
이 포스팅에서는 environment model이 필요한 methods(such as dynamic programing and heuristic search)와 모델이 없이 학습하는 methods(such as Monte Carlo and temporal-difference)를 통합하는 관점을 알아 보기로 하자. planning과 learning methods를 통합하는 방법에 관한 것이다.
Models and Planning
Environment model이라고 하면, 그 어떤것이라도 agent의 action에 environment가 어떻게 반응하는지 예측할 수 있는 것을 의미한다. 즉, state와 action이 주어지면, model은 environment가 반응하여 내놓는 next state와 reward를 예측한다. 모델이 통계모델이라면(stochastic model), 여러 가지 next states와 rewards가 존재할것이고, 각각은 자신의 확률만큼 일어날 가능성이 있을 것이다. 가능성(possibilities)과 확률(probabilities)를 낼 수 있는 모델을 우리는 distribution model이라고 부른다. 반면, 단지 확률에 기반하여 여러 가능성중 하나만을 내놓는 모델을 sample model이라고 한다. Dynamic modeling에서 가정한 모델은 MDP dynamics, 
“Given a starting state and a policy, a sample model could produce an entire episode, and a distribution model could generate all possible episodes and their probabilities”
어떤 경우든, 모델은 environment를 모사(simulate)한 후 모의경험(simulated experience)를 내놓게 된다.
용어 planning은 어려분야에서 사용된다. 여기서 우리는 이 용어를 입력으로 모델을 사용하여 environment와 상호작용(interaction)하기 위한 policy를 생산하거나 개선하는 계산과정(computational processs)을 의미하는 것으로 사용한다.

AI 영역에서는 planning과 관련하여 두가지의 차별화된 방법이 있다. State-space planning에서 planning은 optimal policy나 goal을 위해 state space를 탐색이라는 관점에서 본다. Action은 state에서 다른 state로 이동시키고 value function은 state를 기준으로 계산된다. 반면, plan-space planning에서는 plan space를 탐색한다는 관점에서 본다. Plan이 변경되고, value function은 plan space를 기반으로 정의 된다. 우리가 여기서 다루는 planning은 state-space planning이다.
모든 state-space planning은 공통적인 구조를 가지고 있으며, 두가지 기본 idea에 기반한다: (1) 모든 state-space planning methods는 policy를 개선시키고자 거치는 중요한 중간 단계(key intermediate step)로서 value function을 계산하는 과정을 포함한다, (2) backup operation을 simulated experience를 이용하여 수행함으로써 value function을 구한다. 이 구조를 그림으로 나타내면 다음과 같다.
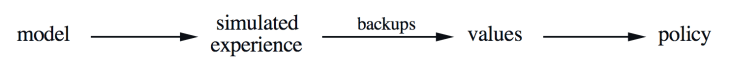
Dynamic programming뿐만아니라 다른 여러 state-space planning method도 이러한 구조를 따른다. Planning methods를 이러한 관점에서 보게되면, 이것이 learning methods와 직접적 관계가 있다는 점이 두각되기 마련이다. Learning과 planning methods의 공통적 핵심은 backup operation에 의한 value function 예측이다. 그 차이점이라면, planning은 model에 의해 생성된 simulated experience를 사용하는 반면, learning methods는 environment로 부터 생성된 real experience를 사용한다는 점이다. 이와 같은 공통적 구조로 인해, 많은 아이디어나 알고리즘을 planning과 learning간에 상호 차용 가능하다. 아래에 소개한 algorithm은 one-step tabular Q_learning에 기반한 planning method를 예시로 든것이며, 이 알고리즘을 random-sample one-step tabular Q-planning이라고 한다.

Dyna : Integrating Planning, Acting, and Learning
Planning이 on-line으로 수행되면, environment와의 상호작용하는 동안 여러 흥미로운 문제가 일어날 수 있다. 상호작용으로 습득한 새로운 정보는 model을 변화시킬수 있으므로 planning과의 상호작용이 일어날 수 있다. Planning agent에게는 real experience를 위한 적어도 두가지의 역할이 있다: 실제 environment를 더 정확히 모사하도록 모델을 개선하거나 강화학습방법을 이용하여 value function과 policy를 직접 개선시키는데 사용할 수 있다. 전자를 model-learning이라고하고, 후자를 direct reinforcement learning이라고 한다. 네가지 keyword인 experience, model, values, policy와의 상호관계를 아래 그림에 나타내었다. 각 화살표는 영향(influence)과 그에 따른 개선(improvement)과의 관계를 보여준다. 이 그림에서 주목할 점은 어떻게 experience가 value/policy를 직접적으로 또는 모델을 통한 간접적인 방식으로 개선시키지에 관한 내용이다. 후자, 즉 모델을 통한 개선은 planning에 포함되며 indirect reinforcement learning이라고 불리운다.

Direct와 indirect method 모두 각자의 장단점이 있다. 간접적 방법은 제한된 experience를 최대한 활용함으로써 environment와의 적은 interaction으로도 좋은 policy를 만들어 낼 수 있다. 반면에, 직접적 방법은 훨씬 간단하면서도 모델설계에 따르는 편차(biases)에 영향을 받지 않는다. 혹자는 간접적 방법이 항상 직접적 방법보다 우수하다고 주장하기도 하고, 반대로 혹자는 직접적 방법이 대부분의 인간이나 동물의 학습방법과 유사하다고 주장한다. 이와 관련하여 심리학(psychology)과 AI분야에서논쟁이 되는 사안은 인지(cognition)와 시행착오 학습(trial-and-error learning)간의 상대적 중요도이고, 더불어 반응 의사결정(reactive decision-making)과 숙고를 통한 계획수립(deliberative planning)간의 중요도도 논쟁거리이다. 하지만, RL에서는 서로의 차이에 대한 고찰이나 관심보다는 상호간의 유사성에 더 관심을 기울인다. 학습하는 입장에서는 서로의 장점에 더 관심을 기울이기 마련이다.
Dyna-Q에서는 위의 그림에 나타난 모든것 (planning, acting, model-learning, and direct RL)을 포함한다. Planning method는 앞서 기술한 random-sample one-step tabular Q-planning method이다. Direct RL method는 one-step tabular Q-learning이다. Model learning method도 table 기반이고 environment는 deterministic이라고 가정한다. 매번의 transition 


Dyna-Q algorithm이 한 예인 Dyna agent의 전박적 구조를 나타낸 그림이 아래에 도시되어 있다. 중간 컬럼은 agent와 environment와의 interaction을 나타내고, real experience의 궤적(trajectory)이 표시되어 있다. 왼쪽에 있는 화살표는 실제 경험을 통해 학습하는 direct RL을 나타낸 것이다. 오른쪽 부분은 model-based process이다. 모델은 실제경험(real experience)으로부터 학습하고 simulated experience를 만들어 낸다. 모델에 의해서 simulated experience가 생성되도록 starting state와 action을 선택하는 과정(process)을 search control이라 명명한다. 마지막으로, simulated experience에 reinforcement learning method를 적용하는 planning이 이루어지게된다.
 일반적으로, Dyna-Q도 포함하여, real experience로부터 학습(learning)하는 방법과 simulated experience로부터 planning하는 방법은 같은 방법을 사용한다. 그러므로, reinforcement learning method는 learning과 planning의 최종 공통분모(원문은 “final common path”)이다. Learning과 planning은 experience의 원천은 다르지만, 서로 거의 모든 수단을 공유한다는 점에서 서로 깊숙히 융합(integrated)되어 있다. Dyna-Q algorithm을 아래 나타내었다.
일반적으로, Dyna-Q도 포함하여, real experience로부터 학습(learning)하는 방법과 simulated experience로부터 planning하는 방법은 같은 방법을 사용한다. 그러므로, reinforcement learning method는 learning과 planning의 최종 공통분모(원문은 “final common path”)이다. Learning과 planning은 experience의 원천은 다르지만, 서로 거의 모든 수단을 공유한다는 점에서 서로 깊숙히 융합(integrated)되어 있다. Dyna-Q algorithm을 아래 나타내었다.

알고리즘을 살펴보면, (a)~(d)는 one-step tabular Q-learning 알고리즘이라는것을 알 수 있다. (e)는 model learning이고, (f)는 Q-planning에 해당한다.
When the Model is Wrong
모델은 일반적으로 학습이 진행됨에 따라 옳바른 정보로 채워지지만, 여러 이유로 모델이 부정확할 수도 있다. Environment가 stochastic이라서 제한적인 sample만 관찰되었거나, 완전하게 일반화되지 않은 function approximation에 의해 모델이 학습되었거나, 단순히 environment가 다르게 변했지만 새로운 behavior가 아직 관찰되지 않은 경우등이다. 모델이 불완전한 경우에는 planing process가 suboptimal policy를 계산하게될 가능성이 크다.
어떤 경우에는 planning에 의해 계산된 suboptimal policy는 모델의 에러를 재빨리 찾아내 교정할 수 있다. 모델이 실제보다 큰 reward나 나은 state transition을 예측하는 경향을 보일때, policy는 새로운 기회를 탐색하려고 노력하고, 결국 그동안 존재하지 않았던 것을 발견하려고 시도한다. 그러나, environment가 전보다 더 나은 방향으로 변화되었지만, 그전에 형성된 학습으로 인해 더 나은 방법을 발견하지 못하게 되는 어려운 상황이 생길 수 있다. 이런 경우에는 오랜시간동안 모델링 에러가 발견되지 못할수도 있다.
여기에서의 문제는 다른 버전의 exploration과 exploitation과의 충돌이라고 할 수 있다. Planning의 관점에서 exploration은 모델을 개선시키고자 하는 노력이나, exploitation은 기존에 학습된 모델을 이용하여 최적의 action을 취하려는 것을 의미한다. 우리가 원하는 것은 환경변화를 탐지하도록 agent가 탐색(explore)하지만, 성능(performance)가 저하될 정도로 빈도가 커서는 안된다는 것이다. 기존의 exploration/exploitation conflict와 같이 완전하면서도 실용적인 해결책은 아마도 없을것이나, 가끔은 간단한 경험법칙(heuristics)이 효과적일 때가 있다. Dyna-Q+ agent는 그런 경험법칙을 사용한다. 이 agent는 각각의 state-action pair가 environment와 interaction한 후 몇변의 time step이 흘렀는지를 계속해서 주시한다. 더 많은 시간이 흐를수록 그 state-action pair의 dynamics가 변해서 모델이 부정확할 가능성이 커진다. 이처럼 오랜시간동안 시도하지 않은 action을 장려하기위해, 이 action으로 발생된 simulated experience를 시도할때 “bonus reward”가 주어진다. 만약 어느 transition의 reward가 r이고 

Prioritized Sweeping
Dyna agent의 경우, simulated transition은 전에 경험한 모든 state-action pair중 같은 확률로 무작위로 선택하여 시작된다. 그러나, update하는 state-action pair중에 실제로 value의 변화가 생기는 pair가 많지 않다면 비효율적이되고 많은 backup이 의미가 없을 것이다. Planning이 진행될 수록 backup이 의미있는 pair는 많아지겠지만 여전히 많은 영역이 의미없는 backup이 이루어지고 있을 것이다. 일반적으로 goal에서 reward변확 반드시 있으므로 goal에서 부터 시작하여 backward방향으로 update하는 것이 효과가 있을 것이다. 그러나, 우리는 goal이라는 특수한 state에 한정하지 않고, value의 변화가 있는 어느 state에도 backward update 되는 것을 원한다. 예를 들어, agent가 environment의 변화를 감지하고 한 state의 value값을 변화시켰다고 해보자. 일반적으로, 이것은 다른 많은 state도 value값의 변화가 있어야 함을 의미한다. 일단, 변화가 감지된 state의 바로 전단계의 state가 value값의 변화가 생기는 update가 일어나게 되고, 그 이후 다시 이런 패턴의 update가 이루어질것이다. 이러한 방식을 value의 변화가 일어난 state로 부터 시작하여 backward로 update가 이루어지게 되며, 이런 아이디어를 backward focusing이라고 한다.
유효한 backup이 이루어지는 전면에서 후방으로 전파가 이루어지는 동안, 점차 그 여파가 증가하고, 여러 state-action pair가 필요한 backup을 하게 된다. 그러나 이 모든 backup이 모두 같은 비중으로 중요하다고 할수 없다. 어떤 state의 value는 많은 변화가 있을 것이나, 다른 state는 그렇지 않을 수 있다. 큰변화가 일어나 predecessor pair는 더 큰 변화를 일으킬 가능성이 크다. Stochastic environment에서는 transition probability 역시 변화 정도나 backup 긴급성에 영향을 미친다. 그러므로 backup 긴급성에 기반해서 backup의 우선순의를 정하는 것이 자연스러운 일일것이다. 이 개념이 prioritized sweeping의 배경이다. Prioritized sweeping이 도입된 알고리즘을 아래에 나타내었다.

Note) 본 포스팅은 Sutton과 Barto가 공저한 Reinforcement Learning : An Introduction을 기초로 작성된것이다.

와우. 정말 정리가 잘되어 있네요. 큰 도움이 됩니다. 감사합니다.
좋아요좋아요