
Planning에 대한 두가지 관점이 있다. 지금까지의 관점은 dynamic programing이나 Dyna에서처럼, planning을 모든 state에 대한 policy 또는 value의 점진적 개선으로 보는 것이다. 다른 하나의 관점은 planning의 결과물이 policy가 아니고 action의 결정이라는 관점이다. 여기서는 action 선택으로서의 planning 관점을 살펴보기로 하자.
Planning을 action selection의 관점에서 본다손 치더라도, 우리는 이것을 여전히 전과 같이 simulated experience로부터 backup과 value를 거쳐 결국은 policy로 가는 절차라고 생각할 수 있다. 많은 경우에, 이점을 정보의 손실이라고 생각되지 않을 것이다. 왜냐하면, 많은 state가 존재하는 상화에서는 같은 state로 다시 돌아오기 까지는 대게 오랜 시간이 걸리기 때문이다. Action selection으로서의 planning은 빠른 반응이 필요하지 않은 경우에 유용하다. 예를들어, 체스게임같이 다음 move를 위해 많은 시간이 주어지는 경우이다. 반면에 빠른 action selection이 필요한 경우는 planning을 policy를 계산하도록 하여, 빠르게 이 policy를 사용하도록 하는것이 유리하다.
Heuristic Search
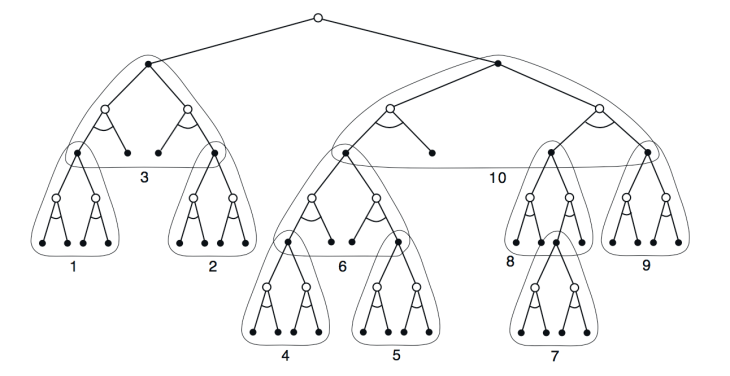
앞서 언급한 planning-as-part-of action-selection method는 인공지능 분야에서 통틀어 heuristic search로 알려져 있다. Heuristic search에서는 모든 state로부터 다양한 가능성의 나무가지가 자라는 형태의 구조가 고려된다. Value function은 leaf node에 적용된 후 root node에 있는 현재 state로 backup이 이루어진다. 이러한 search tree에서의 backup은 max를 가진 full-backup과 같은 개념이다. Backup이 이루어지는 여러 노드중에 최선의 것만 현재의 action으로 선택이 된 후 모든 backup value는 폐기된다.
하나의 step을 넘어 더 깊게 탐색하려는 의도는 더 나은 action 선택을 위한 것이다. 만약 완벽한 모델과 불완전한 action-value function이 있다면 깊은 탐색이 실제로 더 나은 policy를 얻을 수 있다. 만약 탐색이 episode 종료지점까지 간다면 불완전한 value function의 여파는 사라지게 되고, 이런식으로 선택된 action은 최적선택이 될것이다. 만약 탐색이 충분한 깊이 

Heuristic search가 현재의 state에 집중적으로 backup을 수행한다는 점을 간과해서는 안된다. Heuristic search가 가지는 효율성의 대부분은 현재의 state 바로 다음 선택되는 state와 action에 집중된(focused) search tree로 기인한 것이다. 깊은 탐색이 주는 성능의 개선은 많은 step을 backup함으로써 이루어지는 것이 아니다. 이 개선은 현재의 state다음에 오는 action과 state에 집중적으로 backup을 수행하기 때문이다. 많은 계산을 action 후보와 연관된 계산에 집중함으로써, 특정 연산에 집중하지 않는 방식 보다는 훨씬 좋은 결정을 내릴 수 있다. 아래 그림을 보면 현재까지 설명된 focussing의 개념을 볼 수 있으며, depth-first heuristic search를 위한 순서를 주의 깊게 살펴보아야 한다.
Monte Carlo Tree Search
Monte Carlo Tree Search(MCTS)는 policy의 일부분으로서의 planning의 간단한 한 예이다. 이것은 planning분야에서 이루어진 성공적 업적의 하나이며, 바둑(Go)게임의 발전에 큰 기여를 했다. MCTS는 일반적으로 한 time step기준으로 정보가 저장되고 폐기되는 형식으로 value function이나 policy를 추정하려고 하지 않는다. 여기서는, 한 step동안 현재 state로부터 시작해서 많은 simulated trajectory가 생성되어 terminal state까지 진행된다. 대부분의 경우 simulated trajectory의 action은 default policy(균등확률 무작위 policy같은 것)라고 부르는 simple policy를 사용하여 선택된다. 이 policy와 모델은 계산이 어렵지 않기 때문에 짧은 시간안에 많은 수의 trajectory를 만들어 낼 수 있다. Tabular Monte Carlo method에서 처럼, state-action pair의 value는 그 pair로부터 얻을 수 있는 return의 평균으로 예측된다. 가장 간단한 경우, 모든 simulated trajectory는 승/패 결과로 끝나게 되고 이것만 카운트하면 된다. 즉, state를 통과한 모든 simulated trajectory들중에 몇번 승리하였는지를 세는것이다.

Counts(Monte Carlo value estimates라고 할 수 있다)는 위 그림처럼 현재 state에 뿌리를 두고 근접한 state-action pair에 대해서만 이루어 진다. 트리 바깥족 leaf node에서는 action selection을 위한 방편으로 default policy가 사용된다. 그러나, 트리 안쪽 state에서는 더 나은 뭔가를 할 수 있을 것이다. 이 상태에 대해서는 적어도 몇개의 action에 대해서는 value 추정치를 가지고 있으므로, 우리는 이것을 이용한 선택을 할수 있을 것이다. 예를 들어, 
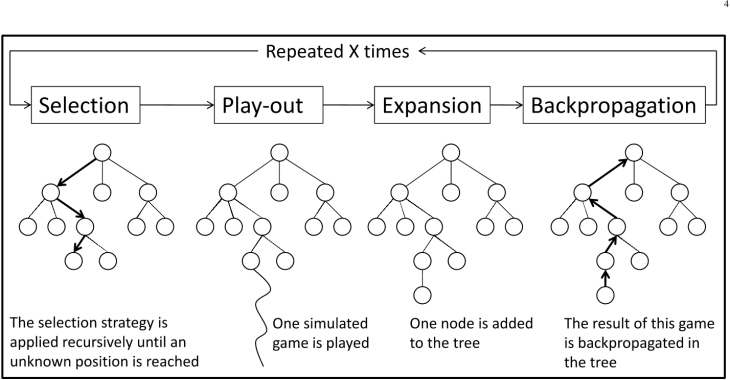
- Selection 주어진 정보를 이용해서 추가적으로 탐색할 가치가 있는 가장 가능성이 있는 하나의 node가 현재 tree에서 선택된다.
- Expansion 선택된 node로부터 가지를 치는 방식으로 한개 또는 몇개의 node를 추가하는 방식으로 tree는 학장해 나간다. 새 가지(child node)는 game tree의 leaf node가 되는데, 그동안 tree를 만드는 과정에서 한번도 시도되지 않은 node이다.
- Simulation 주어진 정보를 이용해서 leaf node들중 하나를 선택해서 simulation의 시작점으로 삼는다. 이로부터 종료시점까지 rollout policy를 사용하여 roll out을 한다.
- Backpropagation Simulated game의 결과는 partial game tree의 링크와 관련된 state 통계의 update를 위해 backup된다.
MCTS는 partial game tree root로 부터 시작하는 이 과정을 지속하게 된다. 그런후에 마침내 그 partial game tree 내부의 축적된 통계자료를 이용하는 어떤 mechanism에 따라 root node의 다음 move를 선택하게 된다. 이것이 프로그램이 실제 게임에서 사용하는 move이다. 상대편의 move가 이루어지면 새로운 state가 생성되고 이 state를 기반으로 다시 선택과정을 거쳐 MCTS를 수행하게 된다.
MCTS for tic-tac-toe game
사실 MCTS는 RL에 대한 배경지식이 없어도 이해가 가능한 알고리즘이다. 개인적으로 MCTS에 대한 기본 개념만 이해해도 coding이 가능한 사람은 충분히 알고리즘을 구현할 수 있다고 생각한다. 2016년 초에 세상을 떠들석하게(?) 했던 AlphaGo도 알고리즘의 근저에는 MCTS가 있다. 이런 형태의 게임중 가장 간단한 게임이라고 하면, 우리나라 사람들이 빙고게임이라고 알고 있는 tic-tac-toe게임이다. 이 게임에 MCTS 알고리즘을 적용한 예를 찾아서 code를 살펴보았다. 그중 가장 핵심이 되는 MCTS의 4가지 단계를 구현한 MCTS function(정확히는 UCT 알고리즘)에 해당하는 code snippet을 아래 실었다. Upper Confidence Bound applied to trees(UCT)는 selection 단계에서 child node를 선택하는 우선순위 판단기준이다. 자세한 내용은 UCT 설명이 포함된 MCTS wiki를 참조하기 바란다. 이처럼 간단한 게임의 경우, 인간이 할 수 있는 최선의 방법은 비기는 것이다. 컴퓨터가 모든 가능성을 다 탐색할수 있기 때문이다.

AlphaGo의 Tree Search를 도식적으로 표현한 이미지는 널리 알려져 있다. 아래 그림을 보면 MCTS의 search algorithm에 기반한 것임을 알 수 있다. 다만 그 많은 경우의 수(afterstates)를 효과적으로 평가·선택하기 위한 이론적 기반과, GPU또는 cluster computing에 기반한 computation power가 뒷받침되어야 할것이다.
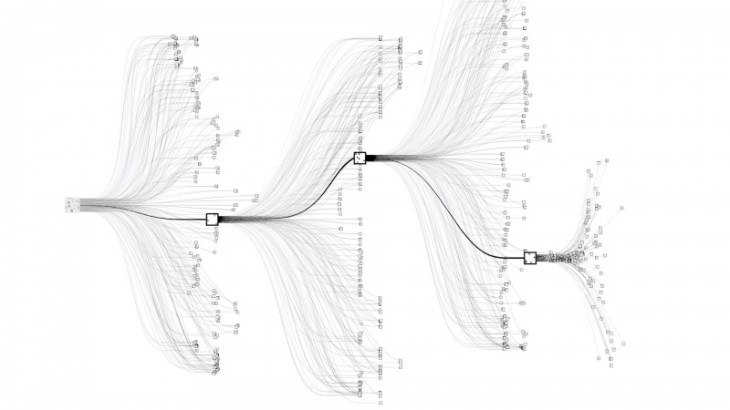
기본적인 MCTS algorithm은 컴퓨터가 모든 가능성에 대해 평가가 가능할때 최고의 성능을 낼 수 있다. 컴퓨터가 모든 가능성을 다 탐색할 수 없는 경우(예를 들어, 바둑)는 기존의 게임프로그램은 수 많은 가능성중 탐색 가치가 있는 tree branch만 선택하여 가치가 없을것 같은 가지는 배제하려 한다. 기존의 게임이론인 minimax algorithm이나 MCTS나 tree branch의 value function의 정의가 가장 중요한 문제이다. 가치판단의 기준이 되기 때문이다. 이 값이 모두 정확하다는 전제가 깔려있다. State value function은 RL의 reward와 비슷한 개념이다. 그렇다면 reward가 잘못 정의되면 어떤일이 벌어질까? 답은 분명하다. 게임 프로그램이 인간의 능력에 한참 못미친다는 평가를 받은 이유는 tree search의 한계뿐만 아니라 value function의 정확한 예측이 쉽지 않기 때문이다. 즉, 모든 가능성에 대해 게임의 종국까지 가서 결과를 봐야 정확한 값을 산정할 수 있기 때문이다. 한편, 잘못된 value function도 볼 수 있다. 예를 들어, 승리와 패배가 있는 게임의 state function은 승리/패배에만 값을 부여하거나 real experience를 통한 승리확률로 값이 부여되어야 한다. (MCTS는 승리확률로 value function이 정의되는것과 같다.) 예를 들어 오목의 경우 3개 연속인 돌에 대해 3점, 네개 연속인 돌에 대해 4점을 부여하는 것이 설득력이 있고 더 훌륭한 게임프로그램을 만들것으로 생각되겠지만, 그것은 아무런 논리적 근거가 없는 것이다. 오히려 게임프로그램을 더 어리석은 프로그램으로 만드는 것이다. 흔히 아무런 전략없이 이런 수를 계속 남발하는 사람을 하수라고 하는데, 이런 하수의 시도에 점수를 부여하는것은 뭔가 잘못된것 아닌가? AlphaGo가 높은 수준의 바둑 인공지능이 된 이유는 보다 정확한 value function의 값을 부여한것이 하나의 요인이라고 할 수 있다. AlphaGo는 오로지 승리여부로 state를 평가한다고 한다. 바둑은 집의 수를 세서 많은 쪽이 이기는 게임이다. 그렇다면, 단순 논리로 집의 수에 근거한 state value function으로 사용하는 것 당연 또는 현명한 판단이라고 생각할 것이다. 그러나 앞서 설명한 오목과 같이 매우 어리석은 판단이 된다. 집의 수가 많은것이 최종 승리와 관련이 없기 때문이다. 집의 수보다는 적더라도 상대방보다 “더 많은” 집(나의 예상되는 집수 – 상대방의 예상되는 집수)이 중요한것이다. 이것도 충분히 설득력이 있는 value function이지만 뭔가 이상하다. 큰차이로 이기는 것과 작은 집수 차이로 이기는 것이 다른 value function을 가질 이유가 있는가이다. 반집승도 승리이고 수십집이나 불계승도 같은 승리이다. AlphaGo는 승리에 더 목적을 둔다고 한다. 더 많은 집차이를 내기 보다는 보다 안전하게 승리하려고 한다는 의미이다. 즉, value function이 보다 합리적으로 정의 되었음을 의미하는 것이다.
기존 이론중 MCTS와 비슷하게 tree구조의 알고리즘이 있다. Minimax algorithm이 대표적인 방법이며, heuristic value나 evaluation value로도 불리는 value function을 기준으로 최적의 다음 move를 찾아가는 방법이다. 이와 더불어 불필요한 tree search를 하지 않기 위해 

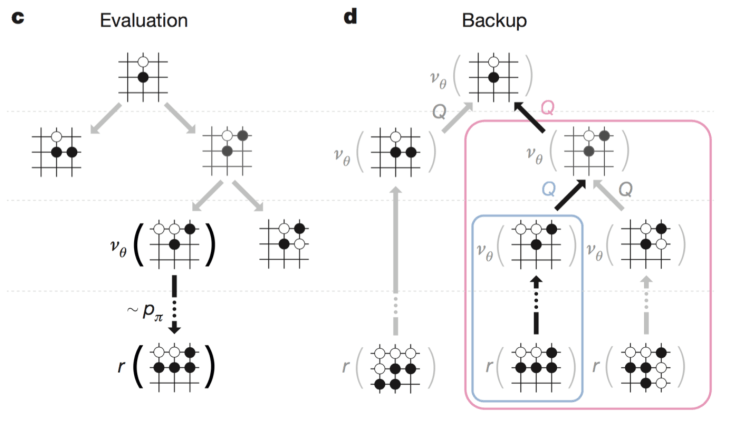
AlphGo은 이런 논리적 허점을 배제한 MCTS를 채용하고 있다. 그러나 엄밀히 말하면, 순수 MCTS는 로직이지 학습 algorithm이 아니다. 학습은 경험에 의한 정보을 다음 게임 또는 게임중간에 이용할 수 있어야하며, 그 정보가 저장되어야만 학습을 했다고 말할수 있다. RL과 같이 학습정보을 담을 무언가가 있어야 한다. AlphaGo는 이것을 신경망을 사용하여 담았다고 한다. (그러므로 deep learning이라든가 인공지능이라는 용어를 사용할 수 있는 것이다. 기존의 게임 알고리즘은 엄밀히 말하면 인공지능이라고 할수 없다. 로직이라고 표현하는게 더 많지 않나 싶다.) 여기서 사용한 신경망을 Value network와 Policy network라고 한다. 두 네크워크는 CNN구조을 사용하고, value network는 앞서 말한 value function(승패확률)을 판단하고, policy network는 수많은 tree search를 다 탐색하기 어려운 점을 감안하여, 학습에 의한 다음 착수를 판단하기 위한 것이다. Value function은 판단자료는 결국 한판의 바둑을 마무리하여 그 승리확률을 value function으로 판단하는 것을 고려할 수 있다. 그것은 순수 MCTS의 방법이다.그러나 너무 많은 경우의 수가 있는 경우(Search space가 너무 광대하다) 이방법은 현실적으로 불완전할것이다. 탐색가치를 평가하는 또다른 잣대가 도입되어야 할것이다. 그동안 학습에 의해서 얻은 승리확률을 기준으로한 value function의 예측치이다. 이것이 value network가 하는 역할이다.

left: policy network, right: value network
학습을 한다는 의미는 이 두 network가 가지는 parameter들(weights & bias)을 계속 현명한 판단을 하도록 수정해 나간다는 의미이다. 너무 방대한 경우의 수가 있는 경우, 기존의 방식인 random move를 출발점으로 학습해 나가는 것은 초기 학습에 너무 많은 시간이 필요할것이다. 그리고 초기에 학습된 정보도 무의미한 정보일 가능성이 크다. 어느 정도까지 학습이 되도록 인간 플레이어의 잘된 기보를 입력하여 초기 학습을 진행시키는 방법을 사용하는 것이 현명한 선택일 것이다. 그것을 위해 supervised learning기법을 사용하였고 이것이 policy network에 반영되었다고한다. AlphaGo의 자료중에는 로직만 설명하고 핵심이 되는 중요한 사항에 대해 기술한 자료는 많지 않다. RL분야에서 유명한 David Silver등이 nature지에 개제한 논문이 가장 좋은 자료이다.
Note) 본 포스팅은 Sutton과 Barto가 공저한 Reinforcement Learning : An Introduction을 기초로 작성된것이다.

“Heuristic Search | MCTS”에 대한 답글 1개