
그 동안 Reinforcement Learning과 관련된 글을 많이 올렸고 현재도 관심을 가질 만한 논문이 계속 발표되고 있다. 최근 RL의 대안으로서, 다른 접근방법을 사용하여 RL에 필적할 만한 성능을 보이는 논문이 발표되었기에 이 논문을 소개하고자 한다.
Evolution Strategies as a Scalable Alternative to Reinforcement Learning
Background
RL에서 적절한 action을 규정하는 policy를 구하기 위해서는 value function을 구하는 단계를 거쳐 최적 policy를 구하던지, 아니면 policy를 직접 구하는 방법을 사용하게 된다. 그러므로 neural network는 각 state에 따른 최적의 policy를 구하기 위해 수 많은 parameter(weights)를 조정하게 되는데, 조정의 방향은 reward의 변화에 따라 달라지게 된다. 즉, reward가 증가한다면 유사한 state를 만났을때 사용한 policy를 더욱더 적극적으로 따르도록 parameter를 변화시키고, 반대로 reward가 감소한다면, 사용한 policy를 회피하도록 parameter를 변화시킨다. 이러한 parameter의 변화 방향은 gradient를 먼저 알아야 결정할 수 있으므로, back propagation을 사용하여 gradient를 구하게 된다.
한편, environment의 다양한 상황을 모두 경험하는 것이 agent가 다양한 상황에서 적절히 적당한 policy를 알아낼 수 있으므로, 적은 확률로 agent가 현재까지 알아낸 최적 policy를 벗어나 exploration을 할 수 있도록 설정해 주는 것이 중요하다. 결국, reward는 parameter개선의 방향성만 제시해 주며, agent의 performance향상의 원동력은 exploration을 통해 지속적으로 parameter/weight를 개선시켜주는 것이다. 여기서 소개할 방법은 exploration을 어떻게 할것인가에 대한 글이다.
Evolution Strategies Concepts
이 논문의 ES 소개 section에서 첫문장은, ES 방법이 블랙박스 최적화 알고리즘(black box optimization algorithm)이라고 정의하고 있다. 비유적으로 evolution이라는 단어를 사용한 이유는 진화와 같이 생물에 유리한 방향으로 세대에서 세대로 조금씩 조금씩 우성인자가 많은 방향으로 진화한다는 개념과 유사하기 때문이다. 그런데 이 알골리즘이 최근에 개발된것은 아니며, Rechenberg & Eigen가 1973년에 제안하였고 그 이후 Schwefel에 의해 발전한 것이라고 한다.
앞서 논문의 글을 인용하고 배경(background) 설명을 길게 한 이유는 ES 알고리즘의 이해에 도움이 된다고 판단하기 때문이다. 먼저 배경설명의 parameter 개선 방향성과 진화의 개념은 비슷한 맥락에 있는 개념이다. 결국 policy를 규정하기 위한 수 많은 parameter는 reward를 증가시키는 방향으로 진화해야 하는 것이나, environment에 대한 모델을 알 수 없는 상태인 까닭에 global reward function에 대한 정보 없이 이러한 진화가 이루어 지기 깨문에 블랙박스라는 용어를 사용하는 것다. 한편, 최적화 알고리즘이라고 말하는 것은 reward function이 어떤 형태인지 모르지만 결국 optimization의 기본적 최적화 기법에서 사용하는 parameter search 방법이 동원되기 때문이다. 예를 들어 optimization 기법에는 parameter의 개선을 위한 간단한 방법으로 simplex method가 있는데, 최적화 문제의 해결에 대한 방법론은 결국 더 큰 objective function값을 가지는 방향으로 parameter를 이동시키는 방법에 관한 것이다.
논문에는 ES 알고리즘을 개념적으로 설명하기 위해 최적화 이론에서 사용하는 objective function과 policy gradient method에서 사용하는 score function을 차용하여 설명하고 있다. 앞서 설명한 바와 같이 ES 알고리즘이 선택한 방식이 Monte Carlo Policy Gradient 방법인 REINFORCE와 매우 유사하기 때문이다. 아래와 같은 관계를 이용하여 parameter update를 수행하는 것이다.
![]()
여기서 함수 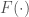


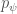
![]()
논문에서는 설명이 없지만, 위의 식은 분산의 개념과 F 값에 대한 가중치의 개념과 정규분포 noise (perturbation)개념이 포함되어 있고, 이를 normalize하기 위한 개념도 포함되어 있다는 것을 인식해야 한다. 이를 종합하여 제시한 ES 알고리즘은 다음과 같다.

위 알고리즘을 살펴보면, 전에 소개한 policy gradient – Pong game에 사용한 개념과 매우 유사하다는 것을 알 수 있는데, 이러한 이유로 논문의 저자는 policy gradient의 개념과 식을 사용한 것이다. Agent가 reward을 받는다면, 그 reward를 받기까지 수행한 모든 action을 선택하도록 유도한 parameter가 강화되도록 정당성을 부여하는 것이다. 위 알고리즘의 4번 라인은 parameter의 perturbation을 통해 다양한 조건에서 reward값을 조사하며, 5번라인에서 reward의 가중평균값과 learning rate를 사용하여 parameter를 update시키고 있음을 알 수 있다. 가중평균치는 ES 알고리즘의 안정성에 도움이 될것으로 판단된다. 이 알고리즘의 큰 특징중의 하나는 back propagation을 통해 gradient값을 구하는 과정이 필요 없다는 점이다.
Parallelizing
이 알고리즘의 특징중 하나는 상호 data transfer의 부담이 없이 수 많은 core를 동원할 수 있다는 점이다. 이러한 특징은 많은 수의 thread/core를 동원하여 빠른 시간내에 학습이 가능하다는 장점이 있다. 특히 하나의 episode는 완전히 독립적으로 수행되므로 각 core에서 수행한 결과를 받아서 parameter update에 사용하며, core간 data sharing을 위한 load가 크게 줄어든다. 이 특징을 논문에서는 강조하고 있으며, 실제 결과를 얻는데 1,440 core/thread를 사용한것으로 밝혔다. 아래는 논문에서 밝힌 알고리즘이다. 여기서 worker는 독립적으로 episode를 processing하는 thread 또는 core를 의미한다. 같이 multi-core를 동원하는 A3C algorithm과 비교해서 훨씬 간단한 알고리즘이다.

Update in action space vs. parameter space
논문에서 강조한 것중 하나는 update 대상에 관한 것이다. 기본적으로 RL에서는 policy의 개선을 목적으로 한다. 즉 action space의 개선을 의미한다. 그러나, policy gradient method를 보면 action에 대한 확률값을 계산하는 형태이지만, 일단 선택된 이후 그 결과물은 deterministic 특성을 가진다. 이러한 면을 설명하기 위해 논문에서는 action space에 따른 reward function 
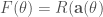
여기서, reward function은 action의 선택에 의해서 결정된다는 점이고 action이 deterministic이라면, F function은 smooth한 연속성을 가질수 없다는 의미이다. 그렇다면 우리가 machine learning에 사용하는 back propagation기법을 사용하는 과정의 편미분 chain rule의 중간 지점에서 불연속 함수를 가진다는 의미가되며, 일반적인 gradient-based optimization algorithm을 사용하기 어렵게 된다. 그러므로 PG에서는 action자체에 대한 noise(

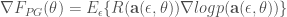
반면에, ES algorithm은 parameter에 noise를 도입한다. 즉, multivariate Gaussian distribution에서 ξ를 perturbation으로 사용하여 


ES is competitive with RL
ES의 성능을 시험하기위해 RL이 강점을 보이는 분야에대해 성능시험을 한 결과가 논문에 실려있다. 비교대상은 DQN, A3C, TRPO등이며, ES 알고리즘의 parallelizing 능력으로 빠른 계산 시간이 강점으로 나타났으며, 상호 필적할만한 성능을 보이는 것을 알 수 있다. 자세한 내용은 논문의 첨부부분을 참조하기 바란다.
Test run
ES algorithm에 의해 optimization 수행과정을 도식적으로 보여주기 위해 간단한 예제 결과물을 아래에 나타내었다. 기본적으로 optimization에서 objective function의 최대값 또는 최소값을 찾는 방법과 비슷한 그림을 얻을 수 있으나, ES 알고리즘의 특징은 각 parameter에 mean값이 0(zero)이고 정규분포를 가지는 noise을 perturbation으로 가지는 다양한 조합의 parameter를 사용하여 많은 sampling point를 이용한다는 점이다(아래 그림이 검은색 점들). 각 포인트로 표현되는 parameter조합 조건에서 하나의 episode를 수행하고 return/reward값을 사용하여, 이 값이 최대가 되는 조건을 찾아가는것이 학습시키는 과정이다. 아래 그림은 2개의 학습해야할 parameter를 가지는 episode의 return값을 color로 나타낸 것이다. x축과 y축은 학습해야할 parameter를 나타내는데, 초기치에서 iteration을 진행할 수록 더 높은 return값을 가지는 영역으로 이동하는 것을 알 수 있다.


다른 초기치/시작점을 가지는 경우의 예를 두번째 그림에서 볼 수 있다. 우리가 바라는 것은 사실 두번째경우에 얻는 최대 return값과 그 결과를 얻어 낼수 있는 parameter들이다. 첫번째의 경우에 찾아낸 최적값은 주변부에 비해서는 높은 극대값을 가지나 전체적으로 볼때 두번째 경우에서 찾은 극대값에는 못미친다. 즉, 첫번째의 경우는 local optimum을 두번째의 경우는 global optimum을 찾은 경우라고 할 수 있다. 이처럼 multi-modal분포를 가지는 최적화 문제에서는 초기치에 따라서 다른 optimum값을 찾는 문제가 발생할 수 있다.
