
본글은 Aylien의 블로그를 메인으로 하고 그외 다른 자료를 참조하여 작성되었다.
인공지능 연구가 지향하는 바는 인공지능이 스스로 우리가 사는 세상을 인식하고 이해하는 일일 것이다. 우리 인간이 할수 있는 일은 현재 수준의 인공지능의 관점에서 볼때 엄청난 능력을 갖고 있는 것이다. 단지 속도가 느리다는 것을 제외하고. 인간은 수많은 정보를 보유한 감각기관과 두뇌와 다른 생명기능을 이용하여 정보를 저장하고 처리하며 결정하고 행동한다. 이러한 능력을 가진 인공지능이 강한인공지능이고, general AI이고, 궁긍적으로 인공지능 연구자들이 개발하고자 하는 목표이다. 이러한 목표에 도달하는 방안으로 현재 주목받고 있는 기술이 generative models이다. 이 목표가 단지 시간의 문제인지, 아니면 기술의 한계에 부딫힐지 아직은 모른다. 그러나 결국은 정보처리능력면에서 스스로 정보에서 필요한 부분을 추출하고 가공하는 능력은 갖출것으로 기대된다. 이정도의 능력만으로도 수많은 일을 인공지능이 할 수 있다.
최근 generative models에 대한 관심이 다시 증가하고 있다. Generative modelling은 natural distribution을 가진 data P를 근사(approximate)할 수 있는 probabilistic model Q를 찾아내는 일이다. 보다 간단히 말한다면, 이 모델은 우리가 모델에 학습시킨 데이터와 비슷한 유형의 데이터를 창조해내는 방법이라고 설명할 수 있다.
실제로는, 이러한 데이터를 생성시키는 모델을 학습시키는 것은 쉽지 않은 일이다. 그러나, 최근에 들어 몇개의 방법들이 성공을 거두기 시작했다. 이러한 방법중 가능성이 큰 모델이 Generative Adversarial Networks (GANs)이다. 딥러닝분야의 유명한 연구자이자 Facebook의 AI research director인 Yann LeCun은 최근 GANs 이 딥러닝분야에서 가장 중요한 개발중의 하나라고 업급하였다.
Discriminative vs. Generative models
GANs를 살펴보기전에, generative 모델과 discriminative 모델간의 차이를 간단히 살펴보자.
- discriminative model은 input data (x)를 to class label (y)를 관계짖는 함수를 학습한다. 확률의 개념에서 보면, 이 모델은 확률분포 P(y|x)를 직접 학습하는 것이다.
- generative model은 input data와 labels의 joint probability, P(x, y),를 동시에 학습하려고 시도한다. 이 모델은 Bayes rule을 통해 classification을 위한 P(y|x) 함수로 전환될 수 있으나, generative기능은 새로운 (x, y) samples을 생성해 내는것과 같은 작업에 이용된다.
두 타입의 모델 모두 유용하나, generative models은 discriminative models에 비해 흥미로운 장점이 하나 있다. Generative model은 label이 없어도 입력 데이터의 내재된 구조를 이해하고 설명할 수 있는 가능성을 지니고 있다. label을 가지지 않은 데이터가 많고 label을 가진 데이터를 확보하는것이 비용이 드는것은 기본이고 불가능할 때도 있으므로, 현실적으로 data modeling문제를 다룰 때 매우 유용한 특성이다.
Generative Adversarial Networks
GANs는 2014년University of Montreal의 Ian Goodfellow research group이 처음으로 소개하였다. GAN의 메인 아이디어는 두 개의 서로 경쟁하는 neural network models을 사용하는 것이다. 이 중 한 모델은 input으로 noise를 사용해서 samples을 생성해 낸다. 그런 이유로 generator라고 한다. 다른 모델(discriminator라고 한다)은 generator와 training data로 부터 samples를 받아, 어디서 받은것인지 출처를 구분해 낸다. 이 두 networks는 연속적으로 게임을 하는데, generator는 더욱 실제적인 samples를 만들어 내도록 학습하고, discriminator는 generated data와 real data를 구분하는 능력이 갈수록 배양되도록 학습한다. 이 두 networks는 동시에 학습하고 두 모델간의 경쟁이 generated samples이 real data와 구분할 수 없을 정도에 이르길 바라는 것이다.

GAN overview. Source: https://ishmaelbelghazi.github.io/ALI
흔히 사용하는 비유로, generator는 위조품을 만드는 위조범이고, discriminator는 그 위조품을 감별하려고 노력하는 경찰로 비유된다. 이러한 setup은 reinforcement learning를 연상시키는데, generator는 자신이 생성한 데이터가 정확한지 아닌지에 대한 reward signal을 discriminator로 부터 받는다. GANs은 backpropagate gradient 정보를 discriminator로부터 generator network로 전달하여, generator가 discriminator가 구분불가능할만큼 output data를 생산해 낼 수 있을 정도로 generator의 패러미터들을 조절한다.
이 모델의 학습은 2 step을 거쳐 이루어 지는데, 먼저 discriminator만을 가지고 real sample data가 입력될 때 discriminator는 학습을 통해 real data일 경우에 해당하는 확률값을 출력으로 내도록 학습시키고, 두번째 step에서는 랜덤 노이즈(noise)를 사용하여 generator에 입력시켜 generator가 가짜 출력을 내도록 하고 이 출력은 discriminator에 입력 시킨다. 이번에는 가짜 입력에 의해 출력이 생성되었으므로 확률값은 0에 가까워야 discriminator가 제역할을 한것이다. 이와 관점에서 볼때, discriminator는 supervised learning의 binary classifier라고 할 수 있다.
여기서 흥미로운 점은 generator를 고려할때, generator는 최대한 real input이 입력되었을 때 발생하는 출력과 유사한 출력을 내도록 학습되어야 하므로, discriminator를 속이는 것이 목적이 되는 것이다. 이것은 game theory 상황과 유사하며, generator가 만족스럽게 학습이 되면 discriminator는 진짜 데이터와 가짜 데이터를 구분하지 못하므로 모든 경우에 0.5의 확률을 낼것이다. 그러므로 이 적대적인 게임은 discriminator에게는 local minimum이고 generator에게는 local maximum인 saddle point(말안장과 같은 모양의 objective function)에 수렴하게 된다.
GAN model
데이터 x에 대한 generator distribution Pg를 학습하기위해, 사전에 input noise variable Pz(z)를 정의하고, generator data space G(z;Θg)로 매핑한다. 이와 함께 discrminator D(x;Θd)를 정의 한다. D(x)는 x가 training data일 확률을 의미한다. Training example에 해당하는 label과 G로부터 얻는 noise variable sample의 결과물에 해당하는 label을 옳바로 맞추는 확률을 최대화하도록 D를 학습시키고, 동시에 log(1-D(G(z)))를 최소화 시키도록 G를 학습시킨다. 다시 풀이하면, D와 G는 value function V(G, D)를 이용하여 아래와 같은 two-player minimax game을 수행하는 것이다.
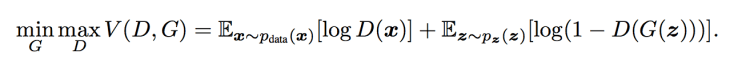
위의 설명은 수학적 용어와 기호를 사용하여 GAN 이론을 표현한 것이다. 논문의 저자는 GAN을 위한 algorithm을 아래와 같이 제시하였다.

Approximating a 1D Gaussian distribution
Goodfellow의 GAN paper에는 이해를 돕기위해 그림으로 GAN model이 traing되는 과정을 설명하였다.

GAN이 어떻게 동작하는지 이해하기 위해 Tensorflow로 coding된 간단한 예를 Eric Jang의 blog post에서 찾아 볼 수 있다. 여기서는 위조범과 은행원(teller)를 들어 비유로 이 모델을 설명하고 있다. 지폐에는 식별을 위해 고유의 숫자 X를 사용하는데, 이 숫자는 Pdata인 density function을 가진 probability distribution에서 추출해낸 숫자이며, 지폐를 발행하는 조폐국만 알고 있고 은행원이나 위조범은 알지 못하는 상황이다. 위조범의 목표는 Pdata에서 x’ samples을 생성시키고 위폐를 만들어 은행원이 진폐와 구분 못하게 하는 것이다.
이것이 좋은 예는 아니지만, 불법 복제품의 serial number는 제품 등록시 진품의 serial number와 다른 규칙에 의해 작성되어 있으므로 등록이 불가능 할 것이다. 만약, generative model이 학습을 통해 진품과 같은 규칙을 가지고 진품과 구분이 불가능한 serial number를 생성가능하다면, 이것이 불법 복제품을 만드는 사람의 목표가 된다. 본문에 언급한 비유에서 density function은 이 비유의 serial number규칙과 같은 역할을 한다.
위조범은 이를 위해 여러가지 basis function들의 조합으로 만들어진 연속함수(continuous function)를 고안해야 하는데, 이 함수를 만드는 도구로서, neural network basis, Fourier basis, 또는 다른 basis를 사용하여 universal approximator를 만들어 내야 한다.
여기서는 1-dimensional Gaussian distribution을 학습하는 것을 예로 들었다. 먼저 mean값이 4이고 표준편차가 0.5인 Gaussian 분포를 가진 “real” data distribution을 generator model이 흉내내도록 학습시키는 것이다. “real” data를 생성시키는 python code와 가우시안 분포은 아래 그림과 같다.
class DataDistribution(object):
def __init__(self):
self.mu = 4
self.sigma = 0.5
def sample(self, N):
samples = np.random.normal(self.mu, self.sigma, N)
samples.sort()
return samples

다음으로는 input noise를 생성시킨다. 아래 code를 보면 구간에 일정한 간격으로 N개의 노이즈를 생성시킨후 그 값에 임의의 값으로 가감시키는것을 알 수 있다(stratified sampling이라고 한다). 이와 같이 하지 않았을 경우, 학습을 하지 못한다고 밝히고 있다.
class GeneratorDistribution(object):
def __init__(self, range):
self.range = range
def sample(self, N):
return np.linspace(-self.range, self.range, N) + \
np.random.random(N) * 0.01
Generator 및 discriminator networks는 매우 간단한데, generator의 경우에는 input을 linear transformation한 후 softplus function을 사용 nonlinear 값으로 transform을 거치고, 마지막으로 다시한번 linear transformation을 하는것을 알 수 있다.
def generator(input, hidden_size):
h0 = tf.nn.softplus(linear(input, hidden_size, 'g0'))
h1 = linear(h0, 1, 'g1')
return h1
이 예시의 경우 discriminator의 모델은 generator에 비해 더 성능이 좋아야 하는데, 그렇지 않으면 real samples과 generated samples을 구분할만한 능력을 학습할 수 없기 때문이라고 한다. 그러므로, 아래 code와 같이 discriminator의 경우에는 neural network의 심도가 깊어지고(deeper), size도 크다. 확률을 내야하는 마지막 layer에서 sigmoid() 함수를 사용한 것을 제외하고는, 앞쪽 layer에서는 모두 tanh() 함수를 사용하였다.
def discriminator(input, hidden_size):
h0 = tf.tanh(linear(input, hidden_size * 2, 'd0'))
h1 = tf.tanh(linear(h0, hidden_size * 2, 'd1'))
h2 = tf.tanh(linear(h1, hidden_size * 2, 'd2'))
h3 = tf.sigmoid(linear(h2, 1, 'd3'))
return h3
Tensorflow가 사용되기 때문에, 위에 정의한 class나 function을 integration시키도록 tensorflow graph가 생성될 것이다. 이와 더불어 각 network의 학습을 위해 loss function이 각각 정의 되어야 하는데, 목적은 앞서 설명한 바와 같이 generator가 discriminator를 속이는 것이다.
with tf.variable_scope('G'):
z = tf.placeholder(tf.float32, shape=(None, 1))
G = generator(z, hidden_size)
with tf.variable_scope('D') as scope:
x = tf.placeholder(tf.float32, shape=(None, 1))
D1 = discriminator(x, hidden_size)
scope.reuse_variables()
D2 = discriminator(G, hidden_size)
loss_d = tf.reduce_mean(-tf.log(D1) - tf.log(1 - D2))
loss_g = tf.reduce_mean(-tf.log(D2))
마지막으로 optimizer를 정의하고 training을 시키면 generator는 real input data의 distribution과 유사하도록 학습하게 된다.
Eric Jang의 블로그에서는 discriminator와 generator의 model은 11개의 hidden unit으로 이루어진 3개의 layer로 이루어진 perceptrons을 사용하였다. 하지만, discriminator와 generator모두 같은 구조의 모델을 사용하는 것은 좋은 방법이 아닐 수 있다. Aylien의 방법처럼, 서로 다른 모델을 사용하면서, discriminator는 확률값을 내야 하므로 sigmoid activation을 사용하는 것이 보다 합리적으로 생각된다. 물론, 결과를 비교해 보면 Aylien의 방법이 더 좋은 결과를 낸다. real data distribution은 mean값이 -1이고 표준편차가 1인 Gaussian 정규분포에 따르며, noise distribution은 (0, 1)구간의 uniform distribution을 가진다. 그러므로, 이러한 probability density function을 가지고, generator의 출력이 Pdata(X)가 되도록 학습시키는 것이 목표가 된다.
반면, discriminator는 입력 x를 받아, 이 입력값이 확률분포 Pdata(X)에 따라 나온 값인지에 대한 확률값을 계산해 낸다. 이 경우 훌륭한 discriminator(은행원)는 generator에서 생성된 데이터는 진짜가 아니라는 확률값을 내고, real data distribution에서 생성된 데이터는 진짜라는 확률값을 내야한다. 이를 평가하는 loss function은 상기 마지막 code snippet에 나타나 있다.
Eric Jang은 몇가지 tip을 언급하였는데, 학습을 위한 training을 위해 noise의 sampling은 stratified sampling을 사용하였고, discriminator를 사전에 training하면 빠른 학습속도를 보인다고 한다. 또한, 너무 많은 패러미터를 사용하면 수렴에 실패하며, ReLU unit보다는 tanh() unit이 바람직하다고 한다. learning rate도 조절해야 했다고 한다.
GAN 모델이 natural images를 생성하는데 사용된 예가 논문에 예시되었는데, 기존의 이미지 생성 알고리즘에 비해 성능이 우수하다고 할수는 없지만, 모델이 발전되면 더 좋은 결과를 얻을 수 있을것이라는 전망이 언급되어 있다.

그러한 예측이 적중하여, convolutional networks를 사용하는 등 이미지와 관련하여 사용하는 GAN 모델이 발전하여 왔으며, 현재는 꽤 선명한 이미지 생성이 가능한 수준에 이르렀다. 이에 관해서는 별도로 포스팅할 예정이다.
GAN과 관련하여 참조자료를 아래에 링크하였다.
