
자율주행차(Self-driving car)가 세간의 화제이다. 자율주행차는 인공지능 응용분야에서 경제적 파급효과가 클뿐더러, 일반인이 인공지능이 우리 생활에 미칠 수 있는 영향을 체감할 수 있다는 점에서 상징적 의미도 큰 프로젝트라고 생각한다. 자율주행 기술은 자동차가 스스로 주행에 필요한 정보를 입력받고 그 정보에 근거하여 주행에 필요한 행동을 인간과 같은 또는 더 나은 수준으로 할 수 있도록 하는 정보처리 및 컨트롤 시스템이다. 컨트롤 측면에서 볼때 인간이 운전중 하는 모든 행위, 즉 주행, 주차, 차선변경, 교통신호 인지, 가속, 감속, 정지등 차동차에 오르는 순간부터 하는 모든 행동을 수행하는 것으로 control의 대상과 목적이 분명하다. 문제는 어떤 정보에 근거하여 많은 컨트롤 action을 어느정도 크기로 수행해야 하는지를 결정하는 정보처리 시스템을 어떻게 설계하느냐가 중요하다. 먼저 올바른 컨트롤을 하려면 해당 컨트롤과 직접적으로 연관이 있는 정보을 입력 받는것이 가장 기초적인 접근방법이다. 예를 들어 주차시 후방 거리측정센서는 후진 추차시 시야에 가려져 있는 물체와 불필요한 접촉사고를 피하려면 거리를 측정하는 센서가 필요하다. 가까워지면 경고음을 울리거나 자동으로 브레이킹을 하도록 하면 간단한 일이다.
하지만, 자율주행을 위해 어떤 정보를 확보해야 하는지에 대해서 우선 생각할 필요가 있다. 기계적 접근방법은 먼저 각종 센서를 생각할 수 있다. 그러나, 자율주행의 가장 큰 핵심은 운전대(steering wheel)의 좌우로 조작하고 가속 및 감속을 위한 gas pedal과 break pedal을 조작하는 일이라고 볼때, 인간이 자동차를 운전할때 이러한 판단의 근거는 대부분 시각정보이다. 이러한 시각정보를 기존의 기계적 관점에서 보면, 정보가 많지 않다고도 할 수 있지만, 관점을 달리 해보면 많은 정보를 포함하고 있다고 할 수 있다. 예를들면, 차선, 앞차와의 거리, 주변환경의 밝기, 비나 눈과 같은 기후환경등의 정보가 담겨있고, 무엇보다도 인간의 두뇌는 시각정보을 주로 이용하여 운전한다는 점을 감안하면 시각 이미지가 가지는 정보의 양이 무척 많다는 것을 가늠할 수 있다. 인간은 이러한 시각이미지만을 이용하여 매우 다양한 판단을 수행하고 적절한 제어 명령을 내리는 것이므로 인간의 두뇌가 얼마나 훌륭한 정보처리 시스템인지 알 수 있다. 기존의 기계제어시스템과 같이 센서에 의해서 필요 정보를 측정하여 자율주행을 하려면 매우 많은 복잡한 센서와 제어기술들이 동원되어야 할것이다. 그러나 그러한 방법이 인간과 같은 주행 능력을 갖출수 있느냐는 문제는 좀 어려운 얘기이다. 그러나 이러한 계측제어기술은 한두가지 측면만을 해결할 뿐 자율주행차를 위한 해결책은 아닐 것이다. 그러므로 기계적 방법보다는 보다 창의적인 방법이 필요하다. 물론 인공지능을 이용하는 방법이다.
구글의 자율주행차는 LiDAR라고 불리우는 장치를 사용하고 레이저를 이용하여 3차원 입체 이미지를 만들어내는 기술을 사용한다고 한다. 우주 항공분야에서 먼저 응용예를 찾을 수 있는 이 장비는, 레이저를 이용해 주변 물체를 모두 3차원 이미지 형태의 정보로 바꾸는 일을 수행한다. 이렇게 만들어진 정보를 인공지능 신경망을 이용하여 처리한 후 주행에 필요한 제어를 하는 것이다. 어찌보면 앞서 설명한 기존의 계측기술을 매개로 사용하여 신경망에 필요한 input정보를 만들어내는 preprocessing같은 것이라고 생각할 수 있다. 즉 계측센서의 데이터를 가공하는 과정이 필요하다는 점이다. 물론 이 센서는 비싸고, 이 센서를 장착한 자율주행차의 가격은 비싸질것이다. 구글의 자율주행차에도 카메라는 필요하다. 주행관련 정보는 라이다에 많은 부분 의존하더라도 교통신호는 봐야하기 때문이다.
그러나 인간이 자동차 운전하는 과정을 생각하면, 눈으로 본 이미지를 운전하는 과정에서 뭔가 복잡한 절차를 거쳐 처리한 후 운전대를 조작하는 것 같지 않다. 시각 이미지는 곧바로 조작명령을 내리는 것으로 보인다. 이처럼 자율 주행 기술이 인간과 비슷한 방법으로 시각이미지를 곧바로 운전에 필요한 행동으로 전환시키는 정보처리 시스템 형태를 갖추는 방법은 없을까 고민하는 것이 창의적 researcher가 생각하는 대안이 될 것이다. 이러한 측면에서 시각정보를 입력받아 주행에 필요한 운전대를 조작하는 명령을 곧바로 생산해 내고자 하는 노력의 결과물을 발표한 논문이 있다. 지금까지 장황하게 서술한 것이 이 포스팅에서 소개하고자 하는 이 논문이 지니는 의미를 소개하기 위한 목적도 있지만, 이 논문의 제목(아래 링크)에 있는 “end to end”의 의미는 우리와 같은 영어생활권이 아닌 나라 사람에게는 영어사전만을 가지고 그 의미를 파악하기 쉽지 않기 때문이다. 쉽게 말하자면 중간의 복잡한 과정을 거치지 않고 주행에 필요한 가장 많은 정보를 내포한 시각정보(one end)를 이용하여 운전핸들조정과 같은 최종 action(the other end)를 곧바로 결정하도록 하는 학습법이라는 의미이다. Nvidia에서 내놓은 이 논문은, 개인적 판단으로 보면, 방법론적인 측면에서 의미를 가진 매우 훌륭한 논문으로 생각하므로 이 논문을 소개하고자 한다.
End to End Learning for Self-Driving Cars
Nvidia은 컴퓨터 그래픽카드에 관심이 있는 사람은 누구나 아는 회사로 원래 컴퓨터 그래픽카드의 칩설계회사이다. 많은 연산이 필요한 3차원 게임을 하기 위해서는 이러한 그래픽카드가 필수이다. 일반적으로 컴퓨터의 가장 비싼 부품은 언제부턴가 CPU에서 그래픽카드가 되었다. 그러나 GPU가 HPC(High Performance Computing)에 사용되면서 과학 및 엔지니어링 분야에서 매우 큰 잠재력이 있는 회사로 발전하였고 , 인공지능연구에 사용되면서 매우 중요한 기업이 되었다. 이회사의 CUDA 및 CuDNN기술은 GPU 를 이용한 deep learning에 매우 중요한 위치를 차지하며, 자율 주행분야 연구의 선두 주자중에 하나이다. 기술의 발전은 회사의 가치를 순식간에 변화시킨다는 점을 실감나게 한다. 개인적으로도, 이미지를 신경망의 input 정보로 이용하는 deep learning을 위해 Nvidia의 GTX 1070을 구매하였지만, TITAN X가 눈에 밟힌다.^^
이 논문의 의미를 전달하기 위해 얘기가 길어졌지만 조금 더 하려고 한다. 이와 비슷한 방법론을 지향하여 현재에도 진행중인 프로젝트가 있다. Udacity에서는 교육 프로그램의 하나로 자율주행차를 개발하기 위해 전세계인을 대상으로 하는 open source project를 진행하고 있다. 이 프로젝트의 핵심은 여기서 소개한 논문과 같이 카메라의 이미지 정보만을 이용하여 자율주행 기술을 개발하고자 하는 것이다. 카메라이 찍힌 이미지는 자동차 운전에 필요한 거의 모든 정보를 가지고 있다고 볼 수 있다. 정밀한 센서를 이용하여 측정하는 몇 cm단위의 정확도가 자동차 운전에 필요한 것이 아니기 때문이다. 시각정보로도 충분히 감지할 수 있는 물체의 위치나 차로의 판별, 대략적 속도 및 거리 감각등이 필요한것이지 전방 30 m에 차가 있는지 31 m에 차가 있는지와 같은 거리측정 정확도가 주행에 필수적인것은 아니기 때문이다. 인간의 두뇌는 이러한 이미지 정보로 부터 실용적 측면에서 필요한 만큼의 물리적 정보를 얻어 내는 뛰어난 정보처리 시스템이다. 인간의 눈에 해당하는 카메라에서 생산해 내는 이미지 정보에서 주행에 필요한 모든 정보를 얻어낸다면, 인간의 운전과 가장 유사한 메카니즘을 자율 주행차가 수행하는 것이다. 안전에 관련된 보조적 장치는 필요할 것이나, 주행과 관련된 기본적 정보는 카메라의 이미지에만 의존하는 것이다.
이 프로젝트은 “교육민주화(democratizing education)”이라는 Udacity의 철학에 걸맞은 프로젝트로 nanodegree 프로그램의 한 프로젝트이다. 여러 다른 MOOC 프로그램과 마찬가지로 교육은 특정인에게만 수혜가 되서는 안된다는 철학을 가지고 있다. 사실 개인적으로도 인공지능기술에 관심을 가진것은 MOOC 프로그램인 Coursera에서 Andrew Ng의 강의를 우연히 접하고서 부터이다.
Introduction
앞서 서술한 바와 같이 이 논문은 이미지로부터 특징(features)를 찾아내는데 탁월한 성능을 보이고 있는 ConvNets을 이용하여 자율주행에 필요한 핸들조작 action을 결정하는것을 목표로 하고 있다. 이러한 접근방법은 10여년전에 Defense Advanced Research Projects Agency (DARPA)의 프로젝트로 추진된 DARPA Autonomous Vehicle (DAVE)에서 시도된 방법이나, 결과는 그다지 성공적이지 못했다. 아래에 DAVE의 개념도를 나타내었다.

카메라로부터 이미지 정보가 시간에 따라 저장됨과 동시에 인간의 운전대 조작 데이터가 Controller Area Network (CAN) bus를 이용하여 저장된다. 여기서 주목할 점은, 차의 형태에 관계없는 시스템을 구축하기 위해 운전조작 정보는 turning radius(


NVIIDA training structure
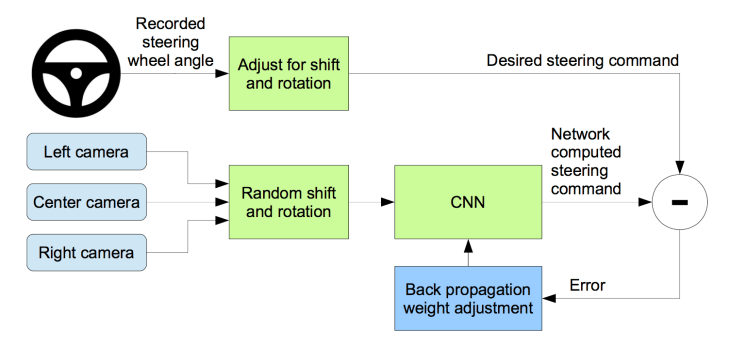
위 그림은 NVIDIA의 training system의 개념도를 나타낸 것이다. 요약하면, 인간의 핸들조작 정보와 카메라이미지를 입력받아 ConvNets를 통해 예측한 핸들조작의 차를 최소화하는 방향으로 학습하는 것이다. 학습이 이루어 지면, ConvNets은 하나의 센터 카메라로 부터 받은 이미지를 사용하여 핸들 조작을 수행할수 있게 된다.
Training data수집을 위해 New Jersey의 여러 종류의 도로(고속도로, 주거지역내 도로, 터널, 비포장도로 등)에서 주행 자료를 수집하였으며, 주행 기후환경을 반영하기 위해 맑은날, 흐린날, 안개, 눈, 비등의 기후조건이 고려되었고, 낮과 밤의 주행환경에서도 데이터가 수집되었다.

위는 ConvNets의 구조를 나타낸 것이다. 총 9개의 layer가 포함되어 있으며, 1 normalization layer, 5 convolutional layers, 3 fully connected layers로 이루어져 있다. 첫번째 normalization layer는 이미지 normalization을 위한것이며, convolutional layer는 이미지의 feature 추출을 목적으로 한다. 이 구조는 Nvidia가 여러 시도를 한 후 경험적으로 설정한 것이라고 한다. 앞쪽 3개의 convolutional layers에서는 5 × 5 kernel을 사용하고 2 × 2 stride를 사용하였으며, 뒤쪽 2개의 convolutional layers에서는 3 × 3 kernel을 사용하고 stride는 사용하지 않았다. 5개의 convolutional layers을 거친후에 3개의 fully connected layers를 거친후 최종 결과물을 계산하는 구조로 이루어져 있다.
Simulation and Evaluation
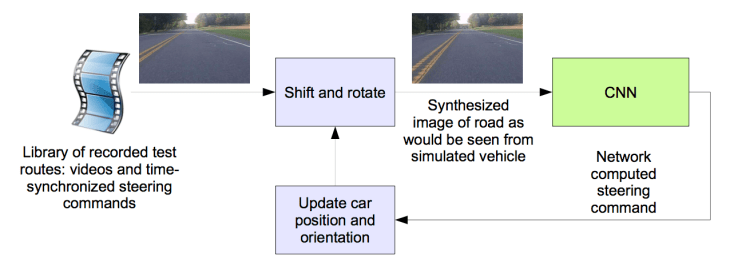
실제 도로에서 주행시험을 하기전에 컴퓨터를 이용한 simulation을 수행하였으며, 개념도를 위에 나타내었다. 실제 인간에 의한 주행으로 얻어진 이미지자료는 항상 자동차 주행차로의 중간으로 달리는 것이 아니기 때문에 보정을 통해 주행 중심을 만들어 내며, 이러한 위치를 “ground truth“라고 부른다. Simulator는 원래 이미지가 ground truth로부터 벗어난것을 감안하여 이미지 변환을 수행한다. Simulator는 off-center distance, yaw, 주행거리등을 저장하고, off-center distance가 1 미터를 넘을 때는 자동차가 ground truth로 리셋되도록 하였다.
ConvNets와 관련하여 학습된 첫번째와 두번째 feature map을 논문에서 제시하였는데, 아래에 추출된 feature map을 도시하였다. 아래에 보인 feature map은 비포장도로에서 얻은 map으로서 도로의 윤곽(outlines of road)를 정확히 추출하는 것을 볼 수 있다.

아래 동영상은 Youtube에 올라와 있는 Nvidia의 자율주행 동영상이다.
Test Run
이 논문의 주제가 자율주행에 필요한 모든 기술을 포함하는 것은 아니다. 안전기술, 사물인식, 위치분석등 많은 기술이 포함되어야 하기 때문이다. 그러나 주행에 가장 중요한 운전대의 조정에 대한 부분을 다룬다는 측면에서 Nvidia의 end-to-end learning의 가능성을 가늠해 볼수 있도록 테스트런을 해보았다. 신경망 구조는 앞서 밝힌 논문의 신경망 구조와 동일하다. 이 논문의 저자가 충분히 실험후 경험적으로 얻은 구조이므로 개인적으로 별도로 테스트를 할 필요성은 느끼지 않았다. 다만, ConvNets구조가 자율주행자동차에 적용하는 최선의 structure는 아닐것이고, 신경망은 앞으로 발전할 여지가 많으므로 ConvNet 자체에 대한 변형보다는 다른 메카니즘을 가진 architecture를 시도할 기회는 많다고 생각이 든다. 다른 architecture를 이용한 테스트런도 시도할 생각이다. 아래는 테스트런결과를 보여주는 주행 동영상이다. 학습초기에는 주행시 인간이 조작하는 운전상황과 오른쪽 인공지능이 조작하는 운전대 회전각도가 많이 어긋난다는 것을 알 수 있다. 아래 Tensorflow의 loss function의 추이를 살펴보아도 학습초기에는 인간의 steering wheel조작과 인공지능의 조작에 많은 차를 보인다. Epoch 4에 이르면 어느 정도 비슷한 조작을 보이지만 인공지능이 약간 과대하게 steering wheel을 조작하는 것을 알 수 있다. 동영상 마지막 부분은 Epoch 30에서 얻은 결과이며, 인간의 운전과 유사하게 인공지능이 steering wheel을 움직이는것을 볼 수 있다. 결론적으로카메라 이미지만으로 ConvNets으로 구성된 인공지능은 steering wheel을 조작할 수 있다는 충분한 가능성을 보여준다.

