
RL분야는 Policy Gradient, 특히 Actor Critic method가 매우 중요한 위치를 차지하고 있다. PG는 수학적 기반이 전 포스팅에서 소개한 Policy Gradient Theorem을 근거로 발전하고 있다. Stochastic policy gradient theorem은 policy를 state space와 더불어 action space의 확률분포를 염두에 두고 있다면, 이번에 소개하는 Deterministic Policy Gradient 알고리즘은 policy를 생각할때 action space에서 특정 action을 선택(deterministic)하면서도 policy를 발전시킬수 있음을 보여준다. 이때 action의 선택은 off-policy 방법을 사용한다. 그러므로 Stochastic 방법보다 하나의 dimension(state와 action중 action space)을 제거하여 더욱 간단하게 policy를 발전시킬수 있는 이론적 근거를 마련한 것이다. 이에 관한 이론은 오래전에 발표되었으나 이 분야를 연구하는 사람에게는, 실용적 측면에서 중요한 논문이다. 아래 link를 참조하기 바란다.
Deterministic policy gradient algorithms
Continuous control with deep reinforcement learning
이 글은 특히 두번째 논문에 관한 글로서, DQN에 영감을 받아 DPG에 신경망을 적용시킴과 동시에 action space가 매우 크거나 continuous space일때 적용한 사례이다.
Policy Gradient Theorem
MDP 문제는 기본적으로 누적보상 최적화 문제(maximize cumulative discounted reward)이다. 그러므로 누적보상을 수학적으로 표현하는 것에서 부터 시작하며, 특정 state에서 시작하여 최종적으로 얻을 수 있는 reward를 모두 합산하되 reward 값이 변하는 모든 가능성을 고려해야 한다. 그 모든 가능성은 1) action을 선택하는 모든 옵션, 2) 선택된 action에 의해 environment가 취할 수 있는 모든 next state이다. 여기서 action 확률 분포를 생각하고 각 action의 결과물인 environment 다음 state의 확률분포를 고려해야 한다면 문제가 매우 복잡해 진다는 것을 알 수 있다. 여기에, state transition function까지 고려해야 한다면 더욱 더 복잡한 문제가 될것이다. 이것의 수학적 표현하면 초기 state는 분포를 가지고, action은 policy를 따르는 적분기호가 2개 들어간 함수를 생각해야 한다(아래 수식 참조). 각 함수는 변수끼리 상호 연관되어 이 방법으로 실제문제를 해결하는 것은 불가능할 것이다. 여기에 수학적 가정이 더해지면 문제가 공략 가능한 문제로 변할 수 있으며, 우리는 이것을 기대하고 실제 문제를 해결해 보려고 노력하는 것이다.
Policy gradient는 앞서 설명한 cumulative reward가 증가하는 방향으로 policy function의 parameter를 update시켜가는 것이다. 이것을 performance gradient(
![\nabla_{\theta} J(\pi_{\theta}) = \int_\mathcal{S} \rho^{\pi}(s) \int_\mathcal{A} \nabla_{\theta}\pi_{\theta} (a|s)Q^{\pi}(s,a) \mathrm{d}a \mathrm{d}s = \mathbb{E}_{s{\sim}{\rho}^{\pi}, a{\sim}{\pi}_{\theta}} [\nabla_{\theta}log{{\pi}_{\theta}}(a|s) Q^{\pi} (s,a)]](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7D+J%28%5Cpi_%7B%5Ctheta%7D%29+%3D+%5Cint_%5Cmathcal%7BS%7D+%5Crho%5E%7B%5Cpi%7D%28s%29+%5Cint_%5Cmathcal%7BA%7D+%5Cnabla_%7B%5Ctheta%7D%5Cpi_%7B%5Ctheta%7D+%28a%7Cs%29Q%5E%7B%5Cpi%7D%28s%2Ca%29+%5Cmathrm%7Bd%7Da+%5Cmathrm%7Bd%7Ds+%3D+%5Cmathbb%7BE%7D_%7Bs%7B%5Csim%7D%7B%5Crho%7D%5E%7B%5Cpi%7D%2C+a%7B%5Csim%7D%7B%5Cpi%7D_%7B%5Ctheta%7D%7D+%5B%5Cnabla_%7B%5Ctheta%7Dlog%7B%7B%5Cpi%7D_%7B%5Ctheta%7D%7D%28a%7Cs%29+Q%5E%7B%5Cpi%7D+%28s%2Ca%29%5D%C2%A0&bg=ffffff&fg=444444&s=2&c=20201002)
이 식이 중요한 점은 performance gradient 값을 구하는 작업이 expectation(

Stochastic Actor-Critic Algorithms
이에 관한 포스팅이 이미 있지만, 이 알고리즘은 다시 한번 언급할 가치가 있는것 같다. Actor는 위의 식으로 policy parameter를 update할수 있다. 이 식에 포함된 true action-value function 
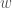

![\nabla_{\theta} J(\pi_{\theta}) = \mathbb{E}_{s{\sim}{\rho}^{\pi}, a{\sim}{\pi}_{\theta}} [\nabla_{\theta}log{{\pi}_{\theta}}(a|s) Q^{w} (s,a)]](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7D+J%28%5Cpi_%7B%5Ctheta%7D%29+%3D%C2%A0+%5Cmathbb%7BE%7D_%7Bs%7B%5Csim%7D%7B%5Crho%7D%5E%7B%5Cpi%7D%2C+a%7B%5Csim%7D%7B%5Cpi%7D_%7B%5Ctheta%7D%7D+%5B%5Cnabla_%7B%5Ctheta%7Dlog%7B%7B%5Cpi%7D_%7B%5Ctheta%7D%7D%28a%7Cs%29+Q%5E%7Bw%7D+%28s%2Ca%29%5D%C2%A0&bg=ffffff&fg=444444&s=2&c=20201002)
Off-policy Actor-Critic
MDP 전개 과정에서 action을 선택하는 policy가 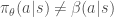

![\nabla_{\theta} J_{\beta}(\pi_{\theta}) = \mathbb{E}_{s{\sim}{\rho}^{\beta}, a{\sim}{\beta}_{\theta}} [ \frac {{\pi}_{\theta}(a|s)} {{\beta}_{\theta}(a|s)} \nabla_{\theta}log{{\pi}_{\theta}}(a|s) Q^{w} (s,a) ]](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7D+J_%7B%5Cbeta%7D%28%5Cpi_%7B%5Ctheta%7D%29+%3D%C2%A0+%5Cmathbb%7BE%7D_%7Bs%7B%5Csim%7D%7B%5Crho%7D%5E%7B%5Cbeta%7D%2C+a%7B%5Csim%7D%7B%5Cbeta%7D_%7B%5Ctheta%7D%7D+%5B+%5Cfrac%C2%A0%7B%7B%5Cpi%7D_%7B%5Ctheta%7D%28a%7Cs%29%7D+%7B%7B%5Cbeta%7D_%7B%5Ctheta%7D%28a%7Cs%29%7D+%5Cnabla_%7B%5Ctheta%7Dlog%7B%7B%5Cpi%7D_%7B%5Ctheta%7D%7D%28a%7Cs%29+Q%5E%7Bw%7D+%28s%2Ca%29+%5D%C2%A0&bg=ffffff&fg=444444&s=2&c=20201002)
True policy와 behavior policy의 비를 importance sampling ratio라고 부른다.
Deterministic Policy
지금까지 stochastic policy gradient에 관해 설명하였지만, 이 이론은 deterministic policy로 개념을 축소시켜, 실제적인 문제에서 응용 가능하도록 할 필요가 있다. 즉, 앞서 설명한 stochastic policy gradient theorem은 deterministic policy gradient theorem으로 변형가능하다. Deterministic policy gradient theorem에서 performance gradient는 아래와 같이 계산 가능하다. DPG theorem에서는 action space에 대한 적분항이 사라진것을 유념해야 한다. 일종의 chain rule의 적용으로 action(deterministic action) space에서 Q value의 gradient와 action network로 표현되는 action에 대한 probability distribution의 gradient의 곱으로 표현된다는 것이 중요한 핵심이다. 즉 actor의 critic을 별도로 network를 구성하여 Actor-Critic으로 사용한다.
![\nabla_{\theta} J(\mu_{\theta}) = \int_\mathcal{S} \rho^{\mu}(s) \nabla_{\theta} \mu_{\theta} (s) \nabla_a Q^{\mu} (s,a) |_{a=\mu_{\theta}(s)} \mathrm{d}s = \mathbb{E}_{s{\sim}{\rho}^{\mu}} [\nabla_{\theta}{\mu}_{\theta}(s) \nabla_a Q^{\mu} (s,a) |_{a=\mu_{\theta}(s)}]](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7D+J%28%5Cmu_%7B%5Ctheta%7D%29+%3D+%5Cint_%5Cmathcal%7BS%7D+%5Crho%5E%7B%5Cmu%7D%28s%29+%5Cnabla_%7B%5Ctheta%7D+%5Cmu_%7B%5Ctheta%7D+%28s%29+%5Cnabla_a+Q%5E%7B%5Cmu%7D+%28s%2Ca%29+%7C_%7Ba%3D%5Cmu_%7B%5Ctheta%7D%28s%29%7D%C2%A0+%5Cmathrm%7Bd%7Ds+%3D+%5Cmathbb%7BE%7D_%7Bs%7B%5Csim%7D%7B%5Crho%7D%5E%7B%5Cmu%7D%7D+%5B%5Cnabla_%7B%5Ctheta%7D%7B%5Cmu%7D_%7B%5Ctheta%7D%28s%29+%5Cnabla_a+Q%5E%7B%5Cmu%7D+%28s%2Ca%29+%7C_%7Ba%3D%5Cmu_%7B%5Ctheta%7D%28s%29%7D%5D%C2%A0&bg=ffffff&fg=444444&s=2&c=20201002)
Policy Gradient 방법이 진화하는 과정중에 매우 중요한 알고리즘으로 우리는 이 결과를 향후에도 계속 사용할 것이고 특히 actor network를 학습시키는데 사용하게 된다.
