
이번 포스팅은 RL분야에서 최근 대두되는 알고리즘을 소개하고자 한다. 이전 포스팅들은 action-value function을 기반으로 하여 학습을 하는 알고리즘이었다. 즉, action-value를 통해 간접적으로 policy가 결정되는 형태이다. 이번에 소개할 알고리즘은 value function을 구하지 않고도 action을 선택할 수 있는 parameterized policy에 관한 것이다. Value function이 policy weights를 학습하기 위해 여전히 사용될 수도 있지만 action을 선택하는데는 필요하지 않다. 우리는 policy를 구하는데 관심을 둘것이므로 weight parameter는 아래 수식과 같이 policy function용으로 사용될 것이다.

Value function을 추가로 학습하는지에 대한 여부와는 상관없이 이러한 방식을 따르는 모든 methods를 policy gradient methods라고 한다. Policy와 value function을 모두 학습하는 methods를 actor-critic methods라고 하며, 여기서 actor는 학습한 policy를 의미하고, critic은 학습한 value function(일반적으로 state-value function)을 지칭한다. 먼저 episodic case의 경우 performance는 parameterized policy하에 start state의 value라고 정의할 수 있다:

Continuing task의 경우는 average value를 사용하여 다음과 같이 정의 할 수 있을 것이다.

위와 같이 performance function이 주어지면, 우리가 할일은 이러한 performance를 최대화 시키는 policy parameter 

여기서, 
Policy Approximation and its Advantages
Policy gradient methods에서, 

만약 action space가 discrete(이산)이며 크지 않다면, 자연스러운 방식의 parameterization은 각 state-action pair에 해당하는 parameterized numerical preferences 

정의된 preference는 어떤 형태로든 parameterize 가능하다. 예를 들면, Deep-Q-network system에서와 같이 

action preference에 softmax함수를 사용하여 action을 선택하는 것의 장점은 approximate policy가 determinism에 접근한다는 점이다. 반면에 action value을 기반으로한 

Policy Gradient Theorem
앞에서 policy parameterization 방법을 위한 performance를 정의하면서 true value function 
이점을 보다 명확히 정의하기 위해 policy gradient theorem이 도입되었는데, 이 theorem은 이론적 수식으로 performance gradient와 policy weights, value function과의 관계를 규정해 놓은것이며, 아래와 같다.

여기서, gradients는 policy weights 성분에 대한 편미분항으로 이루어진 column vector이다. Episodic case에서 
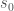


이제 policy gradient를 보다 실제적인 응용을 위해 더 깊게 생각해 보자. Policy gradient theorem은 gradient ascent algorithm에서 필요한 performance gradient를 정확히 수식으로 표현해주고 있다. 이제 우리가 필요한 것은 sampling을 통해 얻은 기대치가 이 수식과 같거나 또는 근사치를 주는 어떤 방법을 찾아내는 것이다. Policy gradient theorem의 오른편은 policy 


이와 같은 과정을 action에 대해서도 시도해 보자. 위 식의 나머지 부분은 action에 대한 합이며, action 선택확률을 가중치로 사용될것이다. 그러므로 이 확률을 곱하고 나누는 작업을 수행하여 다음과 같이 위 식을 변경시킨다.

위식에서 value로는 어떤 것이든 사용 가능하다. one-step reward (r)이 사용될 수도 있고, long-term reward 또는 accumulated reward등이 사용될 수 있다. 위의 식 유도에서 vector 


Softmax policy는 deterministic action space에 알맞는 policy이다. Action space가 continuous인 경우에는 Gaussian policy가 더 자연스러운 선택이 될것이다.
REINFORCE : Monte Carlo Policy Gradient
위의 performance gradient를 policy gradient의 함수로 정의하는 것은 정확히 우리가 원하는 형태이다. 각 time step에서 sample를 통해 얻은 quantity의 기대치는 gradient와 비례한다. 이것을 gradient ascent algorithm에 적용하면 다음과 같은 update를 얻을 수 있다.

이 알고리즘을 REINFORCE algorithm이라고 한다. 이 update rule을 살펴보면, 변화량은 return 
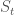

주목해야 할 점은 REINFORCE algorithm은 episode가 끝나는 최종 return값을 사용한다는 점이다. 이런 의미에서 REINFORCE는 Monte Carlo algorithm이라고 할 수 있다. 아래는 REINFORCE algorithm의 pseudocode이다.

하나의 episode를 이용한REINFORCE update는 performance gradient와 같은 방향이다. 그러므로, 충분히 작은 α를 사용하면 진전이 확실히 일어나면서 local optimum에 수렴한다. 그러나, Monte Carlo method로서의 REINFORCE는 큰 variance를 가질 수 있고, 학습속도 저하가 일어날 수 있다.
REINFORCE with Baseline
Policy gradient theorem은 임의의 baseline인 

Baseline은 이것이 action 

그러나, 우리가 policy gradient theorem을 expectation과 update rule로 전환하다보면, baseline은 update rule의 variance에 지대한 영향을 미치게 된다. Baseline을 포함한 새로운 버전의 REINFORCE update rule은 다음과 같다.

일반적으로 baseline은 update의 예상 value를 변화시키지 않지만, variance에는 큰 영향을 미치게 된다. 어떤 states에서 모든 action이 모두 큰 value를 가지게되면 작은 value를 가진 state와 차별화하기 위해 큰 baseline이 필요하다. 모든 action이 작은 값을 가지는 state에서는 작은 baseline이 필요하다. Baseline을 정하는 자연스러운 방법은 state value 


policy 및 value update에는 step size parameter가 포함된다. policy의 step size parameter는 어떤 의미를 가질까 의문이 들것이다. 이 값이 크면 policy가 더 적극적으로 action probability를 바꾼다는 의미이므로 greedy policy와 같이 움직일것이다.
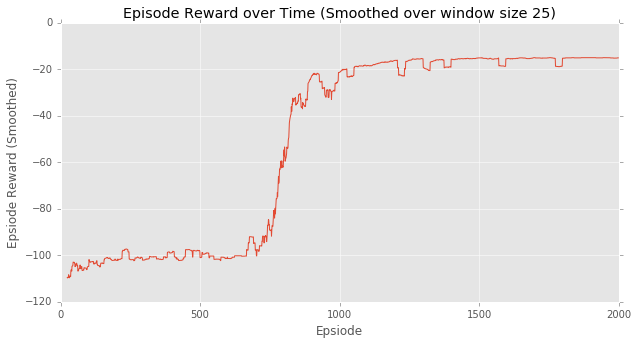
REINFORCE with baseline for Cliff-walking task
이 Cliff-walking task는 이미 TD methods 포스팅에서 다룬바 있다. 같은 task에 REINFORCE algorithm을 적용하여 얻은 결과를 아래 나타내었다. 앞서 언급한 바와 같이 Monte Carlo based policy gradient method는 variance가 크다.
Note) 본 포스팅은 Sutton과 Barto가 공저한 Reinforcement Learning : An Introduction을 기초로 작성된것이다.

“Policy Gradient Methods”에 대한 답글 2개