
Atari game을 통해 강화학습의 가능성을 보여준지도 꽤 시간이 지났다. 그 이후 강화학습은 AlphaGo를 통해 다시한번 세상의 이슈가 되었으며, 이 블로그에도 관련 기술을 소개한 바 있다. 이후 DeepMind사는 Starcraft를 상대할 것이라는 이야기가 회자되었다. 하지만 Starcraft game의 정복은 쉽지 않을 것이란 예상이 많았다. 근본적인 이유는 게임 자체가 정해진 틀이 없는 전략 게임이라는 점도 있지만, 다수의 agent들간의 상호 협력 또는 적대적 플레이를 해야 한다는 점이다. Agent들은 독립적으로 움직이면서 상호 협력하거나 적대적 대응을 해야 하며, MDP관점에서 battle ground 뿐만 아니라 agent 자신을 제외한 모든 agent들도 environment가 된다는 점과, 이 agent들이 지속적을 자체 학습을 통해 진화하는 상황에서의 학습이라는 점도 쉽지 않을 것이라는 이유이다. DQN과 같은 알고리즘을 사용한다고 할때 알고리즘의 안정화에 필수적인 replay buffer의 사용과 이 buffer의 sample은 계속 진화하고 있는 환경에도 적합한 방법인지 알 수 없다. 또한 multi-agent environment에서 policy network가 학습이 가능할지도 의문이다.
이번에 분석한 논문은 이러한 수 많은 의문에 하나의 가능성을 보여준 논문으로, 다수의 agent들이 참여하여 특정 목적을 달성하도록 학습시키는 강화학습에 관한 내용이다. 하나의 agent의 학습을 위한 여러 이론도 중요하지만 다수의 agent들을 동시에 학습시킨다는 개념은 실제적인 응용면에서 매우 중요한 의미를 가진다는 것을 알기에 이 논문을 읽어보았다. 논문은 아래 제목으로 발표되었고, 일명 Multi-Agent Deep Deterministic Policy Gradient(MADDPG)라고 부른다. DDPG를 multi-agent환경에 적용한 논문이므로 앞서 올린 글과도 직접적으로 관계가 있다.
이 논문에서는 actor-critic policy gradient를 기본으로 한다. 일단, actor는 다른 agent의 policy를 안다는 가정(미리 안다는 가정)을 사용해서는 안된다. Agent는 관측가능한 기본적 observation 정보만 이용하여 판단하고 행동해야 한다. 반면 critic관점에서 보면 action-value function은 자기 자신의 policy에 기반하여 계산되지만, 다른 agent들의 action에 어떤 형태든 대응하지 않고 나홀로 독립적으로 행동한다면 이 논문의 목적하고는 거리가 먼것이라고 할 수 있다. 학습하는 agent들은 다른 agent들의 policy변화에 능동적으로 반응하여 최적의 action을 찾아 내야 한다. 이 논문은 살펴보면 볼수록 DDPG의 단순한 확장은 아니라는 생각이 들었고, 이해 하기도 쉽지 않다.
Multi-agent MDP와 DDPG
우리가 함수를 다룰때 변수의 범위나 space/dimension을 중시하는 것처럼, MDP에서도 State, Action, Policy등의 특징과 space를 반드시 확인할 필요가 있다. 그동안 RL은 주로 single agent의 MDP문제였으나, MADDPG는 MDP를 다른 시각으로 볼 필요가 있다. MADDPG에서는 모든 agent의 거동이 감안된 state space 

Multi_agent Actor-Critic
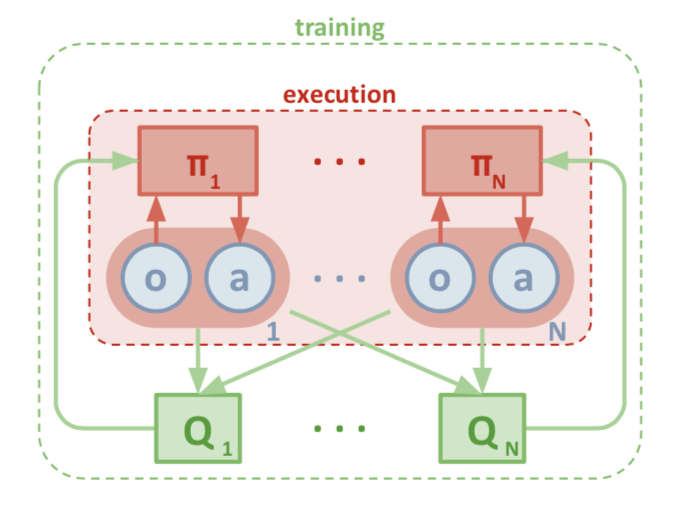
MADDPG에서는 critic으로 DQN에서 사용하는 Q-value network를 사용한다. Actor는 RL의 Policy Gradient method를 사용하여 학습시킨다. 적대적(adversarial) 또는 협동적(cooperative) agent들의 개별적인 actor network를 가지되, 방향성/목표를 유도하려고 centralized critic을 사용 한다. 이 구조를 논문에서는 아래 그림을 이용하여 “centralized training with decentralized execution” 이라고 표현하고 있다. 한장의 그림이 모든걸 표현하기도 한다. 좋은 논문은 이런식으로 이론을 일목요연하게 표현하려고 하고 이론의 전체적인 틀을 보는데 이만한 것이 없다는 생각이 든다. 수학식들중 중요한 식들은 적어 놓았지만 전체 내용은 논문을 참조하기 바란다.
Policy gradient 방법은 discounted cumulative reward 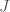
![\nabla_{\theta_i} J({\mu_i}) = \mathbb{E}_{\textbf{x},a{\sim}D} \left [ \nabla_{\theta_i} \mu_i (a_i|o_i) \nabla_{a_i} Q^{\mu}_i (\textbf{x},a_1,...,a_N )|_{a_i = \mu_i (o_i)} \right ]](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta_i%7D+J%28%7B%5Cmu_i%7D%29+%3D%C2%A0+%5Cmathbb%7BE%7D_%7B%5Ctextbf%7Bx%7D%2Ca%7B%5Csim%7DD%7D+%5Cleft+%5B+%5Cnabla_%7B%5Ctheta_i%7D+%5Cmu_i+%28a_i%7Co_i%29+%5Cnabla_%7Ba_i%7D+Q%5E%7B%5Cmu%7D_i+%28%5Ctextbf%7Bx%7D%2Ca_1%2C...%2Ca_N+%29%7C_%7Ba_i%C2%A0+%3D+%5Cmu_i+%28o_i%29%7D+%5Cright+%5D+&bg=ffffff&fg=444444&s=2&c=20201002)
여기서, Q-value를 보면 state와 모든 agent의 action을 감안한 함수로 표현해 놓은 것을 알 수 있으며, 위 그림에서도 이를 잘 나타내고 있다. 즉 training 과정에서 Q-value를 구하는 과정에서 모든 agent들의 action이 고려된다는 것을 의미하므로 muti-agent가 포함된 환경에서 action-value를 구하고 training하므로 각 agent들은 다른 agent가 포함된 environment에서 policy를 최적화 할 수 있는 것이다. 그러므로, 이 action-value function을 centralized action-value function이라고 부르는데, 모든 agent의 action 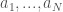
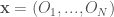

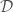

Centralized action-value function 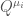
![\mathcal{L}(\theta_i) = \mathbb{E}_{\textbf{x},a,r,\textbf{x}'} \left [(Q^{\mu}_i (\textbf{x},a_1,...,a_N ) - y)^2 \right]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BL%7D%28%5Ctheta_i%29+%3D%C2%A0%5Cmathbb%7BE%7D_%7B%5Ctextbf%7Bx%7D%2Ca%2Cr%2C%5Ctextbf%7Bx%7D%27%7D+%5Cleft+%5B%28Q%5E%7B%5Cmu%7D_i+%28%5Ctextbf%7Bx%7D%2Ca_1%2C...%2Ca_N+%29+-+y%29%5E2+%5Cright%5D+&bg=ffffff&fg=444444&s=2&c=20201002)

여기서, 
Agent policy 추론
그러므로 이제 agent 집합체가 개별적 학습과정을 통해 policy를 upgrade시키도록 고안해야 하고, 이 policy가 반영된 action에 의한 q-value가 점차 target에 가까워 져야 한다. 내 생각에 이 문제는 최대 난관이라고 생각한다. 잘못하면 학습이 불가능하거나 local optimum에서 헤어나지 못할지도 모른다. 논문에서는 다른 agent들의 policy를 추론할 수 있는 방법에 대해 설명하고 있다. Agent 
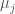


![\mathcal{L}(\phi^j_i) = - \mathbb{E}_{o_j , a_j} \left [log \hat{\mu}^j_i (a_j | o_j ) + \lambda H(\hat{\mu}^j_i ) \right]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BL%7D%28%5Cphi%5Ej_i%29+%3D+-+%5Cmathbb%7BE%7D_%7Bo_j+%2C+a_j%7D+%5Cleft+%5Blog+%5Chat%7B%5Cmu%7D%5Ej_i+%28a_j+%7C+o_j+%29+%2B+%5Clambda+H%28%5Chat%7B%5Cmu%7D%5Ej_i+%29+%5Cright%5D+&bg=ffffff&fg=444444&s=2&c=20201002)




위 식은 Q-learning의 target network의 함수이고 off-policy 방식의 update라고 생각할 수 있다.
Agent Policy Ensembles
이 블로그에서 DQN을 소개하면서 알고리즘의 안정성을 확보하기 위한 기술들을 언급하였으나, DQN 기술을 차용한다손 치더라도 muti-agent들이 참여하는 environment에서 알고리즘의 안정성 문제는 훨씬 어려운 문제임을 짐작할 수 있다. Agent들이 계속해서 자신의 policy를 변화시키는 non-stationary environment에서 다른 agent의 policy변화에 너무 적극적으로 자신의 policy를 update시키게 된다면 알고리즘의 안정성을 해치게 될것이다. 이 문제를 해결하기 위해 논문에서는 
이제 


![J_e (\mu_i ) = \mathbb{E}_{k \sim unif(1, K), s\sim p^{\mu} , a \sim \mu^{(k)}_i } \left [ R_i (s,a) \right ]](https://s0.wp.com/latex.php?latex=J_e+%28%5Cmu_i+%29+%3D+%5Cmathbb%7BE%7D_%7Bk+%5Csim+unif%281%2C+K%29%2C+s%5Csim+p%5E%7B%5Cmu%7D+%2C+a+%5Csim+%5Cmu%5E%7B%28k%29%7D_i+%7D+%5Cleft+%5B+R_i+%28s%2Ca%29+%5Cright+%5D+&bg=ffffff&fg=444444&s=2&c=20201002)
episode마다 다른 sub-policy가 실행되기 때문에 agent 

![\nabla_{\theta_i^{(k)}} J_e ({\mu_i}) = \frac {1}{K} \mathbb{E}_{\textbf{x},a \sim D^{(k)}_i} \left [ \nabla_{\theta_i^{(k)}} \mu_i^{(k)} (a_i|o_i) \nabla_{a_i} Q^{\mu}_i (\textbf{x},a_1,...,a_N )|_{a_i = \mu_i^{(k)} (o_i)} \right ]](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta_i%5E%7B%28k%29%7D%7D+J_e+%28%7B%5Cmu_i%7D%29+%3D%C2%A0+%5Cfrac+%7B1%7D%7BK%7D+%5Cmathbb%7BE%7D_%7B%5Ctextbf%7Bx%7D%2Ca+%5Csim+D%5E%7B%28k%29%7D_i%7D+%5Cleft+%5B+%5Cnabla_%7B%5Ctheta_i%5E%7B%28k%29%7D%7D+%5Cmu_i%5E%7B%28k%29%7D+%28a_i%7Co_i%29+%5Cnabla_%7Ba_i%7D+Q%5E%7B%5Cmu%7D_i+%28%5Ctextbf%7Bx%7D%2Ca_1%2C...%2Ca_N+%29%7C_%7Ba_i%C2%A0+%3D+%5Cmu_i%5E%7B%28k%29%7D+%28o_i%29%7D+%5Cright+%5D+&bg=ffffff&fg=444444&s=2&c=20201002)
Policy ensemble에서는 일종의 policy basket을 운영하겠다는 얘기인데, episode마다 다른 policy를 운영하게 되면 학습을 위한 data창고인 replay buffer도 별도로 운영한다. 이것을 policy가 일종의 distribution을 가진다고 생각해 볼 수 있다. 무작위 sampling을 한다면 uniform distribution으로 볼 수 있다. 이 논문은 해석하는데 적잖은 시간이 필요하다. 그러면서도, 완전히 이해한것인지 불분명하다.
마지막으로 논문에서 밝힌 MADDPG의 pseudo-code는 아래와 같다.

이 code는 DDPG의 code와 비슷해 보이지만, 첨자들에 여기서 소개한 많은 내용이 내포되어 있다. DDPG에서는 replay buffer에서 sampling한 sample을 위한 첨자만 필요했지만, MADDPG에서
테스트
Multi-agent RL 자료를 살펴보면 OpenAI의 multiagent-particle-envs를 활용하여 다양한 시나리오에서 구현한 실험을 찾아 볼수 있다. 최근 Dota2 game에서 프로게이머를 상대로 AI가 이겼다는 블로그 소식을 접한바 있다. 이 게임은 내가 잘 모르는 게임이지만, 이 행사(2018년 8월 5일)가 가지는 의미는 multi-agent환경에서 매우 복잡한 전략 다른 agent들의 전략을 추론하며 게임을 한다는 것이다. AlphGo도 의미를 가지지만 이 것도 매우 큰 의미를 가지는 것이 틀림 없다. Dota-2대신에 StarCraft였으면 훨씬 재미있었을 것이다.
여하튼, 이 알고리즘이 어떻게 구현되고 실행되는지 살펴보기 위해 이미 공개된 코드를 사용하여 재현해 보았다. 큰 줄기만 살펴보는데도 코드 해석에 무척 애를 먹었다. 아래 동영상은 OpenAI의 multi-agent environment에서 simple_tag라는 scenarion를 MADDPG로 학습한 결과를 보여준다. 이 scenario는 녹색 agent가 적색 adversary agents들로부터 붙잡히지 않고 검은색 목표지점으로 이동하는것을 목표로 한다. 이 코드는 위에서 설명한 policy ensemble을 사용하지 않았다.
