
본글은 Hugo Larochelle(Tweeter, Inc.)의 Neural Networks강의를 요약/재해석한 것이다.
Neural Network를 이해하기 위해서는 NN의 perceptron이라고 불리우는 기본 구조에 대한 이해로 부터 시작해야 한다. Perceptron은 여러개의 binary input을 입력으로 받고 하나의 binary output을 생성하는 구조로 되어 있다. 이 perceptron의 기능은 weights 도입을 시작으로 수행된다. weights는 입력과 출력과의 관계를 선형적으로 나타내는 패러미터이며 각 입력이 출력에 미치는 영향의 크기를 의미한다. 입력치들의 가중합계(weighted sum)이 기준치(threshold)보다 크거나 작음에 따라 다른 output을 낸다. Perceptron은 출력이 0/1과 같이 이산변수이지만, 신경망에 사용되는 single neuron은 perceptron의 개념을 그대로 차용하되, 출력은 bounded real number이다. 마치 두뇌의 뉴런에서 신경신호가 on/off(binary discrete variable) 신호보다는 연속변수(continuous variable)에 까깝기 때문이다.


이와 같은 perceptron(single neuron)이 두뇌의 신경망처럼 서로 연결되어 있는 구조를 모방해보면 아래 그림처럼 여러개의 neuron이 순차적으로 연결된 구조를 상상해 볼 수 있다. 각 층(layer)에는 많은 수의 neuron을 둘 수 있으며, 일반적으로 layer당 neuron이 많을 수록 더 정교한 모델을 만들 수 있다. 인공지능의 신경망은 대부분 이러한 간단한 구조를 기반으로 구축된다. 첫번째 layer의 neuron은 겉보기에 perceptron과 다른 형태로 보이는데, 출력이 하나가 아니라 여러개 처럼 보이지만, 실은 출력이 여러개의 값을 가지는것이 아니라 하나의 출력값만 가지며, 단지 그 출력값이 후속 뉴런들 모두에 연결되어 있다는 것을 나타낸다. 신경망에 포함되어 있는 단일 뉴런은 같은 layer내에서는 서로 독립적이며, 후속 layer(또는 출력)에 포함된 뉴런에 신호를 전달해 주는 역할만 수행한다.
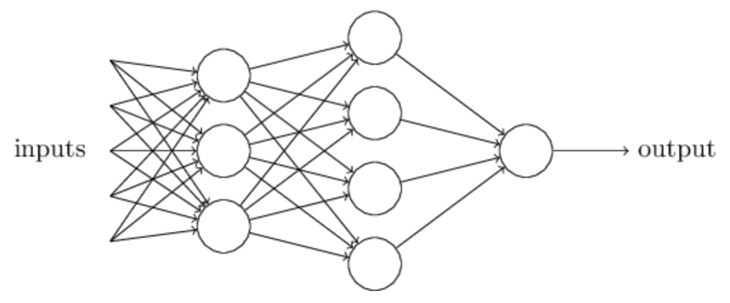
아래 그림은 위에 설명한 신경망의 수학적 표현이다. NN가 역할을 수행하려면 수학의 힘을 통해 프로그래밍되어야 하므로 기본적 linear algebra를 사용해 나타낸다. 수식에서 bias는 각 뉴런마다 하나씩 추가되고, 연산값을 절대치를 보정하는 역할을 한다. Activation function은 neuron 자체를 흉내낸것이며, 이것의 역할은 bias와 weights를 통해 연산된 값을 변환하고 변환된 값을 후속 뉴런이나 출력을 생성하는 뉴런의 입력값을 만드는 일이다. Neuron activation 값을 hypothesis라고도 한다.
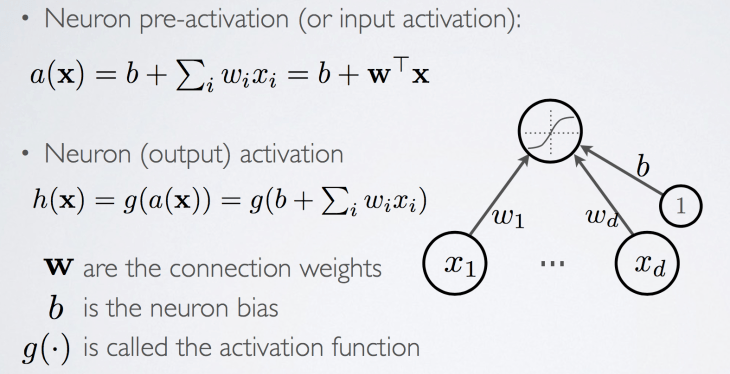
수많은 뉴런의 연결을 수식으로 표현하려면 Scalar 변수는 모두 벡터나 매트릭스(matrix) 또는 다차원 텐서(tensor)로 표현해야(이를 vectorize한다고 부른다) 수식이 그야말로 깔끔해진다. 실제 프래그래밍할때 벡터나 매트릭스 연산을 통해 연산을 수행해야 code가 간단해지고 연산속도도 빨라진다. Scalar 변수를 사용하고 loop 구조를 사용하는 알고리즘은 많은 연산시간과 연산속도가 필요한 인공지능 학습에 사용하면 비효율 그 자체가 될것이다.
위에 언급한 activation function은 여러 종류가 있는데, NN에서 주로 사용하는 activation function은 sigmoid function(σ), hyperbolic tangent function(tanh), rectified linear unit function(ReLU)이 있다. Pre-activated된 값을 그대로 전달하는 것을 activation function으로 나타내려면 linear function으로 표현할 수 있지만, 신경망 연구에서는 사용하지 않는다. Activation function은 wiki를 참조하기 바라며, 각 activation function의 출력 값의 구간(lower bound, upper bound)에 주의해야 한다. 이와 더불어 여러개의 최종 출력값을 원할 경우(예를 들어, multi-class classification), softmax activation function을 주로 사용한다. 출력값들이 합은 1이며, 각 항목은 일반적으로 확률값을 의미한다.
여러개이 hidden layer가 있는 neural networks를 수식과 함께 표현하면 아래 그림과 같다. 기본 구조의 연장이므로 확장해서 해석하면 되나, hidden layer가 여러개다 보니 수식에 위첨자를 사용하여 layer를 구분한다.

이와 같이 구조화된 신경망으로 연산을 수행하는 경우, 입력값들이 어떤 형태로 변화를 거쳐 출력값들을 생성해 내는지에 대해 잘 묘사된 그림이 아래에 실었다. 아래는 하나의 hidden layer를 사용한 것이지만 각 layer에서의 neuron의 수를 늘리고 hidden layer의 수를 늘리면, 기술적으로 어떠한 형태의 함수도 표현해 낼 수 있다. 이것을 Kurk Hornik의 universal approximation theorem이라고 한다.
‘‘a single hidden layer neural network with a linear output unit can approximate any continuous function arbitrarily well, given enough hidden units’’
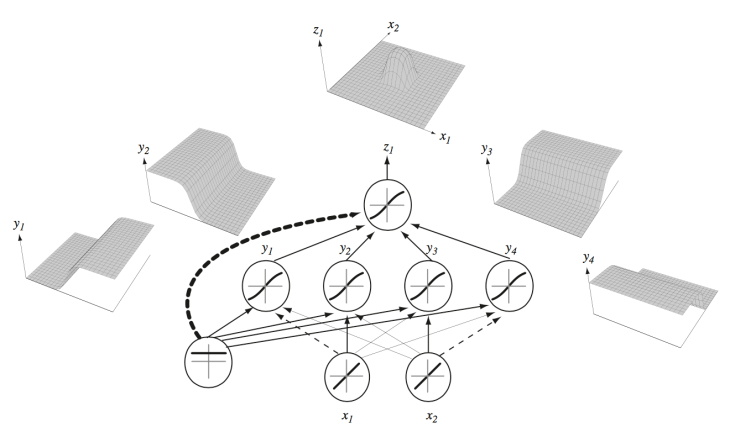
NN을 통해 어떠한 형태의 함수라도 표현해 낼 수 있다고 해서, 어떤 것도 학습이 가능하다는 의미는 아니다. 수학적인 함수를 흉내내기 위해 NN이 사용된다면, 기존의 수학적 기법을 대체할 이유가 전혀 없다. 수학적 함수로 표현하기 힘든것에 강점을 보이기 때문에, NN가 사용되는 이유이다. 사물을 보고(이미지 정보를 가지고) 그것이 고양이인지 강아지인지 알아내는 것을 수학적인 함수로 표현하기가 쉬운일이 아니지만, NN에게는 매우 쉬운 일이다. 반면에, NN는 학습된 영역에서는 강점을 보이지만 과학적 추론이나 수학을 통해 새로운 사실이나 법칙을 알아내는 일은 현재로선 불가능 하다. 과학의 강점은 학습된적 없는 또는 경험해보지 못한 것들에 대해서도 예측가능하다는 점에 있다. 학습되지 않는 것에 대한 고차원적인 지력을 펼치는 일(창조의 영역)은 아직까지 인간의 영역이며, general artificial intelligence가 추구하는 궁극의 목표중 하나이다. 강한 인공지능은 이러한 인간의 영역에 도달한 인공지능을 의미하며, 발단된 인공지능이 인간이 가지는 감정을 가질수 있느냐는 별개의 문제이고, 단지 기술적 측면만의 얘기가 아님은 분명하다.
Machine learning의 학습과정은 아래와 같이 함수를 최소화하는 parameter(Θ)를 찾는 과정으로 축약할 수 있다.
아래 수식이 의미하는 바를 정확히 이해하지 못하면, 이론적 학습에 적지 않은 영향을 미치므로, 시간을 내서 linear algebra를 포함하여 수식을 이해하는 능력을 갖추는게 바람직 하다. 특히 ML관련 논문(paper)나 code를 볼때면 수학적 지식이 반드시 필요하다. 학창시절 어디에 쓸지 모르는 수학을 열심히 공부한 이유는 바로 이런 부분에 있다. 물론, 수학적 이론적 기반이 부족하더라도 학습이 가능하나 아무래도 한계가 있다.

ML학습과정은 objective function을 minimize시키는 parameter(Θ)를 찾아내는 과정으로 optimization(최적화)작업이라고 할 수 있다. Optimization분야는 응용측면에서 다른 분야에서 많이 사용하고 이론적으로 연구가 많이 된 부분이며, ML에 사용하는 최적화 알고리즘은 기존 알고리즘을 약간 번형하여 사용한다. ML의 최적화 기법중 가장 많이 사용하는 기법이 SGD(Stochastic Gradient Descent)이다. SGD 알고리즘은 아래와 같이 요약될 수 있다. SGD의 핵심은 loss function에 대한 미분(gradient)를 구하는 것이고, gradient가 구해지면 아래 식을 이용하여 우리가 원하는 parameter(Θ) 값을 찾아 낼 수 있다. 패러미터 update는 미분(gradient을 구하기 위해)에 대한 지식이 필요하지만, gradient는 옳바른 패러미터를 찾아가는 방향성을 제시한다고 생각하면 된다. Δ 앞에 있는 α는 learning rate라고 하며, regularizer 항목에 있는 λ와 같이 hyper parameter이다. learning rate는 학습속도와 학습 안정성과 관련이 있고, λ는 regularization하는 강약을 조절하여 overfitting을 감소시키므로, 예측 능력의 일반화에 기여한다.


Loss function은 supervised learning의 label과 NN이 예측한 label과의 오차를 수치로 나타내는 함수이므로 이 loss function을 정의하는 과정이 필요하다. 또한 기계학습의 핵심은 신경망의 구성과 구성된 신경망에서 도입된 패러미터에 대한 loss function의 gradient를 구하는 과정이므로, 이 gradient를 구하는 과정이 필요하다. 위 식에서 신경망구조의 수학적 표현은 f(x(t);Θ)이다. 구축된 신경망이 주어진 training data에 overfitting되는 것을 방지하기 위해 사용하는 것이 regularizer이며, 이것을 정의하는 것도 역시 필요하다.
Loss function은 최적화의 objective function이라고 할 수 있는데, 최적화에서 가장 기본적인 objective function은 squared error(regression에 주로 사용하는 least square method)방법과, negative log-likelihood(cross-entropy method라고도 한다)방법이다. 두 방법의 수학적 의미는 어려운것이 없으니 기계학습에 중요한 만큼 완전히 파악해야 한다. 왼쪽 식의 의미는, 신경망 예측치(y)가 sample의 label인 C와 같을 확률(probability)이다


여기까지 neural networks에 대한 기본적 구조와 기능에 대한 설명이었다. 그러나 기술적으로 가장 중요한것이 남아 있는데, 그것은 loss function에 대한 각 패러미터의 gradient를 구해내는 일이다. 이 방법으로 backpropagation을 많이 사용하는데, 모든 것을 coding하지 않는다면, 수학적 방법을 알 필요는 없다. 사실, deep learning frameworks에서는 이것을 신경쓰지 않아도 deep learning을 구현하는데 어려움이 없다. 그러나 그 방법을 아는것은 훌륭한 source code를 이해하는데 도움이 될뿐 아니라, 신경망 연구에도 반드시 필요하다. Recurrent Neural Networks에서는 BPTT (Back Propagation Through Time)과 같은 방법으로 gradient를 구한다. 이와 관해서는 개인적으로 수학적으로 유도를 해보고 그 방법을 이해하는 수준이다. 시간이 되면 이에 대해 별도로 정리할 계획이다.
