
이번 포스팅은 Reinforcement Learning의 Deep Q-Network (DQN)와 연관이 있는 내용이다. 이것은 본질적으로 전에 포스팅한 Recurrent Convolutional Network의 reinforcement learning분야 활용예라고 생각해도 좋을것이다.
DQN을 소개하는 포스팅에서 DQN은 state는 screen image이고 game(environment)의 dynamics을 고려하기 위해 4개의 frame을 사용한다고 언급하였다. 그렇다면, 4개의 frame 정보로 이루어진 현재의 state정보로는 agent의 적절한 action을 결정하기에 정보량이 부족한 경우라면, DQN이 게임을 마스터하기 어려울것이다. 즉, 미래의 state를 정의하기 위해 DQN의 현재 state인 4개의 frame 이상의 정보가 필요한 게임에서는 이것이 non-Markov Decision Process (MDP) 가깝다고 할 수 있다. 이런 경우 이 게임은 Partially-Observable Markov Decision Process (POMDP)가 된다.
Q-Learning & DQN
먼저, Q-learning과 관련된 기본적 이론을 다시 정리하고자 한다. Q-learning의 loss function과 weight parameter update는 다음과 같은 식을 사용한다.

DQN에서 loss function은 다음과 같이 정의 되며, 여기서 

DQN은 state observation이 완전하지 못할때(incomplete) 성능이 저하되므로, Recurrent Neural Network (RNN)의 장점을 활용한다면 DQN이 POMDPs상황을 보다 잘 다룰 수 있을것으로 판단할 수 있을 것이다. 이러한 관점에서 DQN과 LSTM을 조합한 Deep Recurrent Q-Network (DRQN)을 제시한다.
Deep Recurrent Q-Networks (DRQN)
실제문제의 environment와 관련하여, 현재 상태의 모든 정보를 agent가 받을 수 없는 경우가 대부분이고, 상태역시 완전히 정의 또는 규정하기 어려운 경우가 많다. 즉, Markov property가 적용되기 어렵다는 의미이다. 앞서 말했듯이 이런 상황은 Partially Observable Markov Decision Process (POMDP)이고, environment state에 대해 일부분만 관측했다고 인정하는 것이 실제 상황의 dynamics를 이해하는데 더 도움을 준다. POMDP는 





DQN에 recurrency를 도입하기 위해 저자가 사용한 방법은 최대한 DQN구조를 그대로 유지한채 첫번째 fully connected layer만 LSTM layer로 변경하는 것이다. 아래 그림과 같이 convolution layer들의 output은 fully connected LSTM layer로 전달된후, 마지막으로 fully connected output layer를 거쳐 각 action에 대한 Q-value값을 구한다. Convolution및 LSTM parameter는 training중에 통틀어 함께 학습하게 된다.

Stable Recurrent Updates
Recurrent convolutional network를 update하기 위해서는 여러 time step의 게임 스크린의 backward pass 및 target value를 구하는것이 필요하다. Update를 위해 고려한 방법은 다음과 같이 두개의 타입으로 생각해볼 수 있다.
Bootstrapped Sequential Updates: Episodes는 replay memory에서 무작위로 선택되고, updates는 episode 시작시점에서 episode가 끝나는 시점까지 진행시킨다. 각 time step에서의 targets은 target Q-network,
Bootstrapped Random Updates:Episodes는 replay memory에서 무작위로 선택되고, updates는 episode의 임의의 시점에서 시작하여 unroll iterations time step까지만 진행시킨다. 각 time step에서의 targets은 target Q-network,
Sequential updates가 episode 시작점부터 LSTM의 hidden state로 가져갈수 있다는 점에서 장점이 있지만, 하나 전체의 episode를 순차적으로 sampling해야 한다는 점에서 DQN의 random sampling 방법에는 위배된다고 할 수 있다. Random updates방법이 random sampling experience에는 맞는 방법이지만, sequence를 가진 LSTM의 hidden state는 제로로 모든 episode시점에 초기화 되어야한다. 그러므로 LSTM은 오랜 기간 동안의 정보를 반영하도록 학습시키기에는 무리가 따른다. 실제 저자의 실험결과, 두 update방법 모두 비슷한 성능을 보였고, 저자는 무작위 update strategy를 따랐다고 밝혔다.
아쉽게도 이 논문은 구체적 방법론에서 설명이 부족하다는 인상이다. 먼저 replay memory의 존재 목적에 있어서 과연 replay memory가 필요하느냐에 의문이 든다. RNN이 도입되는 순간 존재 목적이 애매해진다. 저자도 이점에 대해 언급을 하고 있지만, replay memory를 사용하는 것이 convolution layer의 안정성에 기여를 한것인지에 대한 언급이 없다. 두번째는 DRQN의 구조에서 convolution layer 그룹이 2개 있는것처럼 보인다는 것이다. Double-DQN이 convolution group이 Target Q와 value Q에 대해 별도의 convolution layer를 사용하긴 하지만 그렇더라도 그림이 이상하다. 결국 코드를 확인하는 수밖에 없었으며, 코드 조사 결과 위의 architecture는 개념을 설명하기 위한 것이지 알고리즘에 반영된 물리적 구조는 아니라는 것을 확인 했다.
DRQN on Atari Game
이 논문 저자의 의도 및 방법론은 이것으로 개념적 설명이 되었다고 생각한다. 이 시점에서 실증을 해야 하는데, Atari game에 적용한 DQN이 POMDP인지 MDP인지를 따져봐야 한다. 결론적으로 저자는DQN에서 사용한 4개의 frame이 가지는 정보는 fully-observable MDP에 가깝다는 판단을 했다. 그러므로 POMDP에 적용하고자 했던 DRQN의 실증을 위해서는 새로운 편법(trick)이 필요했고, flickering Atari game이라는 개념을 도입했다. 이것은 단어에서 암시하듯이 게임 스크린에서 받은 frame 정보가 불완전 하다는 개념이다. 즉, 불완전한 state정보를 주는 것이다. 이러한 상태가 물리적으로 의미하는 바는 물론 물체의 velocity를 가늠하는 등의 dynamics정보의 손실을 의미한다.
주목할 점은, DRQN이 각 time step마다 단지 하나의 frame만 입력 받더라도 잘 작동한다는 점이다. 하나의 frame만 입력받아서는 DRQN의 convolutional layer는 속도를 감지하기 불가능하다. 그 대신 상위층에 있는 recurrent layer가 스크린의 flickering이나 convolution layer의 속도감지의 어려움을 보상한다. 이것을 시각적으로 보여주기 위해 저자는 LSTM layer에서의 이미지 sequence를 보여주었다. 아래 그림은 Pong game에서 3개의 sample episode에 대한 LSTM 이미지 시퀀스이다. 볼의 trajectory가 정확히 표현되어 있는 것을 알 수 있다.

DRQN에서 10 time step에 대해 BPTT (backpropagation through time)을 수행했다. 이것이 물리적으로 의미하는 바는 non-recurrent 10-frame DQN이나 recurrent 1-frame DRQN이 모두 같은 game scree history 정보를 가진다는 것이다. 아래는 DRQN의 architecture와 함께 이 논문의 핵심이 되는 문장이라 생각되어 번역하기 보다는 그대로 인용한다.
“Thus, when dealing with partial observability, a choice exists between using a non- recurrent deep network with a long history of observations or using a recurrent network trained with a single observation at each timestep. The results in this section show that recurrent networks can integrate information through time and serve as a viable alternative to stacking frames in the input layer of a convoluational network.”
DRQN Evaluation on Atari Games
9가지 Atari game에 대해서 DQN과의 성능비교 결과를 제시하였다. DRQN의 경우에는 논문에서 명확하게 밝히지 않았지만 초기 version과 후속 version으로 나누어 결과가 나온것으로 판단 된다. 대게 DQN과 비슷한 성능을 보이고 두개의 게임(Double Dunk, Frostbite)에서는 더 나은 성능을 보인다.

Test run & comments
저자가 개념적인 설명위주로 논문을 썼기때문에 실제 이를 구현하기 위해서는 앞서 설명한 알고리즘 의pseudo code로 설계과정이 필요하다. 기술적으로 tensor들의 정확한 변환과 indexing등이 필요하고, convolutional layer output과 LSTM layer와의 ouput-input 링크과정에 신경써야 하며, LSTM output의 Q value로의 환산 방법도 고려해야 할것이다. Q-learning의 알고리즘도 함께 구현하되, target Q value를 구하고 패러미터 update도 방법도 고려해야 한다. 또한, 이미지 정보가 완전한 현재의 state information을 주면 이 논문의 취지(POMDP)에 맞지 않으므로 부분 정보만 ConvNet에 입력 되어야 한다.
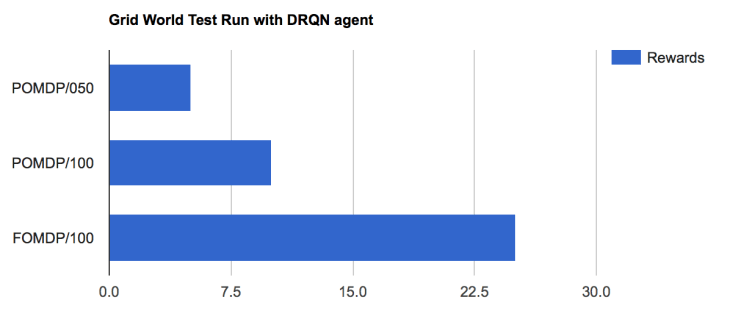
아래는 RL에서 benchmark로 주로 사용하는 grid world environment에서의 테스트런 결과이다. Rewards의 절대값 보다는 상대적 비교가 중요하다. 이 grid world의 episode는 agent movement의 횟수 제한으로 종료되는 형식이다. 특히 reward 및 penalty goal의 위치가 주기적으로 변하는 환경이므로 agent는 environment 환경변화에 대처해야 하는 상황이 고려되었다. 그리고 POMDP observation을 고려하기 위해, 전체 grid world의 1/9만 agent가 인지할 수 있다고 가정하였다. 즉, ConvNet input은 전체 grid world에서 agent가 있는 주변환경의 정보만 전달 받는다.일반적 grid world보다는 매우 어려운 환경이다. 첫번째와 두번째 런은 POMDP환경에서 episode max movement 횟수를 50과 100으로 설정하고 얻은 결과이다. 실제로 이런 환경에서 DRQN이 아니라 DQN을 사용하면 POMDP/50환경보다 1/3수준의 performance를 보인다. 세번째런은 fully-observable환경에서 얻은 결과이다. Markov property를 만족하는 상황이므로 100번의 movement동안 얻은 reward가 대폭 증가한 것을 알 수 있다.
이 알고리즘도 최신것이지만, DRQN이 경쟁해야 하는 알고리즘이 계속해서 나오고 있다. 앞서 소개한 3D convolution network도 하나의 예이다. 인공지능 분야의 알고리즘들이 계속해서 개발되고 있으므로, 이 알고리즘이 좋은 구조를 갖추고 있지만 실용적 측면에서 성공적인 범용 알고리즘이 될 가능성은 미지수이다. 인공지능 분야에서 제안되는 이론들은 다양하게 적용가능하고 진화할 능력(현재까지는 인간에 의해)을 갖추고, 범용적으로 이용 가능해야 하기 때문이다.현재 인공지능 연구가 폭발적으로 증가하면서 현재까지 개발된 주요 알고리즘이 계속해서 진화 발전하고 있으며, 개인적 소견으로는 일년에 한 두개의 강력한 잠재력을 가진 새로운 알고리즘이 탄생하는 것 같다. 그러한 알고리즘이 현재의 CNN이나 RNN정도의 양적·질적 성장을 거치게 되면 어느정도 능력을 보일지 흥미롭다.
