
앞서 histogram filter와 Kalman filter에 대해 알아 보았다. 특히 Kalman filter의 경우 Gaussian distribution을 보이는 state distribution과 measurements distribution의 이론적 해를 사용하여 계산할 수 있었다. 이번에는 이론적 해를 구하기 까다로운 경우는 접근하는 방법을 소개하고자 한다. 제목과 같이 particle filter를 사용하는 방법이다. 이론적 해를 구하기 어려울 때 사용한다고 하더라도, 개념을 표현하는 수식은 있다. 다른 filter에도 동일하게 적용되는 일반적 식이지만 particle filter의 개념을 소개하기 위해 사용하기로 한다.(실제 필터의 사용은 이런 수식을 사용하여 계산해내야 하는것이 아니므로 사용하기 쉽다.)
기본 개념
일반적으로 어느 system의 state가 시간에 따라 변하고, 이 state에 대한 정보는 각 time step마다 측정하는 noisy measurements에 의해 얻어지는 state-space model을 예측하기 위해 아래와 같은 식을 생각해 볼 수 있다.

여기서, 




여기서, 
앞서 Kalman filter 포스팅에서 밝혔듯이, filtering은 과거 state 및 measurements정보로 부터 state를 예측하는 prediction step과 현재의 측정정보를 사용하여 예측된 state를 보정하는 correction step(또는 update step)으로 나눌 수 있다. 먼저 prediction step에서, 


여기서, 

위 두식을 통해 개념적 이론은 정리가 되었지만 각 distribution을 이론적 식으로 표현할 수 있는지가 미지수이다. Gaussian distribution을 사용하고, 이론적 해석이 가능한 경우 Kalman filter를 사용한다. 그러나, 이론적으로 구하기 어려운 경우는 Mote Carlo method를 사용한다. Monte Carlo sampling 방법은 이론적으로 system해석이 어려운 경우, measurement의 오차를 이용하여 state function을 예측하되, 수많은 particle을 동원한 통계적 기법을 사용하는 것이다.
Particle Filter
여기서는 SIS(Sequential Importance Sampling) 방법을 사용하는 particle filter를 소개한다. 이 알고리즘에서는 time step k-1에서 앞서 말한 filtering distribution, 



SIS의 importance sampling에서는 target distribution, 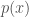
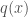

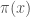




한편, weight로서 의미를 가지기 위해서는 기본적으로 다음과 같은 특성을 보여야 한다.

위식을 통해 수학적으로 아래와 같은 recursive expression을 얻을 수 있다.

필자도 깔끔하게 정리된 수식을 선호하지만, 수식을 이해하고 그 물리적 의미를 파악하는 일이 어려울 때가 있다. 그 이유는 개념이 어려운 경우도 있지만, 수학이라는것이 대부분 generalization(일반화)된 형태로 표현되기 때문이기도 하다. 위의 식들도 일반화되어 있는 표현이므로 즉각에서 그 의미를 파악하기 쉽지 않다. 위의 proposal distribution식의 의미는 update된 proposal distribution은 이전의 distribution에 새로운 measurement를 포함한 관측치 및 target distribution을 기반으로 예측되는 time step k의 proposal distribution의 확률분포를 곱한값이 예측되는 target distribution이라는 의미이다. weight는 새로운 measurement를 동원하여 time k에서의 target distribution을 예측할 수단으로 weight를 도입하고 새로운 weight는 기존 weight와 기존 proposal distribution을 근거로 나타난 target distribution의 비와 비례한다. 더 풀어서 기술한다면, 관측데이터를 이용해 error와 반비례관계를 가지도록 weight를 수정하고, 그 weight를 이용하여 새로운 proposal distribution을 가지는 particle을 생성시키는 것이다. 여기서 distribution은 통계적 표현이고, 통계적 기법을 의미하는 고상한(?) 용어는 Monte Carlo Method이다. 즉 컴퓨터는 수많은 random state를 발생시킬 수 있으므로 이 것을 사용하면, distribution 형태의 function을 구현할 수 있다. 이방법이 particle filter의 기본 개념이고 실제 사용은 앞서 적은 이론식에 비해 매우 간단한 개념이다. 필자가 이 블로그를 통해 수학을 강조하는 이유는 결국 대부분의 논문이나 기술은 수학적 표현을 사용하여 개념을 전달하고자 하며, 사실 가장 효과적인 수단이기 때문이다.
Particle filter를 이용한 위치 예측 예
Particle filter를 사용예를 보여주기 위해 움직이는 로봇이 주변의 4곳의 landmarks와의 거리를 측정하는 측정값을 사용하여 위치 및 방향을 예측하는 예를 들어 본다. 즉, 거리 측정값은 로봇의 위치를 정확히 나타내는 값이다. 일단 particles의 움직임을 로봇과 동일하게 움직여서 motion update (prediction)단계를 거친다. 이후 실제 측정치와 각 particle의 거리 측정치와의 오차를 이용하여 그 오차를 확률로서 표현한다. 즉, 실제치와 비슷한 거리를 보이는 particle에 대해서는 높은 확률을, 큰 차이를 보이는 particle에 대해서는 낮은 확률값을 내도록 한다.(실제치의 Gaussian distribution에서 particle의 거리를 입력하여 Gaussian 확률값을 얻어 내는 방법이다.) 이 확률값은 일종의 importance weight이며 높은 확률값을 가진 particle은 실제 로봇의 위치와 같을 확률이 높은 것으로 해석할 수 있다. 이러한 각 particle의 가중치를 이용하여, resampling과정을 통해 가중치가 높은 particle이 더 많이 선택이 되도록 다시 particle을 sampling하는 과정을 거친다. 이와 같은 과정이 measurement update과정으로 해석될 수 있으며, 실제 measurement를 이용하여 예측치의 정확도를 높이는 과정으로 설명할 수 있다. 실제 예측치는 particle의 위치 평균값을 사용하여 예측한다.
아래는 반시계방향으로 

1000개의 particle을 사용한 예측값으로 noise로 인해 매번 결과 값이 약간씩 다르지만 비교적 정확하게 그 위치를 예측하는 것을 알 수 있다.
