
이 포스팅은 Control with Approximation의 후속편이라고 할 수 있다. 그 포스팅에서 value function approximation의 방법으로 신경망을 사용할 수 있다고 언급한바 있다. 이 포스팅은 그 실례로서, action-value function을 신경망중 하나인 CNN(Convolutional Neural Networks)을 사용하여 Q-value을 예측하게된다. 단 Q-value 예측 방법이 Sarsa method와 같이 on-policy method가 아니기 때문에 off-policy method를 사용한다고 볼 수 있다. 이와 같은 개념으로 신경망을 통한 action-value approximation을 reinforcement learning에 사용한 DeepMind의 유명한 페이퍼가 있다.
DeepMind의 paper(Playing Atari with Deep Reinforcement Learning)에서는 Deep-Q Networks(DQN)을 이용하여 고전게임인 Atari 게임에서 놀라운 성능을 선보인적이 있다. (DeepMind는 Google이 사들인 영국에 본사를 둔 회사로 AlphaGo로 유명세를 탔다. 이 paper도 DeepMind의 유명한 페이퍼중의 하나이다. DeepMind는 좋은 페이퍼를 연속적으로 내놓는 인공지능분야의 선두기업중에 하나이다.)
여기서는 신경망과 RL의 협력이라는 측면에서 중요한 method인 DQN에 대해서 간단한 소개를 하고자 한다. 신경망을 action-value estimation에 사용한다는 아이디어 자체는 내가 판단컨데 수 많은 사람들이 동시에 시도를 했을 것으로 어림짐작 해본다. DQN 아이디어 자체는 특별한 것이 없다손 치더라도 RL의 발전을 위해서는 반드시 실현해야 하는 method였다고 생각되며, 그 아이디어를 현실화하는 과정에서 적지 않은 기술적 어려움이 있었을 것이다. 그러므로, DeepMind의 paper는 RL기술을 다지는 측면에서나 기술적 어려움을 극복하는 여러 tricks들을 제안했다는 측면에서 매우 가치가 있는 페이퍼라고 생각된다. (이글을 작성하는 현재도 RL에 신경망을 다방면으로 활용한 페이퍼들이 계속 발표되고 있다.)
DQN algorithm의 핵심은 Q-learning이다. 그러므로 Q value의 학습이 가장 중요하다. Q value만 학습이 가능하면 다음은 기존 RL과 크게 다를바 없다.(물론 알로리즘의 안정화를 위해 몇가지 trick이 추가되었다). DQN이 사용하는 실제적인 알고리즘은 몇단계로 나눌 수 있다.
State 정의 및 preprocessing
학습을 하는 RL agent의입장에서는 state를 정의하는 것이 매우 중요한 작업이다. State는 agent가 policy에 의해 action을 선택하기 위한 판단기준 정보를 제공하기 때문이다. Atari game에서의 state 정보는 미리 정해진 것이 아니다. 단지 action space만 정의되어 있다. 예를 들어, 핑퐁게임에서는 paddle의 위치 볼의 위치등이 state information이 될것이다. 그러나, 이런 위치정보를 별도로 agent에게 주지 않는다. 만약 정보를 주고 학습하라고 한다면, 인공지능이라기 보다는 게임 컨트롤러에 가깝다고 할 수 있다. Atari game을 environment로 사용하는 경우, state는 게임중 인간이 정보와 같은 것이 자연스러운 것이고, 인간이 비디오 게임중 받는 정보는 주로 시각정보이다. 즉 게임화면 자체가 agent에게 주는 유일한 정보이다. 특히 시각정보중 움직임을 포착할 수 있는 정보가 중요하다. 움직임(trajectory)에 대한 정보는 시간에 따른 위치의 변화로 알 수 있으므로, agent가 받는 시각정보(state정보)는 위상차를 알 수 있는 2개 이상의 frame이어야 가능하다.
DQN paper에서는 게임중 일종의 4개의 screen shot을 state정보로 사용하였다. RGB정보가 Q value 계산에 도움이 되지 않기 때문에 계산의 편의를 위해 이미지 정보를 흑백이미지로 전환하였다. 그렇다손 치더라도 픽셀단위로 서로 다른 이미지를 서로 다른 state로 정의한다면 우주의 원자수 만큼이나 많은 state 수가 될것이다. 그러나 neutral network는 이미지 정보에서 특징(features)를 찾아내는데 탁월한 장점이 있다. 그러므로 neural network를 구축하고 이미지 정보를 입력으로 사용하고 Q-value를 출력으로 사용하는 system을 구축할 수 있다. 즉, neural network를 value function approximation에 사용하는 것이다. 이과정을 그림으로 표현하면 아래와 같다. Q network는 이미지 정보를 state로 입력 받아 action space의 각 action에 대한 Q-value를 구해내는 것이다.

Q-value network는 3개의 convolutional layers와 2개의 fully-connected layers로 구성되어 있다. 보통 CNN에서는 pooling layer와 ReLU와 같은 activation을 사용한다. 그러나 Q-network는 CNN과 닮았지만, 미세한 위치 정보를 잃지 않기 위해 pooling layer를 사용하지 않는 것이 특징이다. 즉, 필요한 정보를 추출하는 것이 더 중요하다.
Q-network weight updates
Q-value의 update는 optimizer를 사용하여 실행한다. Optimizer를 사용하기 때문에 loss function, 즉, objective function을 정의해 줘야 한다. Loss function은 간단히 Q-value 의 target값과 prediction 값의 error를 제곱한 값으로 정의할 수 있다. Regression등 많이 사용하는 squared error 형태이다.

위 loss function를 구하기 위한 기본적인 정보는 하나의 transition 


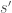

Experience Replay
위에서 잠깐 언급했지만, DQN의 아이디어는 DeepMind만의 것은 아니었을 것이라고 추측해 본다. 그러나, 학습을 시킬 수 있을 정도의 knowhow 확보는 쉽지 않았을 것으로 생각이 든다. 그리고, 학습 시간이 매우 많이드는 algorithm이므로 여러 test run을 하기기 쉽지 않았을 것이다. 먼저 발견된 큰 어려움은 non-linear function을 사용한 Q-value approximation은 안정화가 어렵다는 점이다. 이 점을 해결하기 위해 도입한 것이 experience replay이다. 게임중 얻은 transition 
Target Q network and Q network
DQN에서 사용하는 Q networks는 사실 2개이다. 하나는 target Q network이고 다른 하나는 Q network이다. 후자는 당연히 있어야 하는거지만, target Q network를 별도로 두는것이 특징이다. 두 networks는 weight parameter만 다르고 완전히 같은 network이다. DQN에서는 수렴을 원활하게 시키기 위해 target network는 계속 update되는 것이 아니라 주기적으로 한번씩 update하도록 되어 있다.
Optimizer
Adaptive learning rate method인 RMSProp method를 optimizer로 사용하였으며, parameter의 gradient 변화에 따라 learning rate를 조절하는 방법을 사용하였다. 이것이 의미하는 바는, training set 
Deep Q-learning Algorithm
원 paper에 실린 DQN의 screen shot과 algorithm을 아래 나타내었다. 위에서 설명한 내용을 그대로 적용되어 있는것을 알 수 있다. 논리적으로 복잡할 것은 없으나, 기존의 RL algorithm보다는 부가적으로 필요한 작업들이 많은 것이 특징이다. 이 알고리즘의 장점은 거의 모든 Atari game에 거의 아무런 수정없이 적용 가능하다는 점이다.


Test run
DQN을 reinforcement learning algorithm으로 사용한 테스트런 결과를 아래 추가하였다. DQN은 많은 양의 state 정보(이미지)를 처리하고 CNN을 통한 value function approximation과정이 필요하므로 학습시간이 많이 필요한 알고리즘이다. 하나의 에피소드를 끝내는데 걸리는 시간으로 판단컨데, 나의 맥북으로 DQN을 학습시키기는 너무 많은 시간이 필요하므로, GPU를 하나 구입하여 학습시켜본 결과이다. 클러스터 컴퓨팅이나, SLI multi-GPU가 아니더라도 하나의 GPU만으로도 작은 사이즈의 이미지를 사용한 DQN은 충분히 빠른 시간내에 학습이 가능하였다. 사용한 GPU는 Nvidia GTX 1070(8 GB)이다. 참고로, 나의 데스크탑 컴퓨터에 장착된 기존 비디오카드인 GTX 650Ti는 이미지 처리를 위한 video memory가 너무 작아서(

“Deep-Q Network (DQN)”에 대한 답글 3개