
이전 포스팅 MCTS에서 큰 search space (또는 state space)에 관한 이야기를 한바있다. 이와 같이 매우 큰 state space를 가진 문제의 경우, 한번도 경험해 보지 못한 새로운 state에 대한 예측능력이 필요하게 된다. 이런 상황에서 대두되는 이슈가 generalization 이다. 즉, 제한된 정보로 학습했지만 폭 넓은 state space에서 좋은 예측이 어떻게 가능할까라는 문제이다. 특히 우리가 관심있는 것은 특정한 목적을 가진 함수(예를 들어, value function)을 일반화하는 것이기 때문에 function approximation에 관련된 것이다.
이 포스팅에서는 주어진 policy 




Value-function Approximation
Backup은 state를 input으로 하고 새로운 value function을 output으로 내놓는 행위이다. 이제는 이 backup을 보다 복잡하고 정교한 방법을 사용하여 수행하고, tabular methods와 같이 일대일 대응의 backup을 통해 하나의 value만 바뀌는것이 아니라 다른 states의 value 예상치도 함께 변경하게 된다. Supervised learning과 같이 input-output관계를 갖되 output이 숫자인것을 function approximation이라고 지칭한다. 이와 같은 관점에서 보면, 그동안 supervised learning에 사용한 많은 방법(예를 들어, neural network, decision tree, multivariate regression)들을 그대로 function approximation에 사용가능하다. 하지만, reinforcement learning에서는 environment나 environment model과 interaction을 통해 on-line learning이 가능한 method가 필요하다. 이를 위해서는 지속적으로 data를 받아 학습이 가능한 method가 요구된다. 특히, reinforcement learning에서는 nonstationary target function을 다룰 수 있는 function approximation이 필요하다.
Prediction Objective (MSVE)
이제 prediction objective에 관해 이야기 할 때이다. Tabular case의경우에는 value function 예측치가 true value function으로수렴하고 특정 state의 update결과는 다른 state 다른 state에 영향을 미치지 않기 때문에, prediction quality를 지속적으로 측정할 필요가 없었다. 그러나 실제 approximation이라고 하면, 다른 state에 영향을 미치며, 모든 state를 정확히 예측하기 불가능하다. 즉, 특정 state의 예측치를 정확하게 하려하면 다른 state의 예측치에 안좋은 영향을 미치게 된다. 그러면, 어떤 state에 더 관심을 기울여야 하는지를 기술하는 것이 필요한데, 이것을 weighting distribution 

이 값의 squared root값 (root MSVE / RMSVE)는 추정치가 실제값과 얼마나 다른지를 나타내는 척도로 사용된다. 일반적으로 



Linera Methods
Function approximation과 관련하여 가장 중요한 special case라고 한다면 approximation function 


위와 같이 linear function approximation을 사용한 SGD update는 value function에 대한 gradient가 간단히 
Linear method는 수렴을 보장한다는 측면뿐만 아니라 데이터나 계산측면에서 매우 효율적이기 때문에 흥미로운 방법이다. 후자는 state를 나타내는 feature의 특성에 따라 달라진다. 주어진 task에 적합하도록 feature를 선택하는 것은 reinforcement learning에 사전 정보를 부가한다는 측면에서 매우 중요한 일이다. 당연한 일이겠지만, task 자체의 특징을 반영한 feature가 선택되어야 한다. 예를들어, 만약 우리가 움직이는 로봇의 state를 대상으로 한다면, location, batter power 상태, 초음파 센서 값등이 feature가 되어야 할것이다.
일반적으로 우리가 원하는 feature중에는 natural quality들의 조합 형태의 feature가 필요한 경우가 있다. 그러나 linear function의 경우 이러한 형태의 feature들간의 interation을 나타내는 표현을 직접 사용하지 못하기 때문에, 이경우 그러한 interaction을 나타낼 feature를 새로 도입해야 한다. 이에 대해서 알아 보기로 하자.
Polynomials
Muti-dimensional continuous state spaces에 대해서, reinforcement learning을 위한 function approximation은 interpolation과 regression과 공통점을 많이 가지고 있다. 그러므로, 이러한 일에 자주 사용되는 polynomials 함수를 reinforcement learning에서도 사용할 수 있다.
d개의 실수 state variable을 가진 모든 state에 대해서 state s는 d-dimensional vector 


Fourier Basis
또다른 linear function approximation방법으로는 time-honored Fourier series를 사용하는 방법이 있는데, 이 방법은 여러 frequency를 가지는 sine 및 cosine basis function의 weighted sum의 형태로 주기함수(periodic function)을 나타내는 방법이다. Fourier series는 다른분야에서도 많이 사용되는데 그 이유중에 하나는 approximation되어야 할 function을 알고 있다면, 많은 basis function을 사용하여 간단한 함수 형태로 거의 모든 함수를 나타낼 수 있기 때문이다. 그러나, approximation되야 할 함수를 모르는 reinforcement learning에서도, 사용하기 쉽고 reinforcement learning 영역에서 우수한 성능을 보여주기 때문에 관심의 대상이다.
기준점(origin)을 가진 state space에 대해서 state는 d-dimensional vector ![(s_1 ,s_2, ..., s_d)^T, s_i \in [0, 1]](https://s0.wp.com/latex.php?latex=%28s_1+%2Cs_2%2C+...%2C+s_d%29%5ET%2C+s_i+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=444444&s=0&c=20201002)

여기서, 

Coarse Coding
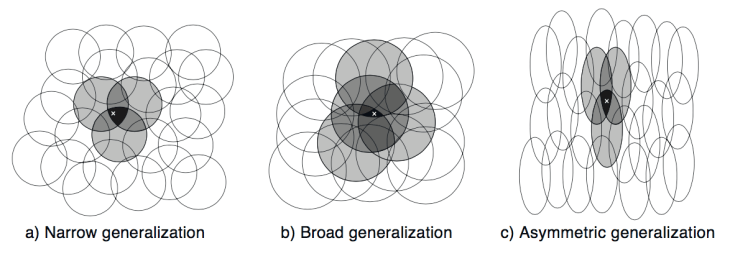
State set이 2-dimensional인 경우 state는 2-space에서 한 점으로 나타나고 2개의 실수 성분을 가진 vector가 된다. Feature는 아래 그림과 같은 원에 해당하며, state가 원내부에 있으며 해당하는 feature은 1의 값을 갖고 존재(present)한다고 하고, 다른 부분은 0의 값을 가지고 부재(absent)라고 표현한다. 이와 같이 1 또는 0 값을 가지는 feature를 binary feature라고 한다. State에 해당하는 원안에 binary feature가 present하면 대략적으로 그 위치를 나타내 주는 것이다. 이러한 방식으로 feature를 사용하여 state를 표현하는 방식을 coarse coding이라고 한다.

Linear gradient-descent function approximation를 가정하여 원의 크기와 밀도의 효과를 고려해 보자. 각 원을 weight
Tile Coding
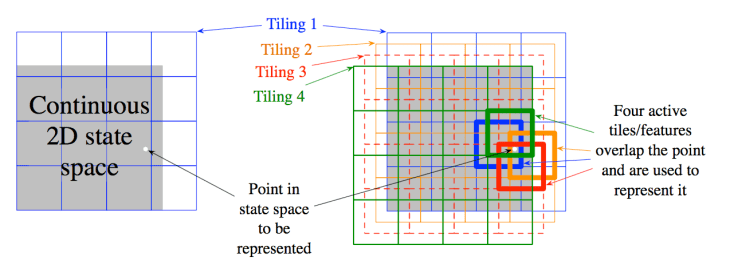
Tile coding은 multi-dimensional continuous space를 위한 coarse coding의 한 형태로 유연하면서도 효율적 계산이 가능하다. 이것은 아마도 순차처리를 하는 디지털 컴퓨터를 위한 가장 실용적인 feature representation이라고 할수 있다. 여러 종류의 tile coding을 위한 open-source software를 이용가능하다.
Tile coding에서는 feature의 receptive fields를 input space의 partition들로 그룹화한다. 그러한 partition을 tiling이라고 부르며, partition의 각 element를 tile이라고 부른다. 예를들어, 2-dimensional state space에서 가장 간단한 tiling은 아래 왼쪽 그림과 같은 uniform grid이다. 여기에 사용된 타일 또는 receptive field는 정사각형태를 띠고 있다. 이러한 하나의 tiling이 사용되면 힌색 점으로 표시된 state는 tile안에 투영되는 형식으로 single feature로 표현될 수 있다. tile coding이 실제 coarse coding이 되기 위해서 여러개의 tiling이 사용되며, 타일 폭의 fraction만큼 서로 offset되어 있다. 네개의 tiling를 사용한 간단한 케이스가 아래 그림에 도시되어 있다. 흰색 점으로 표기된 state는 네개의 tiling 각각의 한 tile에 정확히 투영된다. 이러한 네개의 tile은 그 state가 활성화되면 4개의 feature를 나타내게 된다. Feature vector
Radial Basis Functions
Radial basis functions (RBFs)는 coarse coding을 continuous-valued feature에 적용하여 일반화시킨 것이다. 각 feature가 0 또는 1이아니라 [0, 1]구간의 어떤 값도 가질 수 있다. 대표적 RBF feature는 아래와 같이 Gaussian (bell-shaped) response 



binary feature에 비해 RBF의 우수한 점은 매우 부드러운 approximation fuction을 생성시킬 수 있고 미분가능하다는 점이다. 아래는 one-dimensional radial basis function의 그림이다.

Nonlinear Function Approximation : Artificial Neural Networks
이 블로그의 한 theme인 신경망은 nonlinear function approximation을 위해 널리 사용되고 있다. 신경망은 자체로도 큰 분야이기도 하지만 그 능력으로 말미암아 reinforcement learning분야에서도 강력한 힘을 발휘하고 있다. Reinforcement learning에서 사용된다고 하여 신경망에 대해 다시 기술할 필요는 없으므로 nonlinear approximation과 관련하여 언급될 필요가 있는 것만 잠깐 기술하고자 한다.
신경망은 input, hidden layer(s), output을 가진 기본 구조를 가지고 있다. 하나의 hidden layer만으로도 universal approximation 특성을 가지고 있으나, 경험이나 이론적 면에서 볼때, complex function을 approximating할때 많은 layer를 가진 low-level abstractions의 구조적 조합을 사용하는 것이 많은 인공지능 task를 보다 쉽게 만들 수 있다. 연속된 layer는 input에 잠재해 있는 여러가지 feature들을 표현해 낼 수 있기 때문이다. Reinforcement learning에서는 이 신경망을 value function을 추정하는데 사용할 수 있으며, policy-gradient algorithm에도 사용가능하다. Overfitting은 function approximation에 있어서 일반적인 문제이지만, 심측신경망에서는 많은 수의 weights로 인해 더 중요한 문제이다. 신경망에서 중요한 overfitting 해결방안중 하나는 dropout method이다. Reinforcement learning분야에서 매우 성공적인 사례라면, deep convolutional neural network이다.
Note) 본 포스팅은 Sutton과 Barto가 공저한 Reinforcement Learning : An Introduction을 기초로 작성된것이다.
