
여전히 관심 있는 분야에 대해 시간 나는데로 자료을 읽고 공부하지만 블로그에 올리지 않았다. 사실 시간이 부족한 상황에서 블로그에 글쓰는 시간 조차도 아깝다는 생각이 들기도 하지만… 정리를 한다는 면에서는 블로그에 계속 글을 올리는 것이 좋다는 생각에는 변함이 없다.
Google은 작년에 자신들이 개발해 놓은 Object Detection(사물인식) API를 공개했다. 이미지 인식용으로 개발된 수많은 CNN 모델을 쉽게 사용할 수 있고 무엇보다도 학습된 모델 (CNN 구조 및 weights) 을 그대로 사용할 수 있다는 큰 잇점이 있다. 이 모델들을 다운로드 받아서 사물 인식을 잘하는지 확인하는데도 꽤나 큰 노력(?)이 필요하다. 이것은 직관적이지 않은 tensorflow 때문이기도 하다. Google의 API를 사용하려면, 그들이 정해놓은 방식을 그대로 따라해야 한다. 그들의 룰을 충실히 따라하지 않으면 어디에선가 에러 메시지를 보내온다.
위의 링크에서는 몇가지의 이미지 dataset에 대해 다양한 CNN 모델별로 학습시킨 모델을 제공함과 동시에 각 모델의 성능도 비교 평가 하였다. 사용된 CNN 모델은 mobilenet, inception, resnet50, resnet101 등이다. mAP값이 높은 resnet이 정확도는 높지만 아무래도 학습시간이 오래 걸리다 보니, 이번 스터디는 속도와 정확도 측면에서 적절하다고 판단된 inception을 사용하였다. 학습을 시키기 위한 수단으로 Google은 Google Cloud를 통해 학습시키는 방법과 local machine을 이용한 학습 방법을 안내하고 있지만, Google cloud를 사용하지 않고 내 computer를 사용하여 학습시키는 방법을 시도하였다.
Google은 object detection API를 사용하는 학습을 시키기 위해서는 아래와 같이 크게 두가지 절차를 요구하고 있다.
- 이미지 dataset을 다운로드 받아서 Tensorflow가 처리하는 TFrecord 파일로 변환한다. 물론 TFrecord 파일을 거치지 않고 학습시키는 것도 가능하지만, TFrecord 파일은 모든 이미지를 하나의 파일로 만들어 놓으니 처리하기 편할것이다. 이와 동시에 필요한 파일은 map 파일로, 각 이미지의 label은 label map의 형태로 이미지 번호와 그에 대한 label을 1대1로 매칭시켜 놓은 텍스트 형태의 파일이다.
- 다음으로는 모델과 관련된 hyper parameter등의 정보를 Tensorflow 모델로 전달하기 위해 ConFig 파일이 필요하다. 이 파일은 train시킬때 모델 관련 모든 패러미터들을 arguments 형식으로 전달하기에는 너무 많기 때문에 한꺼번에 필요한 패러미터들을 모두 정의한 파일을 전달하는 형식을 취하는 것으로 보인다. ConFig 파일에는 모델의 checkpoint 파일 위치, 모델 하이퍼패러미터, 카테고리의 수, step의 수, input record file의 위치등을 지정하도록 되어 있다.
위와 같이 필요한 파일을 적절히 준비하면 training 시킬 준비가 된 것이다. 이미지 dataset으로 Oxford-IIIT pet dataset을 이용하여 data file들을 준비하고, inception_v2용 config파일을 작성하고 학습시켰지만, 각 이미지의 label을 보니 나 자신도 구분하기 어려운 이미지가 많다. 테스트로 step 수를 3000으로 지정하고 training 시켜 보았으나, 정확도는 약 50% 정도 밖에 되지 못했다. 학습을 더 시킬 수록 정확도는 올라가지만, 최종적으로 200000 step까지 학습시켰다. 모델을 mobilenet으로 하는 경우 더 적은 시간이 걸리 겠지만, resnet101의 경우는 훨씬 많은 시간이 소요될것이다.
Google Inception_V2 테스트 결과
먼저 학습 성능의 reference로 삼기 위해 MicroSoft COCO dataset을 기반으로 학습된 inception_v2 모델이 test image를 대상으로 어떻게 예측하는지 살펴 보았다. 테스트 이미지는 pet dataset의 이미지와, COCO dataset의 이미지, 그리고 구글에서 다운 받은 사과 이미지를 적절히 섞어서 예측 능력을 살펴 보았다. 아래는 테스트에 사용한 image이다. 각 이미지에 마우스 포인터를 올리면 이미지의 번호를 볼 수 있다.
 1
1 2
2 3
3 4
4 5
5 6
6 7
7 8
8 9
9 10
10
먼저 구글이 제공하는 inception_v2 모델을 이용하여 예측한 결과의 예로 10번 그림에 대한 결과이미지이다.
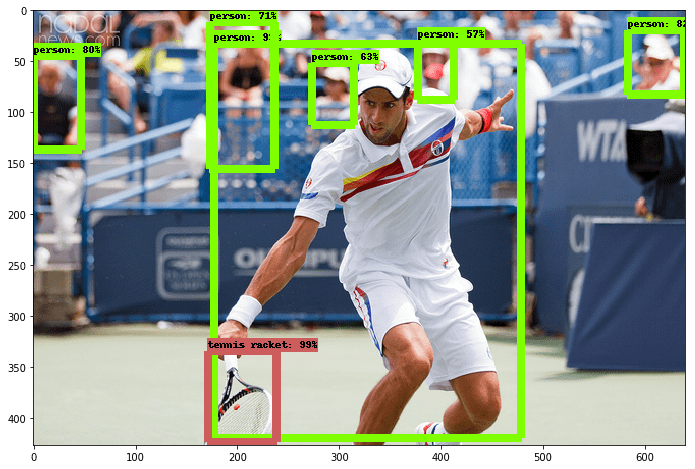
위의 테스트 이미지 중에 개와 고양이류는 모두 “dog”와 “cat”으로 대부분 잘 예측하였으나 잘못된 예측을 한 결과 이미지는 아래 2개이다. 1번 이미지는 “cow”로, 7번 이미지는 “person”으로 인식하였다. 1번 이미지의 경우 검은 바탕에 흰색 무늬 패턴이 소라고 인식할 수도 있겠지만, 7번 이미지를 사람으로 인식한 것은 좀 실망스러운 결과이다.


Oxford Pet dataset 학습 결과
마지막으로 pet dataset을 이용하여 학습시켜본 결과이다. 앞서 reference로 사용한 모델의 경우 개나 고양이에 대한 종을 구분하지 않도록 학습되어 있기 때문에, pet dataset에 의한 예측 결과는 종을 정확히 예측하느냐가 정확도를 가름짓는 잣대이다. 아래 그림은 1번 및 7번 이미지의 예측 결과이다. 1번 이미지는 American pit bull terrier이고 7번 이미지는 Sphynx인데 정확히 예측하고 있다. 반면, 3번 이미지는 British Shorthair라고 하는데, 64%의 확률로 Bombay라고 예측하였다(Google에서 Bombay cat 이미지나 dataset 사이트의 이미지를 보니 나 자신도 구분하지 못하겠다). 또하나 틀린 이미지는 8번 이미지로 staffordshire bull terrier라는 종이라고 하는데, American pit bull terrier로 인식하였다. 마지막 9번과 10번 이미지는 학습시 전혀 보지 못한 이미지이므로 예측결과가 없다. 이 문구에 오해가 없길 바란다. 원래 학습시 보지못한 이미지에 대한 예측 능력이 중요하다. 단지 이 두 이미지는 애완 동물의 이미지가 아니라는 의미이다. 학습에 사용된 이미지에 모델이 과도하게 fitting되다 보면 오히려 한번도 학습에 사용되지 않은 테스트 이미지에 대한 예측 능력이 떨어지는 경우가 많다. 이것이 Training, Validation, Test용 dataset을 구별하여 사용하는 이유이다.


