
이 포스팅은 action value function 
Episodic Semi-gradient Control
Semi-gradient prediction method를 action value에 곧바로 적용가능하다. Action value function의 approximation은 무작위 sample에 대해 state 




![]()
이 update rule이 one-step Sarsa method에 적용되면 다음과 같다.

이러한 method를 episodic semi-gradient one-step Sarsa라고 한다. Policy가 변하지 않는 경우, 이 방법은 TD(0)와 같은 방식으로 수렴하게 된다.
Control method가 되려면, 이러한 action-value prediction method와 policy improvement 및 action selection 기법과 엮여야 한다. Action space가 continuous space인 경우에 적용가능한 기법은 아직까지 확실한 해결책이 없으며 연구가 진행되고 있다. 반면에 action set이 discrete하고 너무 크지 않다고 한다면, 이미 전에 언급한 많은 control methods를 그대로 적용할 수 있다. 즉, 현재의 state 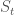





n-step Semi-gradient Sarsa
앞서 설명한 one-step semi-gradient Sarsa method를 응용하여 n-step return을 update target으로 사용하는 n-step version을 생각할 수 있다. n-step return은 아래와 같이 쓸 수 있다.

그러므로 n-step update equation은 다음과 같다. 이 방법의 pseudocode도 역시 나타내었다.


위 알고리즘을 보면 실제로 n-step semi-gradient Sarsa update는 episode가 n-step보다 많은 경우에 대해서만 이루어 지는 것을 볼 수 있다.
Average Reward : A new Problem setting for Continuing Tasks
우리가 Markov decision problem을 정의하면서 episodic discounted setting을 사용한것 처럼, continuing problem에서는 average reward setting을 사용한다. 이 setting에서는 discounting을 고려하지 않는다. 즉 delayed rewards에 대해서 immediate reward와 같은 비중으로 고려한다. Average setting은 dynamic programming classical theory에서는 고려되었으나 reinforcement learning에서는 자주 고려되지 않았다.
Average-reward setting에서는 policy 

State state distribution 

Average-reward setting에서는 return은 reward와 average reward의 차(difference)를 기준으로 아래와 같이 정의 된다.

이것을 differential return이라고 하고, 같은 방식의 value function을 differential value function이라고 한다. Differential value function도 Bellman equation을 가지며, 단순히 


TD error에 대해서도 differential form이 아래와 같이 존재한다.

여기서, 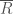

![]()

Q-learning with Value Function Approximation for Mountain-Car Task
이 포스팅의 주제인 action-value function을 추정하는 방법을 Q-learning에 도입하여 RL 문제를 해결하는 방법의 적용예제로 Mountain-Car task가 있다. 이 task는 power가 부족한 자동차가 가파른 산길을 운전해 올라가는 것이다. 어려운 점은 중력이 자동차 엔진보다 더 강하게 작용해서 최대토크를 사용하여 올라가도 곧바로 가파른 경사를 올라 갈수 없다는 점이다. 유일한 해결책은 차를 목표지점의 반대방향으로 먼저 움직인다음 다시 최대 토크를 이용해서 가속을 하는 방법으로 관성모멘트를 최대화시키는 방법이다. 이것은 continuous control의 간단한 예로서 목표에 가까워 지려면 먼저 더 나쁜 상태로(목표에 더 멀어져야한다.) control해야 한다. 이런 종류의 문제는 대부분의 control 방법들이 해결에 어려움을 겪는다.

차가 산정상에 있는 목표지점을 통과하기 전까지 모든 time step에서 reward는 -1이다. 세가지 action이 정의될 수 있는데, full throttle forward(+1), full throttle reverse(-1), zero throttle(0)이다. 차동차는 간략화된 물리법칙에 따라 움직이며, 관련된 정보는 wiki에 잘 정리되어 있다. 이 문제의 특징은 state space가 continuous space라는 점이며 position과 velocity가 continuous variable이다. 그러므로 state space은 2-dimensional이다. 아래는 Sarsa-learning과 RBF approximation을 사용하여 얻은 결과이다. Cost-to-go function은 한 episode동안 얻어낸 

Note) 본 포스팅은 Sutton과 Barto가 공저한 Reinforcement Learning : An Introduction을 기초로 작성된것이다.

“On-policy Control with Approximation”에 대한 답글 1개