
이 포스팅은 policy gradient methods에 이어 RL에서 매우 중요한 methods에 대해 소개하고자 한다. 이전 포스팅에서 잠깐 언급한 actor-critic method에 관한 것이다. 먼저 소개한 REINFORCE-with-baseline method는 policy 및 state value function을 모두 학습하지만, 이것을 actor-critic method라고 하지 않는 이유는 state-value function이 baseline에만 사용되고 critic으로서 사용되지는 않기 때문이다. 즉, 이것은 bootstrapping에 사용되지 않고 baseline으로만 사용된다. Bootstrapping을 통해 도입되는 bias는 혜택도 함께 가지고 있는데, variance를 줄이고 학습속도를 가속시킨다.

Actor-critic methods는 위 그림과 같이 value function과 policy를 다루는 별도의 구조를 가져야 하므로 value function과 별도로 policy를 위한 메모리 구조를 가지고 있다. Policy structure는 action을 선택하는데 사용되기때문에 actor라고 하고, value function을 구하기 위한 value estimator는 선택된 action을 평가하는 역할을 하므로 critic이라고 한다. Critic은 actor가 따르고 있는 policy에 대해 비평을 해야하므로 학습과정은 항상 on-policy라고 할 수 있다.

Baseline를 가진 REINFORCE는 bias가 없고(unbiased) 점차 local minimum에 수렴하지만, 모든 Monte Carlo method와 같이 학습이 느리고(high variance) online이나 continuing problem에 일관성을 가지고 적용하기 힘들다. 한편, temporal difference method는 이러한 문제점을 제거할 수 있고 multi-step methods를 이용하여 bootstrapping 정도를 조정할 수 있다. 이러한 장점을 policy gradient methods에 이용하기 위해 bootstrapping critic을 가진 actor-critic methods를 사용할 것이다.
Actor-critic algorithms은 두개의 parameter set을 가져야 하는데, 하나는 critic이 update하는 action value function을 위한 parameter 

먼저 TD(0), Sarsa, Q-learning과 같은 TD methods와 유사하게, one-step actor-critic methods를 생각해 볼 수 있다. 이러한 one-step methods의 매력은 eligibility trace의 복잡함을 피하면서도, 완전히 online 및 incremental하다는 점이다. One-step actor-critic methods는REINFORCE의 full return을 one-step return으로 다음과 같이 대체한다. 이경우는 baseline을 포함하고 있다고 봐야 한다. 만약 baseline을 포함하지 않는 경우에는 


이 policy update(policy gradient method)와 어울리는 state-value function 학습 방법은 semi-gradient TD(0)이다. 이 algorithm을 위한 pseudocode는 아래에 나타나 있다.

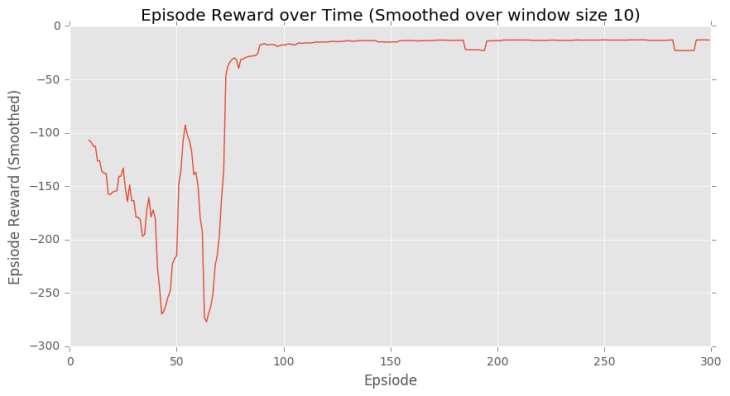
Actor-critic for Cliff-walking task
이 Cliff-walking task는 이미 TD methods 포스팅에서 다룬바 있다. 같은 task에 actor-critic algorithm을 적용하여 얻은 결과를 아래 나타내었다. REINFORCE algorithm을 적용하여 얻은 결과와 비교해보는 것도 흥미로울 것이다. Actor-critic이 보다 좋은 수렴결과를 보이는 것을 알 수 있다.
Policy gradient methods는 value function methods에 비해 잠재력이 큰 알고리즘이다. Policy gradient method의 적용예는 인터넷이나 github등에 많이 올라와 있으므로 쉽게 찾아볼수 있다. 학습을 위한 가장 좋은 자료는 DeepMind의 David Silver의 논문이므로 참고하기 바란다.
Note) 본 포스팅은 Sutton과 Barto가 공저한 Reinforcement Learning : An Introduction을 기초로 작성된것이다.
