forward pass of a pooling layer it is common to keep track of the index of the max activation (sometimes also called the switches) so that gradient routing is efficient during backpropagation.
Getting rid of pooling. Many people dislike the pooling operation and think that we can get away without it. For example, Striving for Simplicity: The All Convolutional Net proposes to discard the pooling layer in favor of architecture that only consists of repeated CONV layers. To reduce the size of the representation they suggest using larger stride in CONV layer once in a while. Discarding pooling layers has also been found to be important in training good generative models, such as variational autoencoders (VAEs) or generative adversarial networks (GANs). It seems likely that future architectures will feature very few to no pooling layers.
Fully-connected layer
일반적 Neural Networks에서 사용하는 fully-connected layer가 ConvNets에도 사용되는데 이전 layer의 모든 요소를 1차원적으로 연결하는 것이다. 대부분 ConvNets의 마지막 부분에 classifier 의 input으로 사용할 목적으로 사용된다.
Converting FC layers to CONV layers
실제로 FC layer와 CONV layer이 기능적 차이는 존재할수 있지만, 수학적으로는 차이가 없는것과 같다. 모두 입력값과 weight의 dot product에 bias를 더하는 형태로 계산되기 때문이다. 그러므로, FC layer를 Conv layer로 변환시키는것은 어렵지 않은 일이다. 예를 들어 설명하면, 224x224x3 image를 처리하여 7x7x512 convolutional layer를 얻고 이후 4096 size의 FC layer 2개와 1000 neuron을 가진 마지막 FC layer가 있다면 아래와 같이 FC layer를 Conv layer로 변환시킬 수 있다.
- Replace the first FC layer that looks at [7x7x512] volume with a CONV layer that uses filter size F=7F=7, giving output volume [1x1x4096].
- Replace the second FC layer with a CONV layer that uses filter size F=1F=1, giving output volume [1x1x4096]
- Replace the last FC layer similarly, with F=1F=1, giving final output [1x1x1000]
이 방법을 이용하면 매우 큰 이미지에 대해 여러 지점에 대한 ConvNet을 “slide”할수 있는 방안을 제공해 주므로 유용하게 사용할 수 있다(It turns out that this conversion allows us to “slide” the original ConvNet very efficiently across many spatial positions in a larger image, in a single forward pass).
For example, if 224×224 image gives a volume of size [7x7x512] – i.e. a reduction by 32, then forwarding an image of size 384×384 through the converted architecture would give the equivalent volume in size [12x12x512], since 384/32 = 12. Following through with the next 3 CONV layers that we just converted from FC layers would now give the final volume of size [6x6x1000], since (12 – 7)/1 + 1 = 6. Note that instead of a single vector of class scores of size [1x1x1000], we’re now getting and entire 6×6 array of class scores across the 384×384 image.
Evaluating the original ConvNet (with FC layers) independently across 224×224 crops of the 384×384 image in strides of 32 pixels gives an identical result to forwarding the converted ConvNet one time.
Naturally, forwarding the converted ConvNet a single time is much more efficient than iterating the original ConvNet over all those 36 locations, since the 36 evaluations share computation. This trick is often used in practice to get better performance, where for example, it is common to resize an image to make it bigger, use a converted ConvNet to evaluate the class scores at many spatial positions and then average the class scores.

“Convolutional Neural Networks”에 대한 답글 2개